Закрытие сайта на платформе DLE от индексации поисковыми системами – важный шаг для владельцев, которым нужно временно скрыть контент или предотвратить его попадание в результаты поиска. Это может быть необходимо при разработке нового сайта, а также если требуется защита конфиденциальности информации. В этой статье рассмотрим конкретные шаги, которые помогут вам добиться этой цели.
Для начала стоит разобраться, какие инструменты предоставляет DLE для управления индексацией. Одним из наиболее эффективных методов является настройка файла robots.txt, который сообщает поисковым системам, какие страницы они могут индексировать, а какие нет. Важно правильно настроить этот файл, чтобы исключить не только главную страницу, но и все внутренние ссылки, если это требуется.
Также стоит обратить внимание на настройку метатегов в <head> части страниц. Использование метатега noindex позволит задать директиву для поисковых систем на уровне каждой отдельной страницы. Такой подход удобен, если вам нужно заблокировать индексацию лишь части контента, а не всего сайта.
Помимо технических решений, важным аспектом является настройка прав доступа на сервере. Если вы хотите заблокировать индексацию для всего сайта, можно настроить доступ к определённым разделам через .htaccess или другие серверные конфигурации. Этот метод эффективен, но требует внимания к деталям, чтобы избежать случайных ошибок, которые могут привести к непредсказуемым последствиям.
Настройка файла robots.txt для запрета индексации
Файл robots.txt используется для управления доступом поисковых систем к определённым частям сайта. Для того чтобы запретить индексацию, необходимо правильно настроить этот файл и указать в нём соответствующие директивы. Важно отметить, что хотя большинство поисковых систем уважают настройки robots.txt, это не гарантирует полную защиту от индексации, так как некоторые системы могут игнорировать этот файл.
Чтобы закрыть сайт от индексации поисковыми системами, достаточно создать или отредактировать файл robots.txt и добавить следующие строки:
User-agent: * Disallow: /
User-agent – указывает на поискового робота. Символ «*» означает, что настройка применяется ко всем поисковым системам. В случае, если нужно запретить индексацию только конкретной поисковой системе, можно заменить «*» на название её робота, например, Googlebot для Google.
Disallow – указывает, какие части сайта не должны индексироваться. Символ «/» означает весь сайт. В данном случае все страницы будут исключены из индексации.
Для более гибкой настройки можно использовать различные параметры. Например, если вы хотите запретить индексацию только определённых папок или файлов, это делается следующим образом:
User-agent: * Disallow: /private/ Disallow: /tmp/
Если необходимо разрешить индексацию конкретных разделов, то используйте директиву Allow. Например, если вы хотите закрыть весь сайт, кроме страницы с контактами:
User-agent: * Disallow: / Allow: /contacts.html
Для улучшения контроля над индексацией можно также использовать директивы Crawl-delay (для установки задержки между запросами робота) и Sitemap (для указания местоположения карты сайта). Пример:
User-agent: * Disallow: / Crawl-delay: 10 Sitemap: https://example.com/sitemap.xml
Важно помнить, что директивы robots.txt действуют только для тех поисковых систем, которые их поддерживают. Чтобы дополнительно защитить страницы от индексации, можно использовать мета-тег <meta name=»robots» content=»noindex»> или заголовки HTTP с соответствующими инструкциями.
Использование мета-тегов для блокировки поисковых систем
Для ограниченной индексации или полной блокировки сайта от поисковых систем можно использовать мета-тег <meta name="robots">. Этот тег позволяет точно указать поисковым роботам, какие действия они могут выполнять на страницах вашего ресурса.
Чтобы предотвратить индексацию страницы, необходимо добавить мета-тег с атрибутом content="noindex" в разделе <head> HTML-документа. Пример:
<meta name="robots" content="noindex">
Этот тег запрещает поисковым системам индексировать содержимое страницы, но не блокирует возможность следовать по ссылкам на ней. Чтобы также запретить следование по ссылкам, добавляется параметр nofollow:
<meta name="robots" content="noindex, nofollow">
В случае, если нужно запретить индексацию всего сайта, мета-тег можно добавить на главную страницу или в шаблон, который будет применяться ко всем страницам. Для этого используются параметры noindex, nofollow в теге <meta> на каждой странице. Это эффективно для закрытия сайта от поисковиков, не влияя на внутренние ссылки и навигацию.
