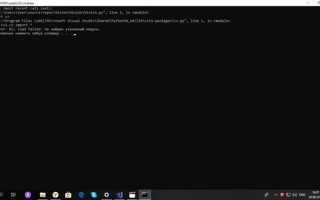
Для эффективной работы с Python необходимо понимать, как правильно подключать и использовать библиотеки. Прежде чем установить стороннюю библиотеку, важно оценить ее актуальность, качество документации и поддержку сообщества. Не каждая библиотека подходит для всех случаев, и неправильный выбор может привести к излишним сложностям в проекте.
Выбор библиотеки – это первый шаг к оптимизации рабочего процесса. Использование проверенных и активно поддерживаемых библиотек помогает минимизировать количество багов и повышает производительность разработки. При этом важно учитывать зависимостями между библиотеками. Например, библиотеки, использующие C-расширения, такие как NumPy, могут потребовать специфичной версии интерпретатора Python или операционной системы. Всегда проверяйте совместимость библиотеки с версией Python, которую вы используете.
При установке библиотек рекомендуется использовать виртуальные окружения с помощью venv или virtualenv. Это позволяет избежать конфликтов версий библиотек между различными проектами и гарантирует, что одна библиотека не повлияет на работу другой. Использование файла requirements.txt позволяет точно зафиксировать версии всех необходимых пакетов, что особенно важно для командной разработки и деплоя.
Правильное использование библиотек также включает в себя понимание их функционала и ограничения. Например, pandas подходит для работы с большими объемами данных, но для очень крупных наборов данных может потребоваться дополнительная оптимизация памяти. Важно всегда тестировать работу библиотеки на реальных данных, чтобы заранее выявить возможные проблемы с производительностью.
Выбор библиотеки для проекта: на что ориентироваться
Выбор подходящей библиотеки – ключевой момент для успешного завершения проекта. От правильного решения зависит не только скорость разработки, но и поддерживаемость кода в будущем. Вот основные аспекты, которые стоит учитывать при выборе библиотеки:
- Цели проекта. Прежде всего, уточните, какие задачи вам необходимо решить. Некоторые библиотеки универсальны, другие – узкоспециализированы. Например, для работы с данными чаще всего используют
pandasилиnumpy, в то время как для машинного обучения лучшим выбором будетscikit-learn. - Активность разработки. Перед тем как выбрать библиотеку, проверьте, насколько активно она поддерживается. Ознакомьтесь с последними релизами, частотой обновлений и количеством участников в репозитории. Это поможет избежать использования устаревших решений.
- Документация и примеры. Хорошая документация существенно облегчает работу с библиотекой. Убедитесь, что в библиотеке есть подробные примеры использования, описания всех функций и рекомендаций по внедрению. В противном случае, вам может понадобиться много времени, чтобы разобраться с инструментом.
- Совместимость и интеграция. Проверьте, насколько библиотека совместима с другими инструментами, которые вы используете. Например, если вам нужно работать с веб-разработкой, важно, чтобы выбранная библиотека интегрировалась с вашим фреймворком (например,
DjangoилиFlask). - Производительность. В некоторых случаях важно учитывать производительность библиотеки, особенно при работе с большими объемами данных или в реальном времени. Для критичных операций стоит провести собственные тесты или ознакомиться с результатами бенчмарков.
- Сообщество и поддержка. Большое сообщество и активные обсуждения на форумах – важные индикаторы качества библиотеки. Они свидетельствуют о наличии поддержки и широкого круга пользователей, что упрощает поиск решения для различных проблем.
- Лицензия. Прежде чем использовать библиотеку в коммерческом проекте, важно проверить лицензию. Некоторые библиотеки могут быть ограничены в использовании или распространяться только с определенными условиями (например,
GPLлицензия).
Оценив эти факторы, вы сможете выбрать наиболее подходящую библиотеку, которая поможет вам эффективно решить задачи проекта и избежать проблем в процессе разработки.
