Visual Studio по умолчанию может не обеспечивать корректную обработку всех символов Юникода, что особенно критично при работе с многоязычными проектами. Для полноценной поддержки необходимо правильно настроить кодировку исходных файлов и параметры компиляции.
Первым шагом следует убедиться, что исходные файлы сохранены в кодировке UTF-8 с BOM или UTF-16, поскольку это гарантирует корректное отображение и обработку символов в редакторе и на этапе компиляции. В настройках проекта необходимо активировать опцию Use Unicode Character Set в свойствах конфигурации.
Выбор кодировки файлов для корректного отображения Юникода
Для правильной поддержки Юникода в проектах Visual Studio необходимо сохранять исходные файлы в кодировке UTF-8 с BOM или UTF-16. UTF-8 с BOM гарантирует, что редактор и компилятор корректно распознают формат файла, предотвращая ошибки при чтении символов вне ASCII-диапазона.
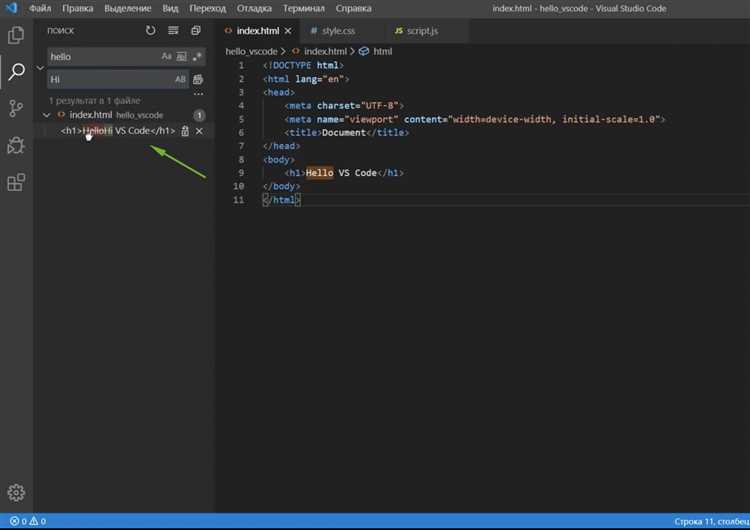
При создании новых файлов в Visual Studio следует явно выбирать кодировку через меню «Файл» → «Сохранить как…» → «Сохранить с кодировкой» и устанавливать UTF-8 с BOM. Отсутствие BOM в UTF-8 может привести к проблемам с интерпретацией первой строки, особенно если в коде используются директивы препроцессора или комментарии на русском языке.
UTF-16 подходит для проектов, где важна максимальная совместимость с нативными API Windows, однако его использование увеличивает размер файлов и требует поддержки в системе сборки. При работе с библиотеками, поддерживающими только UTF-8, предпочтительнее использовать UTF-8 с BOM.
При работе с внешними ресурсами и файлами конфигураций важно удостовериться, что кодировка совпадает с ожидаемой программой, иначе возможны ошибки парсинга и некорректное отображение символов. Рекомендуется проверять кодировку через встроенный в Visual Studio редактор или специализированные утилиты.
В случаях миграции старых проектов с ANSI или других локальных кодировок необходимо конвертировать файлы в UTF-8 с BOM, используя инструменты Visual Studio или сторонние конвертеры, чтобы избежать ошибок при сборке и выполнении программ, работающих с Юникод-строками.
Настройка проекта для использования широких строковых типов
Для корректной работы с широкими строками (тип wchar_t и связанные с ним классы, например, std::wstring) необходимо настроить проект на использование Unicode и соответствующих кодировок. В Visual Studio перейдите в свойства проекта:
1. Активируйте поддержку Unicode: в разделе Configuration Properties → General → Character Set выберите Use Unicode Character Set. Это автоматически задаст использование широких строк в стандартных функциях и классах Windows API.
2. Убедитесь, что исходные файлы сохранены в кодировке UTF-8 с BOM: Visual Studio корректно распознаёт UTF-8 с BOM, что обеспечивает правильное чтение широких литералов.