Если необходимо, чтобы страницы не индексировались, но оставались доступными для анализа ссылок, используйте параметр noindex, follow. Это запретит индексацию, но позволит поисковикам отслеживать ссылки на других ресурсах:
<meta name="robots" content="noindex, follow">
Для оптимальной работы мета-тегов, важно корректно их размещать в разделе <head> каждой страницы. Несоблюдение этого правила может привести к тому, что поисковые роботы не смогут корректно обработать ваш запрос.
Помимо мета-тега robots, для дополнительных ограничений индексации можно использовать другие методы, такие как robots.txt или директивы в HTTP-заголовках, но мета-теги остаются самым гибким и простым способом контроля индексации на уровне отдельных страниц.
Как настроить заголовки HTTP для отключения индексации
Для того чтобы предотвратить индексацию сайта поисковыми системами, можно использовать специальную настройку заголовков HTTP. Это решение позволяет управлять доступом к сайту и контролировать, какие страницы могут быть проиндексированы, а какие нет. Основные механизмы для отключения индексации через HTTP-заголовки включают использование заголовков X-Robots-Tag и Cache-Control.
В отличие от мета-тегов robots, настройка заголовков HTTP дает возможность более точно контролировать индексацию, особенно на уровне серверных ресурсов (например, PDF-документов или изображений).
1. Использование заголовка X-Robots-Tag
Заголовок X-Robots-Tag позволяет указать поисковым системам, что страницы не должны индексироваться. Это может быть полезно, если необходимо отключить индексацию определенных файлов, таких как PDF или другие ресурсы, которые не содержат мета-теги.
- Пример: заголовок
X-Robots-Tag: noindexуказывает поисковым системам не индексировать страницу или ресурс. - Пример для исключения индексации всех страниц:
X-Robots-Tag: noindex, nofollow. - Также можно указывать правила для отдельных типов контента, например:
X-Robots-Tag: noarchiveдля предотвращения кэширования.
Чтобы настроить заголовок X-Robots-Tag, нужно добавить его в конфигурацию сервера. В Apache это можно сделать в файле .htaccess:
Header set X-Robots-Tag "noindex, nofollow"
Для Nginx настройка будет выглядеть следующим образом:
add_header X-Robots-Tag "noindex, nofollow";
2. Заголовок Cache-Control
Заголовок Cache-Control позволяет управлять кэшированием контента, что важно для предотвращения сохранения страниц в кэшах поисковых систем. Для отключения индексации важно указать, чтобы страница не кэшировалась и не попадала в индекс.
- Пример для полной блокировки кэширования:
Cache-Control: no-store. - Для более гибкого управления можно использовать
Cache-Control: no-cache, что запрещает кэширование, но позволяет серверу повторно запрашивать ресурс.
Для Apache добавьте в файл .htaccess следующую строку:
Header set Cache-Control "no-store"
Для Nginx настройка будет выглядеть так:
add_header Cache-Control "no-store";
3. Комбинированная настройка для полного отключения индексации

Для более точного контроля индексации можно комбинировать оба заголовка, X-Robots-Tag и Cache-Control, чтобы полностью исключить страницу из индексации и кэширования. Например:
Header set X-Robots-Tag "noindex, nofollow" Header set Cache-Control "no-store"
Эти настройки позволят поисковым системам не индексировать страницу, а также не хранить ее в своем кэше, что гарантирует полное исключение из поиска.
Ограничение доступа к сайту с помощью .htaccess
Для ограничения индексации сайта поисковыми системами можно использовать файл .htaccess. Этот файл позволяет настроить доступ к различным частям сайта и применить правила, которые будут касаться только сервера. Важно понимать, что при правильном использовании .htaccess можно эффективно блокировать доступ к сайту для поисковых роботов и других нежелательных посетителей.