Как установить библиотеки с помощью pip и venv
Установка библиотек в Python происходит через менеджер пакетов pip. Он позволяет скачивать и устанавливать необходимые модули с официального репозитория PyPI. Для использования pip рекомендуется изолировать проект с помощью виртуального окружения, чтобы избежать конфликтов версий библиотек и зависимостей.
Первым шагом является создание виртуального окружения с использованием команды:
python -m venv название_окружения
Эта команда создаст каталог с именем «название_окружения», в котором будут размещены все необходимые файлы для изоляции. Для активации окружения необходимо выполнить:
source название_окружения/bin/activate # для Linux/macOS название_окружения\Scripts\activate # для Windows
После активации виртуального окружения в командной строке появится имя окружения, что свидетельствует о его активации. Теперь все установленные библиотеки будут сохраняться только в этом окружении.
Для установки библиотеки используйте команду pip install. Например, чтобы установить библиотеку requests, выполните:
pip install requests
Для указания версии библиотеки используйте следующее:
pip install requests==2.26.0
Для обновления уже установленной библиотеки можно использовать:
pip install --upgrade requests
Чтобы проверить, какие библиотеки установлены в текущем окружении, выполните команду:
pip list
Для сохранения списка зависимостей проекта в файл requirements.txt используется команда:
pip freeze > requirements.txt
Файл requirements.txt можно передать другим пользователям или использовать для восстановления всех зависимостей в другом окружении. Для установки зависимостей из файла достаточно выполнить:
pip install -r requirements.txt
После завершения работы с виртуальным окружением его можно деактивировать командой:
deactivate
Это вернет вас в глобальное окружение Python. Важно помнить, что виртуальное окружение нужно активировать каждый раз перед работой над проектом, чтобы использовать установленные в нем библиотеки.
Правила импорта: когда использовать alias и как избежать конфликтов
При работе с библиотеками в Python использование alias (псевдонимов) позволяет избежать конфликтов между именами модулей и улучшить читаемость кода. Однако важно понимать, когда и как их использовать, чтобы не создавать избыточных сложностей.
Alias применяют, когда имя модуля длинное или неудобное для повторного использования в коде. Например, стандартная библиотека NumPy часто импортируется с псевдонимом np. Это делает код компактным и снижает вероятность ошибок при многократных ссылках на этот модуль:
import numpy as npПри этом важно помнить, что использование alias должно быть осмысленным и четким. Например, import matplotlib.pyplot as plt – это стандартная практика для библиотеки Matplotlib. Однако, если вы создаете свой alias, выбирайте название, которое явно указывает на назначение модуля, чтобы не путать его с другими библиотеками.
Конфликты имен возникают, когда два модуля имеют одинаковые названия или их имена совпадают с функциями/переменными, уже существующими в текущем пространстве имен. Чтобы избежать таких конфликтов, важно следить за следующими рекомендациями:
1. Избегайте общего использования одинаковых alias: Если два разных модуля используют одинаковые alias, это может привести к путанице и ошибкам в коде. Например, импорт двух библиотек с одинаковыми псевдонимами:
import pandas as pd
import pyarrow as pdВ данном примере возникнет конфликт, так как оба модуля пытаются использовать alias pd, что приведет к перезаписи одного модуля другим. Лучше использовать уникальные псевдонимы для каждого модуля.
2. Явное указание полного пути при конфликте имен: Если вам нужно импортировать два модуля с одинаковыми именами, лучше избегать alias вообще и явно указывать полный путь к каждому модулю:
import package1.module as m1
import package2.module as m23. Использование alias в пределах ограниченных областей: В некоторых случаях можно ограничить использование alias только в части кода, где это необходимо. Например, если использование alias требуется лишь в одной функции или классе, можно ограничить импорт внутри этой области видимости.
4. Следите за стандартами и соглашениями: В большинстве случаев использование alias соответствует устоявшимся практикам. Например, использование as np для NumPy и as plt для Matplotlib – это общепринятые стандарты. Придерживайтесь этих соглашений, чтобы код оставался понятным для других разработчиков и легко поддерживаемым.
