Для создания парсера на PHP, который будет собирать данные с веб-сайтов, необходимо понимать основные принципы работы с HTTP-запросами, обработки HTML-кода и извлечения нужной информации. В этой статье мы рассмотрим, как пошагово создать эффективный парсер с использованием стандартных библиотек PHP.
Первый этап – это отправка HTTP-запросов для получения HTML-страницы. Для этого обычно используют функцию file_get_contents() или более гибкий инструмент cURL. cURL предоставляет гораздо больше возможностей для настройки запросов: можно установить заголовки, обработать редиректы, управлять временем ожидания и т.д. Важно настроить правильную обработку ошибок, чтобы избежать сбоев при недоступности сайта или неверных запросах.
После получения HTML-кода страницы наступает этап парсинга. Для эффективного извлечения данных из HTML рекомендуется использовать библиотеку PHP Simple HTML DOM Parser, которая предоставляет удобный интерфейс для поиска и обработки элементов DOM. Она позволяет легко извлекать данные по тегам, классам или идентификаторам, что значительно ускоряет процесс работы. Альтернативой может быть использование регулярных выражений, но данный метод менее гибкий и подвержен ошибкам, если структура HTML-страницы изменится.
Далее необходимо обработать полученные данные и привести их к нужному формату. Например, если парсер собирает информацию о товарах, нужно извлечь такие данные, как название, описание, цену и изображение. Для этого часто используют методы find() или find_all() из библиотеки PHP Simple HTML DOM Parser, которые позволяют работать с элементами по их атрибутам или содержимому.
Для создания парсера на PHP важно выбрать правильные инструменты, которые помогут эффективно собирать и обрабатывать данные с веб-сайтов. Существует несколько популярных библиотек и фреймворков, которые значительно упрощают этот процесс. Рассмотрим лучшие из них.
Одним из самых популярных инструментов является библиотека Goutte, построенная на основе Symfony. Она проста в использовании и предоставляет удобный интерфейс для работы с HTML-документами. Goutte идеально подходит для парсинга и извлечения данных с небольших сайтов. Ее преимущества:
- Поддержка CSS-селекторов и XPath для навигации по DOM-дереву;
- Поддержка работы с JavaScript через интеграцию с библиотеками для симуляции браузера;
- Простота и быстрота разработки.
Другим инструментом является Symfony Panther – более мощная альтернатива Goutte. Panther позволяет выполнять парсинг с полноценной поддержкой браузеров, включая JavaScript-рендеринг. Это делает его отличным выбором для сложных сайтов, где JavaScript играет важную роль в структуре данных. Важные особенности:
- Поддержка реального рендеринга страниц с использованием Chrome или Firefox;
- Интеграция с браузерной автоматизацией (WebDriver), что позволяет взаимодействовать с элементами на страницах.
Для более гибкой и масштабируемой работы с HTTP-запросами стоит рассмотреть Guzzle. Эта библиотека предназначена для работы с REST API и HTTP-запросами, что полезно при сборе данных с сайтов, которые предоставляют API или используют динамическую загрузку данных. Guzzle помогает:
- Гибко настроить запросы и обработку ответов;
- Работать с прокси-серверами и устанавливать тайм-ауты;
- Отправлять запросы через различные HTTP-методы (GET, POST, PUT и другие).
Если парсер требует мощных возможностей по обработке больших объемов данных, стоит обратить внимание на phpQuery, библиотеку, схожую с jQuery, но для серверной стороны. phpQuery позволяет легко манипулировать DOM-деревом и извлекать нужные элементы с помощью простого синтаксиса. Среди ключевых особенностей:
- Работа с HTML-документами как с jQuery-объектами;
- Поддержка XPath и CSS-селекторов;
- Простота интеграции в проекты с различными структурами данных.
Еще одним важным инструментом является DiDOM. Это библиотека для парсинга и манипуляции HTML, которая обладает высокой производительностью и поддерживает XPath и CSS-селекторы. Она хороша для работы с большими страницами и может быть полезной при разработке сложных парсеров с глубоким анализом контента. Преимущества DiDOM:
- Быстрая работа с DOM-деревом;
- Поддержка работы с большими файлами;
- Легкость в использовании для создания сложных запросов.