Ниже приведены несколько методов использования .htaccess для ограничения индексации и доступа к сайту:
- Запрет индексации для всех поисковых систем: Чтобы заблокировать доступ всех поисковых роботов к сайту, добавьте в файл .htaccess следующий код:
SetEnvIf User-Agent "Googlebot" dontlog SetEnvIf User-Agent "Bingbot" dontlog SetEnvIf User-Agent "Yandex" dontlog SetEnvIf User-Agent "Slurp" dontlog SetEnvIf User-Agent "DuckDuckBot" dontlog CustomLog logs/access_log common env=dontlog
Этот код использует переменную окружения, которая идентифицирует поисковых роботов. Правила запрещают им доступ, и их действия не фиксируются в логах сервера.
- Запрет индексации для конкретных страниц или разделов: Чтобы ограничить доступ к определённым частям сайта, например, закрытым разделам или папкам, можно использовать следующий код:
RewriteEngine On RewriteCond %{REQUEST_URI} /закрытый-раздел/ RewriteRule ^ - [F,L]
Этот код блокирует доступ к каталогу или разделу сайта. При попытке посетить этот ресурс, сервер откажет в доступе, и пользователю будет показана ошибка 403.
- Запрет индексации с помощью заголовков HTTP: Другим вариантом является использование директивы Headers для отправки заголовков, которые сообщают поисковым системам, что страницы не должны индексироваться:
Header set X-Robots-Tag "noindex, nofollow"
Этот код сообщает поисковым системам, что страница не должна быть проиндексирована и что ссылки на ней не следует следовать. Это эффективно для блокировки индексации всего сайта или отдельных страниц.
- Блокировка доступа по IP-адресам: Для защиты сайта от определённых пользователей можно ограничить доступ на уровне .htaccess по IP-адресам. Пример:
Order Deny,Allow Deny from all Allow from 192.168.1.1
Этот код заблокирует доступ ко всем IP-адресам, кроме указанного. Можно настроить список разрешённых или запрещённых адресов, в зависимости от потребностей.
- Запрет доступа для поисковых систем через robots.txt: Помимо .htaccess, важно использовать файл robots.txt для конкретных настроек поиска. Он размещается в корневой папке сайта и управляет поведением роботов, указывая, какие страницы или разделы не следует индексировать. Пример:
User-agent: * Disallow: /закрытый-раздел/
Вместо того чтобы просто запрещать индексацию через .htaccess, сочетание этого метода с robots.txt дает полный контроль над поведением поисковых систем.
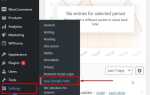
Как скрыть страницы DLE с помощью настроек в админке
Для того чтобы скрыть страницы сайта DLE от индексации поисковыми системами, можно использовать встроенные настройки в админке. Важно знать, что это решение не требует вмешательства в код сайта, достаточно правильной настройки через интерфейс администрирования.
1. Использование настроек в разделе «Настройки» админки
Перейдите в админку DLE и откройте раздел «Настройки». Здесь есть опция «Запрещать индексацию страниц», которая позволяет полностью заблокировать индексацию всех страниц сайта. Включив эту настройку, вы указываете поисковым системам не индексировать контент сайта. Это глобальная настройка, применимая ко всему сайту.
2. Добавление мета-тегов для отдельных страниц
Чтобы скрыть от индексации только конкретные страницы, в DLE можно добавить мета-тег noindex на уровне контента. В редакторе материалов на странице редактора поста найдите поле для ввода мета-тегов и вставьте следующее:
<meta name=»robots» content=»noindex, nofollow»>
Этот мета-тег сообщает поисковым системам, что данная страница не должна индексироваться и ее ссылки не должны учитываться в расчете рейтинга.
3. Применение к отдельным категориям и тегам
В админке DLE можно ограничить индексацию не только для страниц, но и для целых категорий. Для этого в настройках категорий включите параметр «Не индексировать». После этого все страницы, связанные с этой категорией, не будут попадать в поисковые системы.
Для добавления тега на страницы, которые не должны индексироваться, используйте аналогичные мета-теги в настройках каждой страницы, чтобы управлять видимостью контента.
