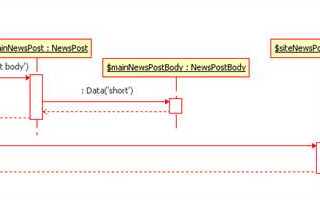
Парсинг данных с сайта с использованием PHP является важным инструментом для автоматизации сбора информации, которая может быть использована для анализа, мониторинга цен или получения статистики. В этом руководстве мы рассмотрим, как эффективно извлекать данные с веб-страниц, используя популярные инструменты PHP, такие как cURL и библиотека Simple HTML DOM.
Перед тем как начать, важно понимать, что парсинг данных с сайтов должен учитывать правовые аспекты. Прежде чем собирать информацию, убедитесь, что действия не нарушают условий использования ресурса. Некоторые сайты защищают свои данные через механизмы защиты, такие как CAPTCHA, что требует дополнительных решений для обхода.
В этом руководстве мы будем работать с cURL для отправки HTTP-запросов и Simple HTML DOM для парсинга HTML-кода. Использование этих инструментов позволяет не только извлекать текстовую информацию, но и работать с аттрибутами тегов, изображениями и ссылками. Рекомендуем заранее ознакомиться с документацией этих библиотек для лучшего понимания их возможностей.
Шаг 1: Настройка cURL – это первый шаг в парсинге, который позволяет подключиться к сайту и получить HTML-контент. cURL является мощным инструментом для работы с удалёнными серверами, позволяя отправлять GET и POST-запросы с возможностью обработки заголовков и данных.
Шаг 2: Использование Simple HTML DOM для парсинга HTML-структуры. Эта библиотека значительно упрощает процесс извлечения элементов с помощью CSS-селекторов, что делает код читаемым и лаконичным. Например, для извлечения заголовков статей на сайте достаточно нескольких строк кода.
Следуя этому руководству, вы сможете создавать эффективные скрипты для сбора данных, автоматизируя работу с информацией, доступной в открытых источниках.
Как подключить cURL для парсинга сайтов на PHP
Для парсинга данных с сайта на PHP необходимо использовать библиотеку cURL. Это мощный инструмент для работы с HTTP-запросами, который позволяет загружать страницы, отправлять данные на сервер и получать ответы. Чтобы использовать cURL, необходимо убедиться, что расширение cURL включено в конфигурации PHP. В большинстве современных установок PHP это расширение уже включено по умолчанию.
Шаг 1: Проверка включения cURL в PHP
Чтобы проверить, активировано ли расширение cURL, выполните команду php -m в командной строке. Если в списке активных расширений присутствует curl, значит, оно уже подключено. В противном случае, необходимо включить расширение в файле php.ini, раскомментировав строку extension=curl и перезапустив сервер.
Шаг 2: Инициализация cURL-сессии
Для начала работы с cURL нужно инициализировать сессию с помощью функции curl_init(). Эта функция возвращает идентификатор сессии, который используется для дальнейших запросов.
$ch = curl_init();
Шаг 3: Установка параметров запроса
Для того чтобы указать cURL, что именно нужно сделать с сессией, применяются различные опции через функцию curl_setopt(). Например, чтобы загрузить страницу, установите URL с помощью параметра CURLOPT_URL:
curl_setopt($ch, CURLOPT_URL, "https://example.com");
Также важно указать параметр CURLOPT_RETURNTRANSFER, чтобы результат запроса был возвращен как строка, а не выведен напрямую:
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
Шаг 4: Выполнение запроса
После настройки всех опций можно выполнить запрос с помощью функции curl_exec(). Этот метод выполнит HTTP-запрос и вернет ответ от сервера:
$response = curl_exec($ch);
Шаг 5: Обработка ошибок
Для обработки ошибок запроса важно использовать функцию curl_error(), которая возвращает описание ошибки, если таковая произошла. Например:
if(curl_errno($ch)) {
echo 'Ошибка cURL: ' . curl_error($ch);
}
Шаг 6: Закрытие сессии
После завершения работы с cURL-сессией необходимо закрыть её с помощью функции curl_close(), чтобы освободить ресурсы:
curl_close($ch);
Пример полноценного кода
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://example.com");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
if(curl_errno($ch)) {
echo 'Ошибка cURL: ' . curl_error($ch);
}
curl_close($ch);
Этот код загрузит страницу с указанного URL и сохранит её содержимое в переменной $response, которое затем можно обработать для парсинга.