Если требуется работа с веб-страницами, которые активно используют JavaScript, стоит обратить внимание на Headless Chrome через библиотеку ChromeDriver или PHP-WebDriver. Эти инструменты позволяют запускать страницы в безголовом режиме, что открывает доступ к данным, загружаемым динамически через JavaScript. Преимущества такого подхода:
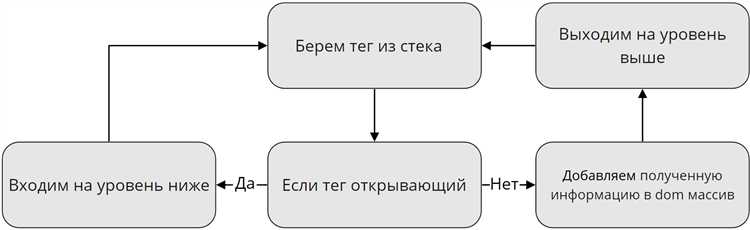
Анализ структуры HTML-страницы – важный этап при создании парсера для сбора данных. Начать стоит с понимания, как устроен документ HTML и как элементы страницы сгруппированы. В первую очередь нужно изучить теги, классы и идентификаторы, которые содержат интересующие вас данные. HTML-разметка строится по принципу вложенных элементов, что позволяет эффективно выделять нужные фрагменты.
Один из способов анализа структуры – это использование инструментов разработчика в браузере. В Google Chrome или Firefox откройте страницу, нажмите правой кнопкой мыши и выберите «Посмотреть код» или «Исследовать элемент». В панели можно видеть иерархию тегов, их атрибуты, а также содержимое. Это позволяет точно понять, где находятся данные, которые вы хотите извлечь.
Для поиска нужной информации, нужно обратить внимание на CSS-селекторы. Теги, такие как div, span, p, могут использовать разные атрибуты – id, class, data-* – чтобы выделять блоки, содержащие данные. Например, если все цены на сайте расположены внутри тега div с классом price, вам нужно будет искать все такие элементы с помощью селектора div.price.
После нахождения нужных блоков важно проанализировать их вложенность. Часто данные могут быть внутри других элементов, например, span внутри p или ul с элементами li. В этом случае важно использовать комбинированные селекторы. Например, чтобы извлечь название товара, можно использовать div.product > h1, где product – класс родительского блока, а h1 – тег, в котором содержится название.
Не стоит забывать про динамические страницы. Современные сайты используют JavaScript для подгрузки данных. В таких случаях парсер на PHP может не найти нужную информацию в исходном HTML. Для работы с такими страницами можно использовать дополнительные инструменты, такие как headless-браузеры (например, Puppeteer или Selenium), которые позволяют выполнять JavaScript и загружать динамическое содержимое.
Когда структура страницы ясна, важно учесть возможные изменения в разметке. Статические сайты, как правило, имеют фиксированную структуру, но на динамических может изменяться порядок элементов или классы. В таких случаях стоит писать более универсальные парсеры, которые могут учитывать различные варианты разметки, например, используя регулярные выражения или другие методы поиска.
Настройка CURL для загрузки страниц с динамическим контентом
Для работы с динамическими страницами, которые загружаются с помощью JavaScript, стандартный CURL в PHP не всегда будет эффективен. Он может получить только исходный HTML, без учета изменений, происходящих на странице в процессе загрузки. Чтобы решить эту проблему, необходимо настроить CURL так, чтобы он мог работать с такими сайтами.
Первым шагом будет базовая настройка CURL для получения страниц. Для этого нужно установить необходимые опции, например, следующее:
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://example.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true); $response = curl_exec($ch); curl_close($ch);
Этот код позволяет скачать страницу и возвращает ее HTML-код. Однако для динамических страниц этого недостаточно, так как содержимое загружается после выполнения JavaScript. Чтобы получить данные, загружаемые через JavaScript, необходимо эмулировать поведение браузера. Для этого используйте два подхода:
1. Использование заголовков HTTP. Некоторые страницы используют заголовки, чтобы определить, является ли запрос от браузера или от бота. В таком случае необходимо добавить правильные заголовки (например, заголовок «Referer», «Accept», «Accept-Encoding», «Accept-Language»). Это поможет избежать блокировки запросов и даст доступ к динамическому контенту.
curl_setopt($ch, CURLOPT_HTTPHEADER, [ "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Accept-Encoding: gzip, deflate, br", "Accept-Language: en-US,en;q=0.5", "Referer: https://example.com" ]);
2. Использование прокси и куки. Если страница генерирует контент на основе сессий или кук, нужно настроить CURL для работы с этими данными. Включите работу с куками, чтобы сохранить состояние между запросами.
curl_setopt($ch, CURLOPT_COOKIEJAR, "/tmp/cookies.txt"); curl_setopt($ch, CURLOPT_COOKIEFILE, "/tmp/cookies.txt");
Если сайт использует сложную аутентификацию или JavaScript для отправки запросов (например, через AJAX), для имитации работы браузера можно использовать прокси-серверы или другие механизмы обхода ограничений, что обеспечит корректную загрузку динамического контента.