4. Использование robots.txt
Еще один способ блокировки индексации – использование файла robots.txt. В этом файле можно прописать правила, запрещающие индексацию отдельных страниц или разделов сайта. Пример:
User-agent: *
Disallow: /private/
Этот файл необходимо разместить в корневой директории сайта, и он будет автоматически учитываться всеми поисковыми системами.
Таким образом, DLE предоставляет различные способы для скрытия страниц от поисковых систем, включая использование настроек в админке, мета-тегов, а также настроек файла robots.txt.
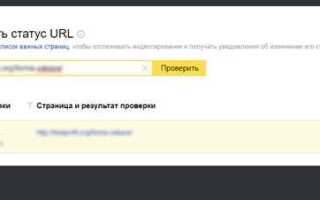
Удаление сайта из индексации через инструменты Google Search Console
Чтобы удалить сайт из индексации поисковой системы Google, необходимо использовать инструмент «Удаление URL» в Google Search Console. Это действие может быть полезно, если требуется временно исключить страницы или целые разделы сайта из поиска. Процесс удаления сайта из индексации состоит из нескольких шагов.
1. Добавление и подтверждение прав на сайт
Прежде чем начать удаление, убедитесь, что сайт добавлен в Google Search Console, и у вас есть права администратора. Если сайт не подтвержден, выполните процедуру добавления с помощью метода проверки (например, через HTML-файл или тег в коде страницы).
2. Переход в инструмент «Удаление URL»
После авторизации в Google Search Console откройте вкладку «Индексирование» в меню и выберите инструмент «Удаление URL». Этот инструмент позволяет не только удалить отдельные страницы, но и ограничить доступ к целым разделам сайта.
3. Запрос на удаление URL
Нажмите на кнопку «Новый запрос» и введите адрес страницы или пути, которые необходимо удалить. Система предложит несколько вариантов удаления, например, временное исключение (на 6 месяцев) или полное удаление с индексации.
4. Проверка состояния запроса
После отправки запроса в Google Search Console отобразится статус обработки. Важно следить за уведомлениями, чтобы убедиться, что запрос был успешно выполнен. Если статус запроса не изменяется или возникает ошибка, проверьте правильность введенного URL.
5. Использование мета-тегов или файлов robots.txt
Если требуется перманентное исключение страниц, используйте мета-тег «noindex» в коде страницы или настройте файл robots.txt. Однако, если вы хотите только временно исключить страницы, лучше воспользоваться инструментом Google Search Console, так как он действует быстрее и не требует изменений в коде сайта.
6. Рекомендации для постоянного удаления
Если задача заключается в постоянном исключении страницы или сайта из поискового индекса, после временного удаления с помощью Google Search Console, добавьте мета-тег «noindex» или настройте robots.txt для этих страниц. В случае если весь сайт больше не должен быть индексируемым, можно воспользоваться настройками на сервере для блокировки поисковых систем.
Важно помнить, что изменения в индексации могут занять некоторое время, и процесс удаления не является мгновенным. Google периодически обновляет свою базу данных, поэтому результат может проявиться через несколько дней или недель.
Закрытие сайта для поисковиков через настройку SEO-плагинов DLE
Первый шаг – это использование плагина «DLE SEO», который позволяет быстро и гибко управлять метатегами и директивами для поисковых систем. Чтобы закрыть сайт от индексации, достаточно внести изменения в настройки плагина. В частности, нужно установить директиву noindex на всех страницах сайта.
Для этого откройте настройки плагина «DLE SEO» в админ-панели сайта и перейдите в раздел, отвечающий за метатеги. В поле, которое отвечает за теги robots, добавьте параметр noindex, nofollow. Это гарантирует, что поисковые роботы не будут индексировать страницы, а также не будут следовать по внутренним ссылкам.
Если вы хотите закрыть только определённые страницы, например, административные или временные, вы можете добавить исключение для этих страниц. Для этого в настройках плагина нужно указать URL-адреса страниц, которые должны быть исключены из индексации, и для них будет добавлен метатег noindex.
Кроме того, на уровне конфигурации можно использовать файл robots.txt, который работает в связке с SEO-плагинами. Для этого в корне сайта создайте или отредактируйте файл robots.txt и добавьте следующие строки:
User-agent: * Disallow: /
Эта настройка полностью блокирует доступ поисковиков ко всем страницам вашего сайта. Если нужно исключить только часть страниц, укажите их пути в разделе Disallow.