Использование cURL в PHP – это гибкий и мощный способ взаимодействия с веб-ресурсами, позволяющий собирать нужную информацию с различных сайтов.
Получение HTML-кода страницы с помощью PHP
Для получения HTML-кода веб-страницы с использованием PHP можно воспользоваться функцией file_get_contents() или библиотеками для более сложных запросов, такими как cURL.
Простейший способ получения контента – это использование file_get_contents(). Этот метод удобен, когда нужно быстро скачать HTML-страницу без дополнительной настройки. Пример:
$url = 'https://example.com';
$html = file_get_contents($url);
echo $html;
Однако, file_get_contents() не всегда подходит, особенно если нужно настроить параметры запроса, такие как заголовки, куки или метод HTTP. В таких случаях стоит использовать cURL.
Пример использования cURL:
$url = 'https://example.com';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
echo $html;
- Преимущества cURL: поддержка различных HTTP-методов (GET, POST), настройка заголовков, отправка данных в запросах.
- Преимущества
file_get_contents(): простота и быстрое использование без дополнительных настроек.
Если вам нужно отправить запрос с параметрами, можно использовать http_build_query() для формирования строки параметров и метод POST:
$url = 'https://example.com';
$data = ['key' => 'value', 'param' => 'example'];
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query($data));
$html = curl_exec($ch);
curl_close($ch);
echo $html;
Для обработки ошибок важно проверять успешность выполнения запроса. В случае с file_get_contents() можно использовать конструкцию if ($html === false), а с cURL – curl_errno() и curl_error().
Заключение: выбор метода зависит от сложности задачи. Для простых запросов с одной страницей file_get_contents() подойдет, в то время как для более сложных взаимодействий с сервером и гибкой настройки запроса лучше использовать cURL.
Извлечение данных из HTML с использованием регулярных выражений

Пример: допустим, необходимо извлечь все URL-адреса из тегов <a>. Регулярное выражение для поиска ссылок будет выглядеть следующим образом:
/<a\s+href=["']([^"']+)["']/iЗдесь:
- <a\s+href=[«‘]([^»‘]+)[«‘] – регулярное выражение, которое ищет тег <a> с атрибутом href, извлекая URL внутри кавычек.
- \s+ – один или несколько пробельных символов, которые могут разделять тег и атрибут.
- [^»‘]+ – выражение для захвата всех символов, которые не являются кавычками, для получения самого URL.
Чтобы применить это регулярное выражение в PHP, можно использовать функцию preg_match_all():
$pattern = '/<a\s+href=["']([^"']+)["']/i';
preg_match_all($pattern, $html_content, $matches);
print_r($matches[1]);
Этот код извлечет все URL-адреса из тега <a> и выведет их в массиве $matches[1].
Регулярные выражения также полезны для извлечения текста внутри определённых тегов. Например, если нужно получить текст внутри тега <h1>, можно использовать следующее выражение:
/<h1>([^<]+)<\/h1>/iЗдесь:
- [^<]+ – захватывает все символы, которые не являются началом другого тега.
Важно помнить, что регулярные выражения не идеальны для работы с HTML-документами, особенно когда структура HTML сложная. Лучше всего их использовать для извлечения простых и однотипных данных. Для более сложных задач рекомендуется использовать специализированные парсеры, такие как DOMDocument в PHP.
Работа с DOM-деревом через PHP для парсинга
Для начала парсинга страницы с помощью DOM необходимо создать объект DOMDocument и загрузить HTML-документ. Основной метод для этого – loadHTML().
$doc = new DOMDocument();
libxml_use_internal_errors(true); // Отключаем предупреждения о некорректном HTML
$doc->loadHTML(file_get_contents('страница.html'));
После загрузки документа можно работать с его элементами. Для этого используются методы, такие как getElementsByTagName(), который позволяет находить все элементы с определённым тегом.
$links = $doc->getElementsByTagName('a');
foreach ($links as $link) {
echo $link->getAttribute('href') . "\n";
}
Кроме того, для поиска элементов по ID или классу можно использовать метод getElementById() или getElementsByClassName(), если вы используете DOMXPath.
Для извлечения данных из атрибутов, например, из ссылки (<a>), применяется метод getAttribute(). Это удобно, когда нужно получить значения из атрибутов href, src и других.