3. Включите поддержку широких символов в компиляторе: для C++ важно, чтобы функции и макросы использовали широкие версии (например, _T, TEXT макросы или явное использование L»строка» для литералов).
4. При работе с внешними библиотеками убедитесь, что их интерфейсы поддерживают wchar_t или используйте соответствующие адаптеры.
5. Для конвертации между узкими и широкими строками применяйте функции из locale или специализированные API Windows (MultiByteToWideChar и WideCharToMultiByte) с указанием кодовой страницы.
Данные настройки гарантируют, что проект будет работать с широкими строками без ошибок кодировки и обеспечат совместимость с Unicode API.
Конфигурация компилятора для поддержки Юникода
Для корректной работы с Юникодом в Visual Studio необходимо установить правильные параметры компилятора. В первую очередь, в настройках проекта нужно задать поддержку многобайтовых или широких символов. В разделе «Свойства проекта» откройте «Конфигурация C/C++» → «Общие» и в пункте «Поддержка многоязычного набора символов» выберите «Использовать Юникод (Unicode)». Это переключит стандартные типы строк на широкие символы (wchar_t).
Обязательным является определение макроса UNICODE и _UNICODE в настройках препроцессора. Это гарантирует использование правильных версий API Windows и библиотечных функций с поддержкой Юникода.
Для компилятора MSVC рекомендуется дополнительно указать кодировку исходных файлов в UTF-8 с BOM. Это делается через пункт «Дополнительные параметры» в настройках компиляции, где необходимо добавить ключ /utf-8. Это исключит ошибки при работе с многоязычным текстом в исходниках.
При работе с широкими строками важно использовать соответствующие функции стандартной библиотеки, например, wprintf вместо printf, и типы wchar_t, std::wstring вместо char, std::string.
Если проект использует старые библиотеки или сторонние компоненты, требуется проверить совместимость с Юникодом и при необходимости использовать функции преобразования между ANSI и UTF-16 через MultiByteToWideChar и WideCharToMultiByte.
Резюмируя, для полноценной поддержки Юникода в Visual Studio установите следующие ключи компилятора и препроцессора:
- Макросы:
UNICODE,_UNICODE - Кодировка исходных файлов:
/utf-8 - Опция поддержки многоязычного набора символов: «Использовать Юникод (Unicode)»
Такой подход исключит типичные ошибки с кодировками и обеспечит корректное отображение и обработку международных символов.
Использование BOM (Byte Order Mark) в исходных файлах
BOM – специальная метка в начале текстового файла, указывающая кодировку и порядок байтов. В контексте Visual Studio правильное применение BOM гарантирует корректное распознавание кодировки при открытии и компиляции исходников.
Рекомендации по работе с BOM в исходных файлах:
- UTF-8 с BOM необходим для файлов, где важна совместимость с редакторами и системами, требующими явного указания кодировки. Visual Studio распознает такие файлы без ошибок при компиляции.
- В проектах с перемешанными кодировками рекомендуется использовать UTF-8 с BOM во всех исходниках, чтобы избежать проблем с неправильным отображением символов.
- При сохранении файлов в Visual Studio следует выбирать опцию “Сохранить с кодировкой” и явно указывать UTF-8 с BOM, чтобы метка автоматически добавлялась.
- Для языков с фиксированным порядком байтов (например, UTF-16 LE/BE) BOM обязателен, иначе компилятор не сможет корректно интерпретировать содержимое.
- Отсутствие BOM в UTF-8-файлах может привести к некорректной работе некоторых инструментов анализа и сборки, особенно при смешанных средах разработки.
Особенности использования BOM в Visual Studio:
- Visual Studio при открытии файла с BOM автоматически переключает интерпретацию кодировки, что исключает ошибочное отображение нелатинских символов.
- Если проект компилируется в разных средах, стоит стандартизировать использование BOM, чтобы избежать сбоев при интеграции и контроле версий.