Правильное использование alias способствует улучшению читаемости кода и упрощает управление зависимостями. Однако важно соблюдать баланс между краткостью и ясностью, чтобы избежать путаницы и конфликтов имен в проектах, особенно в больших кодовых базах.
Обновление и управление версиями библиотек в проекте

Обновление и управление версиями библиотек в Python – важная часть поддержки стабильности и безопасности проекта. Использование конкретных версий библиотек позволяет избежать непредсказуемых ошибок из-за несовместимости кода с новыми релизами. Существует несколько стратегий для эффективного управления зависимостями в проекте.
Использование виртуальных окружений – первый шаг к контролю над версиями библиотек. Это позволяет изолировать зависимости проекта от глобальных установок Python. Инструменты, такие как venv или virtualenv, позволяют создать независимую среду для каждого проекта с собственными версиями библиотек.
Для контроля версий библиотек часто используется файл requirements.txt. В нем перечисляются точные версии зависимостей, которые нужны для корректной работы проекта. Пример записи для библиотеки requests:
requests==2.26.0
Обновление библиотек должно быть регулярным, чтобы получать последние исправления и улучшения. Однако обновлять библиотеки нужно осознанно, учитывая возможные изменения в API. Для обновления библиотек можно использовать команду:
pip install --upgrade <название_библиотеки>
Важно после обновления протестировать проект, так как обновления могут нарушить совместимость с текущим кодом. Для этого полезно использовать test-driven development (TDD) или регулярное покрытие кода тестами, чтобы минимизировать риски после изменения версий библиотек.
Управление зависимостями с помощью pip-tools позволяет более точно контролировать версии. pip-tools помогает создавать и обновлять файл requirements.txt с учетом точных версий всех зависимостей, включая их рекурсивные зависимости.
Версионирование с использованием semantic versioning является важным аспектом. Согласно этому подходу, обновления делятся на три категории: major (основные), minor (второстепенные) и patch (исправления). При использовании версий в формате 1.2.3 важно следить за изменениями в каждой категории:
- Major: Обновления, которые могут сломать совместимость с предыдущими версиями.
- Minor: Обновления с новыми возможностями, которые сохраняют совместимость.
- Patch: Исправления ошибок и улучшения безопасности, без изменения функционала.
Для стабильности проекта рекомендуется закреплять конкретные версии библиотек, используя == вместо >= в requirements.txt, чтобы избежать неожиданных изменений при обновлении зависимостей.
Использование систем для управления зависимостями, таких как Poetry или Pipenv, помогает не только управлять версиями библиотек, но и автоматически решать проблемы с конфликтами зависимостей. Эти инструменты упрощают процесс обновления и установки нужных библиотек с учетом версий и совместимости.
Регулярное обновление библиотек и контроль над их версиями позволяет повысить безопасность и стабильность проекта. Правильное использование инструментов управления версиями снижает риски и упрощает развитие проекта в долгосрочной перспективе.
Чтение документации: как быстро находить нужную информацию

Первым шагом является использование поиска по документации. Почти все официальные сайты и репозитории библиотек имеют встроенную строку поиска. Используйте ключевые слова, связанные с задачей, а не с конкретными методами. Например, вместо поиска по слову «filter», ищите по «iterable» или «sequence». Это позволит быстрее найти нужную информацию, особенно если название метода или класса не очевидно.
Системы навигации, такие как оглавление или индекс, также полезны. Они часто предлагают разделение на категории: общие функции, типы данных, примеры использования. Оглавление позволяет быстро перейти к нужной части документации и не тратить время на пролистывание всего материала.
Важным инструментом является использование примеров кода, которые обычно приводятся в документации. Часто проблема решается быстрее, если посмотреть на практическое применение функции или класса. Если примеры не полностью отвечают на ваш вопрос, их можно модифицировать для тестирования в вашем контексте.