Для более сложных случаев, когда контент загружается через AJAX или другие технологии, можно попробовать выполнить соответствующие запросы вручную через CURL, имитируя JavaScript-запросы. Это потребует анализа сети с помощью инструментов разработчика браузера, чтобы определить, какие именно запросы отправляются на сервер, и настроить CURL для их выполнения.
Однако если сайт использует сложную динамическую загрузку с множеством зависимостей, эффективным решением будет использование инструментов, как Selenium или Puppeteer, которые способны эмулировать полноценное выполнение JavaScript, включая все асинхронные запросы и изменения DOM. Эти инструменты можно комбинировать с PHP для более сложных задач, если стандартного CURL недостаточно.
Обработка и хранение полученных данных: базы данных и форматы
1. Выбор базы данных
Для хранения данных, собранных с сайтов, часто используются реляционные и нереляционные базы данных. Реляционные СУБД, такие как MySQL, PostgreSQL, подходят для структурированных данных, где важна целостность и связи между таблицами. Например, для сбора информации о товарах из интернет-магазинов логично использовать таблицы, такие как «Продукты», «Категории», «Производители», с четкими связями между ними.
Нереляционные базы данных, например MongoDB, являются хорошим выбором, когда структура данных не фиксирована, или необходимо хранить большие объемы информации, которая не требует жесткой схемы. Это особенно удобно для хранения JSON-данных, полученных через API, или информации с веб-страниц, где структура данных может варьироваться.
2. Форматы хранения данных
Выбор формата хранения зависит от особенностей данных и целей их использования. Наиболее популярные форматы:
- JSON – гибкий формат, часто используемый при получении данных через API. Он хорошо подходит для хранения структурированных данных, таких как товары, отзывы, статьи. В PHP для работы с JSON используется функция json_encode и json_decode.
- CSV – удобен для хранения табличных данных, таких как списки товаров или пользователей. Это простой формат, который легко экспортировать и импортировать в разные программы. Однако, он не поддерживает вложенные структуры данных.
- XML – может использоваться для сложных иерархических данных. Это формат с расширенной схемой, но его обработка может быть более ресурсоемкой по сравнению с JSON.
3. Обработка данных перед сохранением
Перед тем как сохранить данные в базу, их следует тщательно обработать. Это включает в себя очистку от лишних символов, нормализацию форматов (например, дат или чисел), а также проверку на дубликаты и наличие обязательных полей. Важно избегать хранения пустых значений, так как это может повлиять на производительность базы данных.
Для очистки данных можно использовать регулярные выражения или встроенные функции PHP, такие как trim, filter_var, и preg_replace для удаления ненужных символов и проверок. В случае с датами можно воспользоваться функцией strtotime для их преобразования в стандартный формат.
4. Обработка ошибок и логирование
Для надежности системы важно настроить обработку ошибок и ведение логов. Ошибки могут возникать на различных этапах, например, при подключении к базе данных или при сохранении данных. В таких случаях нужно использовать механизм логирования с помощью стандартных средств PHP или внешних библиотек, таких как Monolog.
5. Производительность и оптимизация
Если данные объемные, важно продумать механизмы их оптимизации. Например, для ускорения запросов к базе данных можно использовать индексы на часто используемые поля. Также стоит учесть, что записи, которые редко изменяются, можно кешировать, используя такие технологии, как Redis или Memcached, для снижения нагрузки на базу данных.
Системы с большим объемом данных могут потребовать дополнительных мер по масштабированию, таких как использование репликации баз данных или горизонтального масштабирования, чтобы обеспечить доступность и производительность.
Как избежать блокировки парсера: обход защиты сайтов
Чтобы избежать блокировки парсера на сайте, важно учитывать несколько ключевых аспектов защиты, применяемых владельцами ресурсов. Блокировка обычно происходит, когда сервер обнаруживает слишком частые или подозрительные запросы. Разберемся, как минимизировать риски блокировки и обойти основные виды защиты.