$doc = new DOMDocument();
$doc->loadHTML(file_get_contents('страница.html'));
$xpath = new DOMXPath($doc);
$nodes = $xpath->query('//a[@class="external"]'); // Получаем все ссылки с классом 'external'
foreach ($nodes as $node) {
echo $node->getAttribute('href');
}
Использование DOMXPath позволяет значительно упростить выборку элементов на основе различных критериев: теги, атрибуты, классы. XPath-выражения могут быть сложными, что дает большую гибкость в поиске элементов.
Помимо поиска элементов, с DOM можно изменять содержимое страницы. Например, изменить текст в теге <p>:
$paragraph = $doc->getElementsByTagName('p')->item(0); // Первый параграф
$paragraph->nodeValue = 'Новый текст параграфа';
Работа с DOM-деревом предоставляет широкий функционал для парсинга и манипуляций с HTML-документами. Для эффективного использования DOM важно помнить о корректной обработке ошибок и работе с различными кодировками.
Как обрабатывать ошибки при парсинге данных с сайта
Ошибки при парсинге данных могут возникать по множеству причин: изменения в структуре HTML, проблемы с подключением или блокировки со стороны сайта. Важно предусмотреть их обработку для обеспечения стабильности работы скрипта.
1. Обработка сетевых ошибок. При запросах к сайту могут возникнуть проблемы с сетью, такие как отсутствие соединения или тайм-аут. Используйте конструкцию try-catch для обработки исключений в PHP. Например, при использовании cURL можно проверять код ответа сервера:
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://example.com');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
if(curl_errno($ch)) {
echo 'Ошибка cURL: ' . curl_error($ch);
}
curl_close($ch);
2. Проверка наличия данных. Если в процессе парсинга ожидаемые данные отсутствуют (например, определённый HTML-элемент не найден), нужно предусмотреть обработку этого случая. Используйте условные операторы для проверки наличия элементов перед извлечением информации:
$dom = new DOMDocument();
@$dom->loadHTML($html);
$xpath = new DOMXPath($dom);
$elements = $xpath->query('//div[@class="example"]');
if ($elements->length == 0) {
echo 'Элемент не найден';
}
3. Логирование ошибок. Логирование помогает отслеживать проблемы в процессе работы парсера. Записывайте ошибки в файл или в базу данных, чтобы позже можно было проанализировать, что именно пошло не так. В PHP можно использовать функцию error_log:
error_log('Ошибка парсинга на странице ' . $url, 3, '/var/log/parser_errors.log');
4. Обработка изменения структуры сайта. Если структура сайта меняется, парсер может не найти нужные элементы. Чтобы минимизировать это, регулярно проверяйте актуальность структуры и тестируйте парсер. Один из способов – использовать динамическую проверку структуры с использованием регулярных выражений, чтобы удостовериться в наличии нужных данных.
5. Ограничение количества запросов. Для предотвращения блокировки вашего парсера со стороны сайта ограничьте количество запросов в единицу времени. Используйте задержки между запросами с помощью функции sleep(). Это не только поможет избежать блокировок, но и улучшит стабильность работы парсера:
sleep(1); // задержка в 1 секунду между запросами
6. Обработка кодов состояния HTTP. Важно проверять коды ответов от сервера. Ответ с кодом 404 (страница не найдена) или 403 (доступ запрещён) сигнализирует о проблемах с доступом. Для обработки этих ошибок можно использовать следующий код:
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($httpCode == 404) {
echo 'Страница не найдена';
} elseif ($httpCode == 403) {
echo 'Доступ запрещён';
}
Применение этих методов в парсере поможет сделать его более надёжным и устойчивым к возможным сбоям, что в свою очередь повысит точность и стабильность сбора данных.
Как парсить страницы с динамическим контентом с помощью PHP
При парсинге страниц с динамическим контентом с использованием PHP основная задача – получить данные, которые загружаются через JavaScript, так как традиционные методы парсинга HTML (например, с использованием библиотеки cURL) не могут обработать такие страницы. В этом случае можно использовать несколько подходов.
1. Использование cURL для получения исходного кода страницы
Для начала необходимо загрузить исходный код страницы с динамическим контентом. Для этого используйте PHP-библиотеку cURL, которая позволяет сделать HTTP-запрос и получить HTML. Однако такой метод не даст вам доступ к данным, загружаемым через JavaScript, поскольку cURL не выполняет JavaScript-код.