- В случае скриптов и ресурсов с UTF-8 без BOM может потребоваться ручное указание кодировки в настройках компилятора или редактора.
- При миграции проектов с ANSI или других кодировок на Unicode нужно выполнять конвертацию с добавлением BOM, чтобы Visual Studio корректно распознала новый формат.
Игнорирование BOM или неконсистентное его применение приводит к трудностям при работе с многоязычными проектами и увеличивает риск ошибок на этапе сборки и выполнения.
Работа с ресурсами и локализация на основе Юникода
В Visual Studio для поддержки многоязычных приложений с Юникодом необходимо использовать ресурсные файлы с кодировкой UTF-8 или UTF-16. Ресурсы должны храниться в файлах .resx, которые автоматически поддерживают Юникод. При добавлении локализации создавайте отдельные ресурсные файлы с суффиксом культуры, например, Strings.ru-RU.resx, Strings.zh-CN.resx, что обеспечивает выбор правильных строк в зависимости от текущей культуры.
Важно настроить в проекте свойство NeutralResourcesLanguage, чтобы указать базовый язык, это уменьшает нагрузку на локализацию и ускоряет загрузку ресурсов. Для корректного отображения символов в интерфейсе используйте классы ResourceManager и методы CultureInfo, устанавливая требуемую культуру через Thread.CurrentThread.CurrentUICulture.
При работе с Win32-ресурсами, например, строками или диалогами, используйте Unicode-версии API-функций (имена с суффиксом W), иначе возможны искажения символов. В XAML и WPF проекты применяйте UTF-8 с BOM, чтобы обеспечить корректное чтение файлов средствами Visual Studio.
Для динамической подгрузки языковых ресурсов рекомендуется применять механизм Satellite Assemblies. В этом случае каждая локализация компилируется в отдельную сборку, размещаемую в соответствующей папке с названием культуры. Это позволяет переключать язык без пересборки основного приложения.
Обязательное тестирование локализации включает проверку отображения всех символов Юникода, особенно для азиатских и сложных письменностей, а также оценку правильности форматирования дат и чисел с учетом региональных особенностей.
Отладка и просмотр Юникод-строк в Visual Studio
Для корректного отображения Юникод-строк в окне отладки необходимо использовать типы данных, поддерживающие UTF-16 (например, wchar_t или std::wstring). В Visual Studio строки в формате UTF-16 автоматически отображаются в читаемом виде в окне «Автоматические» или «Локальные».
При работе с UTF-8 в отладчике необходимо явно приводить байтовые массивы к строкам. Для этого в выражениях можно использовать функцию reinterpret_cast и конструктор std::string, а также включать отображение через вызов std::wstring_convert или собственные утилиты конвертации.
Чтобы увидеть содержимое Юникод-строк в окне Watch, используйте форматирование ,su для отображения строк как Unicode. Например, myString,su покажет содержимое в виде Юникода, а не как байты.
При отладке на C# строки System.String в Visual Studio отображаются корректно по умолчанию. Для нестандартных кодировок рекомендуется использовать просмотр через Memory Window с выбором типа отображения «Unicode».
Для просмотра отдельных символов Юникода в шестнадцатеричном виде откройте окно «Память» и переключитесь на формат «Unicode 16-bit», что позволяет анализировать кодовые единицы по отдельности.
При работе с внешними библиотеками, возвращающими указатели на байтовые строки, используйте касты и вспомогательные функции для преобразования в std::wstring, чтобы избежать искажений при просмотре в отладчике.
Для корректного отображения символов Юникода в консоли Visual Studio требуется выполнить несколько обязательных шагов.
- Измените кодировку консоли на UTF-8:
- Для ввода символов Юникода используйте
SetConsoleCP(CP_UTF8);.
- Для ввода символов Юникода используйте
- Выберите шрифт консоли, поддерживающий Юникод:
- Перейдите в свойства окна консоли (щелчок правой кнопкой на заголовке окна).
- Вкладка «Шрифт» – выберите «Consolas», «Lucida Console» или «DejaVu Sans Mono», так как они корректно отображают большинство Юникод-символов.