Если документация библиотек слишком объемна, можно использовать дополнительные ресурсы, такие как Stack Overflow. Однако перед этим всегда убедитесь, что ваш вопрос не был уже задан, чтобы избежать дублирования усилий и сэкономить время. Прямой поиск по обсуждениям может помочь найти конкретные ответы, дополненные реальным кодом.
Не забывайте о ссылках на внешние ресурсы и официальных гайдлайнах, которые иногда приводятся в документации. Они могут направить вас на более глубокие материалы или объяснить концепции, которые не раскрыты в основной документации.
Использование встроенных инструментов, таких как `help()` в Python или автодополнение в IDE, также ускоряет процесс поиска. Эти инструменты предоставляют информацию непосредственно из документации библиотеки без необходимости открывать браузер.
Как оптимизировать использование сторонних библиотек в больших проектах

В больших проектах часто используется множество сторонних библиотек, что повышает сложность и требует грамотного подхода для их эффективного использования. Чтобы оптимизировать этот процесс, нужно учесть несколько ключевых аспектов.
Во-первых, важно ограничить количество зависимостей. Каждая библиотека добавляет новые зависимости, которые могут вызывать конфликты и усложнять поддержку кода. Использование минимального набора библиотек, необходимых для конкретных задач, помогает избежать перегрузки и улучшить совместимость. Определите, какие библиотеки действительно необходимы для проекта, и регулярно проверяйте, не существуют ли более легкие или менее ресурсоемкие альтернативы.
Во-вторых, используйте виртуальные окружения для изоляции зависимостей. Это позволяет избежать конфликтов версий библиотек при работе с несколькими проектами. С помощью таких инструментов, как virtualenv или conda, можно создать отдельное окружение для каждого проекта, что минимизирует риски при обновлении библиотек.
Третье – следите за обновлениями библиотек. Регулярное обновление до последних стабильных версий улучшает производительность, устраняет уязвимости и повышает совместимость. Однако важно следить за обратной совместимостью: обновление может повлиять на работу вашего кода. Важно проводить тестирование после каждого обновления и использовать такие инструменты, как pip-tools или Poetry, для управления зависимостями и версионностью библиотек.
Четвертое – избегайте использования чрезмерно сложных библиотек, которые добавляют функционал, не используемый в проекте. Например, если ваша задача ограничена работой с базами данных, но библиотека содержит функции для анализа данных или машинного обучения, то такие возможности могут лишь замедлить работу и усложнить код. Подбирайте библиотеки с минимальным, но достаточным функционалом для решения конкретной задачи.
Пятое – обрабатывайте исключения и ошибки, связанные с библиотеками. Часто сторонние библиотеки могут выходить из строя по различным причинам: изменения в API, устаревшие версии или неправильная конфигурация. Обеспечьте в проекте централизованную обработку ошибок и логирование, чтобы своевременно выявлять и устранять проблемы, связанные с использованием сторонних зависимостей.
Шестое – используйте зависимые библиотеки, которые активно поддерживаются и имеют широкое сообщество. Оценка популярности библиотеки, ее документации и активности разработчиков поможет выбрать те решения, которые будут надежными и безопасными в долгосрочной перспективе.
И, наконец, важно отслеживать производительность и влияние сторонних библиотек на скорость работы приложения. Использование тяжелых библиотек может замедлить работу, особенно если они имеют множество ненужных зависимостей. Регулярное профилирование и анализ производительности помогает выявить узкие места и своевременно оптимизировать код.
Тестирование и отладка кода с использованием сторонних библиотек
pytest предоставляет мощный функционал для написания тестов. Он поддерживает маркировку тестов, фикстуры, параллельное выполнение и множество плагинов. Основная особенность pytest – лаконичность кода. Например, можно использовать простые утверждения, такие как assert x == y, вместо написания подробных проверок, как в unittest.