2. Использование PhantomJS или Headless Browser
Для обхода этого ограничения можно использовать Headless Browser или PhantomJS (или его более современный аналог – Chrome Headless). Эти инструменты позволяют запускать браузеры без графического интерфейса, которые способны выполнить JavaScript-код и отрендерить страницу. После рендеринга контента вы получаете готовую HTML-страницу с динамически загруженными данными, которую можно парсить как обычный HTML.
3. Использование PHP-библиотеки Goutte
Библиотека Goutte удобна для парсинга страниц с уже загруженным HTML, однако она не выполняет JavaScript. Если данные на странице подгружаются через Ajax-запросы, нужно найти URL этих запросов, а затем выполнить с ними необходимые действия в коде PHP, используя cURL.
4. Парсинг через API
Если сайт предоставляет API для получения данных, это может быть лучшим вариантом для получения информации. В этом случае можно использовать cURL или Guzzle для отправки HTTP-запросов и получения структурированных данных, таких как JSON или XML. Это значительно упрощает задачу парсинга и ускоряет процесс получения данных.
5. Пример использования Guzzle для получения данных с динамической страницы
Предположим, что данные на странице загружаются через API. Вы можете использовать библиотеку Guzzle для выполнения запросов:
$client = new GuzzleHttp\Client();
$response = $client->request('GET', 'https://example.com/api/data');
$data = json_decode($response->getBody()->getContents(), true);
Этот код отправляет запрос на API и получает данные в формате JSON, которые затем можно обработать и использовать.
6. Использование инструментов для анализа HTTP-запросов
Если данные загружаются через динамические запросы (например, при помощи AJAX), то можно использовать инструменты разработчика в браузере (например, в Google Chrome) для анализа запросов и их параметров. После этого можно воспроизвести эти запросы в PHP с помощью cURL или Guzzle.
Заключение
Парсинг динамического контента с помощью PHP требует дополнительных шагов, таких как использование Headless браузеров или анализ API. Знание инструментов для работы с HTTP-запросами и правильное использование библиотек для рендеринга JavaScript-кода позволяют эффективно собирать данные с таких сайтов.
Чтение и обработка данных в формате JSON при парсинге
Шаг 1: Получение JSON-данных
Для начала необходимо получить JSON-данные с веб-страницы или API. Обычно используется функция file_get_contents() или cURL для извлечения данных. Например, для получения данных с удаленного API можно использовать следующий код:
$jsonData = file_get_contents('https://example.com/api/data');
Шаг 2: Декодирование JSON
После получения строки в формате JSON, необходимо преобразовать её в массив или объект для дальнейшей работы. Для этого используется функция json_decode(). Важно указать параметр true, если вы хотите преобразовать данные в ассоциативный массив, или оставить его пустым для получения объекта. Пример:
$data = json_decode($jsonData, true);
Если JSON некорректен, функция json_decode() вернёт null. Для обработки ошибок можно использовать функцию json_last_error(), которая возвращает код последней ошибки при декодировании.
Шаг 3: Обработка полученных данных
После декодирования JSON в структуру данных, можно приступать к обработке. Допустим, JSON содержит список пользователей с их именами и возрастами. Для перебора данных можно использовать цикл foreach. Пример:
foreach ($data['users'] as $user) {
echo "Имя: " . $user['name'] . ", Возраст: " . $user['age'] . "
";
}
Шаг 4: Работа с вложенными данными
JSON-данные часто содержат вложенные массивы или объекты. Для работы с ними используется стандартная техника обращения к ключам. Например, если каждый пользователь имеет список заказов, можно извлечь эти данные следующим образом:
foreach ($data['users'] as $user) {
echo "Имя: " . $user['name'] . "
";
foreach ($user['orders'] as $order) {
echo "Заказ: " . $order['item'] . ", Цена: " . $order['price'] . "
";
}
}
Шаг 5: Обработка ошибок при декодировании
Важно проверять, успешно ли прошел процесс декодирования JSON. Если декодирование не удалось, нужно обработать ошибку. Вот пример проверки:
if (json_last_error() !== JSON_ERROR_NONE) {
echo "Ошибка при декодировании JSON: " . json_last_error_msg();
}
Шаг 6: Кодирование данных обратно в JSON
Если нужно отправить обработанные данные обратно на сервер или в API, можно преобразовать массив или объект в строку JSON с помощью функции json_encode(). Пример:
$jsonOutput = json_encode($data);
Понимание этих основ работы с JSON в PHP позволяет эффективно обрабатывать данные, полученные с веб-сайтов или API, и интегрировать их в ваше приложение для дальнейшей работы.