Первое, что следует учесть при создании парсера – это использование «человеческих» интервалов между запросами. Чрезмерная частота запросов может быть расценена как атака. Установите случайные интервалы между запросами в пределах нескольких секунд. Это поможет избежать подозрений о бот-активности.
Второй важный момент – маскировка пользовательского агента. Многие сайты проверяют заголовок User-Agent, чтобы выявить боты. Программируя парсер, задавайте в запросах различные User-Agent’ы, имитируя популярные браузеры (Chrome, Firefox, Safari). Использование прокси-серверов и смена их сессий – еще один способ избежать блокировки.
Кроме того, применяйте ротацию IP-адресов. Большинство сайтов блокируют запросы с одного IP после определенного порога. Использование прокси-сетей, таких как residential или datacenter прокси, помогает распределить трафик и избежать частых блокировок. Настройка ротации IP также улучшает анонимность парсера.
Третий важный аспект – использование капчи. Многие сайты защищены от автоматических скриптов с помощью капчи. Чтобы обойти капчу, можно использовать решения на базе машинного обучения для распознавания, либо интегрировать сервисы для решения капчи через API (например, 2Captcha или Anti-Captcha).
Использование JavaScript также становится распространенной защитой от парсеров. Сайты могут загружать данные через динамические запросы JavaScript. В таких случаях использование браузерного парсинга с инструментами вроде Puppeteer или Selenium позволяет эмулировать поведение пользователя и извлекать данные, выполняя все сценарии JavaScript на странице.
Чтобы защититься от автоматических парсеров, сайты могут внедрять такие механизмы, как анализ поведения пользователя, проверку cookies и заголовков HTTP. Чтобы обойти такие защиты, необходимо обеспечить поддержку cookies в парсере и имитировать действия, схожие с реальным человеком: открытие страниц, прокрутка и взаимодействие с элементами страницы.
Наконец, избегайте парсинга с интенсивными запросами сразу на нескольких страницах сайта. Стратегия, при которой парсер осуществляет работу поэтапно, анализируя сайт в течение продолжительного времени, позволит снизить риски блокировки и повышает шанс сбора данных без вмешательства системы защиты.
Вопрос-ответ:
Что такое парсер на PHP и зачем он нужен?
Парсер на PHP — это программа, которая автоматически извлекает данные с веб-сайтов. Обычно такие скрипты используются для сбора информации, такой как новости, цены, данные о продуктах и другие параметры. Парсер работает, анализируя HTML-код страницы и выбирая нужные элементы для дальнейшей обработки.
Какие инструменты и библиотеки можно использовать для создания парсера на PHP?
Для разработки парсера на PHP часто используют библиотеки, такие как Simple HTML DOM, Goutte и Symfony Panther. Эти инструменты упрощают процесс работы с HTML-страницами, предоставляя удобные функции для поиска и извлечения нужных данных. Также можно использовать cURL для работы с HTTP-запросами, если нужно взаимодействовать с сайтами на более низком уровне.
Какие сложности могут возникнуть при создании парсера на PHP?
Одной из основных проблем является изменение структуры HTML-страниц, что может привести к ошибкам в работе парсера. Также многие сайты защищены от автоматического сбора данных с помощью CAPTCHA или других методов, таких как ограничение запросов по IP-адресу. Поэтому важно учитывать механизмы защиты при разработке парсера и соблюдать правила использования сайта.
Как правильно настроить парсер, чтобы не попасть под блокировку сайта?
Для того чтобы избежать блокировки, стоит соблюдать несколько правил. Например, делать запросы с задержкой, чтобы не перегружать сервер. Также полезно использовать заголовки, имитирующие поведение обычного пользователя, такие как «User-Agent». Важно, чтобы ваш парсер не нарушал условия использования сайта и не делал чрезмерное количество запросов за короткий промежуток времени. В случае работы с большими объемами данных можно использовать прокси-серверы для распределения нагрузки.
Что делать, если сайт использует динамическую загрузку данных через JavaScript?
Если сайт использует динамическую загрузку контента через JavaScript, стандартный парсер на PHP, работающий с HTML, не сможет извлечь эти данные. В таком случае можно использовать инструменты, такие как библиотека Symfony Panther или инструмент для работы с браузером, как Selenium, которые позволяют эмулировать выполнение JavaScript и захватывать данные после загрузки страницы. Это позволяет парсить сайты с динамическим контентом, который не доступен в исходном HTML-коде.