- Используйте функции и типы с суффиксом «W» –
wprintf,std::wcout, типwchar_t. - При работе с текстом в UTF-8 преобразуйте строки в UTF-16, если применяете Windows API, поддерживающие только UCS-2/UTF-16.
- Для проектов на C++ с использованием стандартной библиотеки:
- Убедитесь, что исходные файлы сохранены в UTF-8 без BOM (Byte Order Mark).
- Дополнительно:
- Запускайте Visual Studio с включённой поддержкой UTF-8 (например, через системные настройки региональных стандартов Windows – «Beta: Use Unicode UTF-8 for worldwide language support»).
Исправление ошибок кодировки при сборке и выполнении
Ошибки кодировки в Visual Studio чаще всего возникают из-за несовпадения настроек кодировки исходных файлов и используемой компиляцией локали. Для устранения проблем необходимо выполнить следующие действия.
Установка кодировки исходных файлов. В меню Файл → Сохранить как → Сохранить с кодировкой выберите UTF-8 без BOM. Это гарантирует корректное распознавание символов при сборке.
Настройка кодировки консоли. Для корректного отображения Юникода в консоли Windows используйте команду chcp 65001 в начале выполнения или задайте кодовую страницу в свойствах проекта через Debugging → Command Arguments.
Проверка свойств файла. Убедитесь, что в свойствах исходного файла в Visual Studio установлена правильная кодировка. Если файл импортирован из внешнего источника, перекодируйте его в UTF-8.
Использование BOM. Для проектов с C++ и C# предпочтительно отключать BOM, так как его наличие может вызвать некорректное чтение в некоторых средах. Если проблемы сохраняются, попробуйте добавить или убрать BOM и проверить результат.
Эти меры позволяют устранить большинство ошибок, связанных с неправильной интерпретацией Юникода на этапе сборки и выполнения приложений в Visual Studio.
Вопрос-ответ:
Как включить поддержку Юникода в проекте Visual Studio для работы с текстовыми файлами на разных языках?
Для активации поддержки Юникода в Visual Studio нужно изменить кодировку исходных файлов на UTF-8 или UTF-16. В настройках проекта можно указать использование широких символов (wchar_t) вместо однобайтовых, а также настроить функции ввода-вывода так, чтобы они корректно обрабатывали многоязычные строки. В коде рекомендуется использовать типы данных, ориентированные на Юникод, и при чтении или записи файлов задавать соответствующую кодировку.
Какие основные проблемы могут возникнуть при работе с Юникодом в старых проектах Visual Studio и как их избежать?
Одна из частых проблем — несовпадение кодировок между исходным кодом, настройками проекта и используемыми библиотеками, что приводит к искажению символов. Кроме того, старые функции, работающие с обычными строками, могут неправильно обрабатывать символы вне ASCII. Чтобы этого избежать, стоит обновить код до использования широких строк и функций, поддерживающих Юникод, а также проверить, что все файлы сохранены в нужной кодировке.
Какие изменения в настройках Visual Studio влияют на корректное отображение и ввод многоязычного текста?
Важно выставить кодировку UTF-8 в свойствах проекта и убедиться, что редактор сохраняет файлы в этой кодировке. Также следует указать использование широких символов в настройках компилятора, чтобы строки хранились в формате wchar_t. Кроме того, при выводе текста в консоль или на экран нужно использовать соответствующие функции, поддерживающие Юникод, иначе возможны проблемы с отображением.
Можно ли использовать стандартные функции C++ для работы с Юникодом в Visual Studio или нужно подключать дополнительные библиотеки?
В большинстве случаев стандартные средства C++ и Windows API позволяют работать с Юникодом, если правильно настроены проект и код. Например, типы wchar_t и функции, заканчивающиеся на «W» (wide), поддерживают широкие символы. Однако для более удобной работы с кодировками и конвертацией строк иногда используют дополнительные библиотеки, такие как ICU или Boost.Locale, которые расширяют возможности стандартных функций.