Оптимизация парсинга данных с большого количества страниц
При парсинге сотен или тысяч страниц важно минимизировать нагрузку на сервер, сократить время выполнения и избежать блокировок. Ниже представлены конкретные методы оптимизации:
- Использование многопоточности: Вместо последовательных HTTP-запросов применяйте cURL Multi. Это позволяет параллельно обрабатывать десятки URL, существенно ускоряя процесс.
- Кеширование обработанных страниц: Сохраняйте HTML-код локально после первого парсинга. При повторных запусках сравнивайте хэш содержимого, чтобы избежать лишней загрузки.
- Ограничение скорости запросов: Устанавливайте задержки между запросами (например, 200–500 мс) или используйте token bucket алгоритмы, чтобы не попасть под блокировку.
- Использование HTTP-заголовков If-Modified-Since: Это позволит серверу отдавать 304 Not Modified вместо полного ответа, если страница не изменилась.
- Сжатие трафика: Устанавливайте заголовок
Accept-Encoding: gzipпри запросах. Это снижает объем получаемых данных до 70%. - Минимизация парсинга HTML: Извлекайте только нужные узлы DOM с помощью XPath или CSS-селекторов, избегая полной загрузки и разбора дерева документа.
- Разделение задачи на чанки: Делите массив ссылок на части и обрабатывайте их по очереди. Это упрощает отладку и снижает риск сбоев при обработке большого массива данных.
- Логирование ошибок и пропусков: Фиксируйте неудачные запросы в отдельный лог. Это позволяет повторно обрабатывать только проблемные URL без полного перезапуска.
Грамотная оптимизация позволяет парсить тысячи страниц за минуты без риска блокировок и перегрузки сервера.
Вопрос-ответ:
Какие инструменты нужны для парсинга сайта на PHP?
Для извлечения данных с веб-страниц на PHP чаще всего используют библиотеки cURL и DOMDocument. cURL позволяет получить HTML-код страницы, а DOMDocument — анализировать структуру HTML и извлекать нужные элементы. Также иногда применяют библиотеку Simple HTML DOM, которая упрощает работу с HTML-документами и делает синтаксис похожим на jQuery.
Можно ли парсить сайты, защищённые от ботов?
Многие сайты используют защиту от автоматических запросов, включая проверки на JavaScript, капчи и блокировки по IP. В некоторых случаях обойти такую защиту можно с помощью прокси-серверов, изменением заголовков User-Agent и имитацией действий браузера. Однако не всегда это работает — если страница полностью генерируется скриптами на клиентской стороне, понадобится использование инструментов вроде Puppeteer или Selenium через Node.js, а не только PHP.
Что делать, если сайт возвращает пустой HTML при парсинге?
Это может происходить, если сайт использует JavaScript для загрузки контента. В таком случае при запросе через PHP возвращается только базовая HTML-структура без содержимого. Чтобы решить проблему, можно проверить, доступен ли нужный API-адрес, с которого загружаются данные. Если API нет, и всё формируется только на стороне клиента, то PHP сам по себе не справится — понадобится использовать браузерный движок или другие средства, которые могут исполнять JavaScript.
Как обрабатывать большое количество страниц без риска блокировки?
Чтобы не перегружать сервер и не попасть в бан, нужно соблюдать паузы между запросами, использовать разные User-Agent заголовки и по возможности чередовать IP-адреса с помощью прокси. Желательно сохранять уже загруженные страницы, чтобы не запрашивать их повторно. Ещё один вариант — обращаться к странице ночью, когда нагрузка на сайт минимальна, и вероятность блокировки ниже.
Какие ошибки чаще всего возникают при парсинге с помощью PHP и как их избежать?
Распространённые ошибки — это неправильная кодировка, отсутствие нужных тегов в структуре страницы, блокировки со стороны сайта и ошибки соединения. Чтобы их избежать, следует указывать корректную кодировку при чтении страницы, проверять наличие элементов перед обращением к ним, использовать обработку исключений (try-catch) при работе с библиотеками, а также логировать ошибки, чтобы быстрее находить причину сбоя. Регулярное обновление парсера также помогает, так как структура страниц может меняться.