Для отладки очень полезным инструментом является библиотека pdb, которая встроена в Python. Она позволяет установить точки останова в коде и интерактивно исследовать состояние программы. Пример использования: в нужном месте кода вставляется команда import pdb; pdb.set_trace(), после чего выполнение программы приостанавливается, и разработчик может исследовать значения переменных или выполнить команды для отладки.
Интеграция сторонних библиотек с CI/CD системами, такими как Jenkins или GitLab CI, позволяет автоматизировать тестирование на разных стадиях разработки. Использование pytest или других тестовых фреймворков с соответствующими плагинами интеграции помогает настроить запуск тестов при каждом изменении в коде и быстро выявлять проблемы.
Немаловажным моментом является использование библиотеки mock для создания подделок объектов и замещения внешних зависимостей. Это необходимо для тестирования отдельных компонентов системы без учета внешних сервисов или баз данных. Библиотека unittest.mock является встроенной, но сторонние решения, такие как pytest-mock, предоставляют дополнительные возможности для упрощения тестирования.
Таким образом, использование сторонних библиотек для тестирования и отладки позволяет значительно повысить качество кода и ускорить процесс разработки. Эти инструменты помогают выявлять ошибки на ранних стадиях, улучшать поддержку кода и упрощать его сопровождение в будущем.
Вопрос-ответ:
Как правильно выбрать библиотеку для работы с данными в Python?
При выборе библиотеки для работы с данными важно учитывать несколько факторов. Во-первых, нужно определить тип данных, с которыми вы собираетесь работать (табличные данные, текст, изображения и т.д.). Для табличных данных часто используется библиотека Pandas, которая предоставляет удобные структуры данных и инструменты для манипуляции ими. Если же требуется обработка числовых данных или математическое моделирование, то лучше всего подойдет NumPy. Для работы с изображениями стоит обратить внимание на Pillow, а для обработки текста — на библиотеки, такие как NLTK или spaCy. Кроме того, важно оценить документацию и сообщество, поддерживающее выбранную библиотеку.
Как избежать конфликтов между версиями библиотек в Python?
Чтобы избежать конфликтов между версиями библиотек в Python, рекомендуется использовать виртуальные окружения. Виртуальное окружение позволяет изолировать зависимости и версии библиотек для каждого проекта. Это можно сделать с помощью инструментов, таких как `venv` или `virtualenv`. Создав виртуальное окружение, вы сможете устанавливать нужные версии библиотек без риска повлиять на глобальные настройки Python или другие проекты. Также полезно использовать менеджеры зависимостей, например, `pip` с файлом `requirements.txt`, чтобы точно указать версии библиотек, которые должны быть установлены.
Какие ошибки чаще всего возникают при использовании библиотек в Python?
При работе с библиотеками в Python наиболее распространенные ошибки включают неправильную установку или использование несовместимых версий библиотек, ошибки импорта, когда библиотека не может быть найдена или загружена, а также неправильное использование функций и методов. Например, ошибка возникает, если библиотека не установлена в виртуальном окружении или если используется версия библиотеки, которая несовместима с текущей версией Python. Важно также помнить, что каждая библиотека может иметь свои особенности при использовании, поэтому всегда полезно читать документацию и примеры кода.
Каким образом можно улучшить производительность при работе с большими данными в Python?
Для работы с большими объемами данных в Python существуют различные подходы. Один из них — использование специализированных библиотек, таких как Dask или Vaex, которые предназначены для работы с данными, не помещающимися в память. Эти библиотеки позволяют обрабатывать данные по частям, что значительно ускоряет процесс. Также стоит обратить внимание на использование многозадачности или многопоточности с помощью библиотек, таких как `concurrent.futures` или `multiprocessing`. Для работы с числовыми массивами стоит использовать NumPy или Pandas с оптимизированными методами. Кроме того, важно минимизировать использование циклов и функций, которые могут быть ресурсоемкими, заменив их на векторизованные операции и методы, поддерживающие параллельные вычисления.