Также стоит помнить, что использование плагинов DLE позволяет гибко настраивать индексацию не только для всего сайта, но и для отдельных разделов. Например, можно закрыть от индексации страницы с низким качеством контента или тестовые страницы, добавив директиву noindex в нужные шаблоны или отдельные материалы.
Важным аспектом является правильное использование плагинов и их совместимость с другими настройками DLE. Перед изменениями всегда рекомендуется протестировать настройку на нескольких страницах, чтобы убедиться в корректной работе индексации.
Контроль за индексацией с помощью настройки канонических ссылок
Для настройки канонических ссылок необходимо добавить в код страницы тег <link rel="canonical" href="URL"> в секцию <head>. В значение атрибута href следует указать ссылку на оригинальный источник контента. Это поможет избежать ситуаций, когда поисковые системы индексируют не ту версию страницы, например, с параметрами в URL или дублями контента.
Применение канонических ссылок на сайте DLE особенно важно, если сайт содержит страницы с похожим или дублированным контентом (например, разные фильтры поиска или страницы с несколькими параметрами в URL). Канонический тег сообщает поисковым системам, что эти страницы не являются уникальными и что на индексировании должна быть сосредоточена только оригинальная версия.
Рекомендуется использовать канонические ссылки на страницах с фильтрами, пагинацией, дублированными постами, а также в случае использования URL-параметров. Например, если есть несколько страниц с одинаковым контентом, но различающихся по параметрам URL (например, сортировка или фильтрация товаров), каноническая ссылка должна указывать на основную страницу без этих параметров.
Важно: неправильно настроенная каноническая ссылка может привести к неправильной индексации и снижению видимости сайта в поисковых системах. Канонический тег должен указывать на самую релевантную и важную страницу, а не на страницы с низким качеством контента.
Кроме того, канонические ссылки не отменяют необходимость использования других методов для управления индексацией, таких как файл robots.txt или метатеги noindex. Их использование в комбинации с каноническими ссылками обеспечит более точный контроль за индексацией сайта.
Вопрос-ответ:
Как можно закрыть сайт DLE от индексации поисковыми системами?
Для того чтобы закрыть сайт DLE от индексации поисковыми системами, можно использовать несколько методов. Один из самых простых способов — это добавить в файл robots.txt директиву, которая запрещает индексацию для всех поисковых роботов. Например, добавив строку «User-agent: * Disallow: /», вы ограничите доступ ко всему сайту. Также можно воспользоваться метатегами в заголовке HTML-страниц, добавив . Эти методы помогут вам эффективно скрыть сайт от поисковиков.
Что такое файл robots.txt и как его правильно настроить для сайта DLE?
Файл robots.txt — это текстовый файл, который размещается в корневой директории сайта и используется для управления доступом поисковых роботов к страницам. Чтобы закрыть сайт от индексации, нужно в этот файл добавить строку «User-agent: * Disallow: /». Это запретит всем поисковым системам индексировать ваш сайт. Если вы хотите закрыть только определенные страницы, то можно указать путь к ним в файле robots.txt, например, «Disallow: /private/».
Можно ли скрыть страницы сайта DLE от индексации только для определенных поисковых систем?
Да, можно ограничить доступ только для определенных поисковых систем. Для этого в файле robots.txt можно указать директивы, которые будут применяться к конкретным поисковым роботам. Например, для Google это будет выглядеть так: «User-agent: Googlebot Disallow: /». Такой подход позволяет гибко настраивать индексацию и блокировать только те поисковые системы, которые вы хотите.
Что делать, если нужно закрыть сайт DLE от индексации, но при этом не нарушить доступность для пользователей?
Если нужно закрыть сайт от индексации, но сохранить его доступность для пользователей, то можно использовать директивы в файле robots.txt или метатеги в HTML-страницах. Для этого достаточно добавить в файл robots.txt строку «User-agent: * Disallow: /» или вставить метатег в заголовок каждой страницы. Эти методы не повлияют на доступность сайта для пользователей, но запретят его индексацию поисковыми системами.