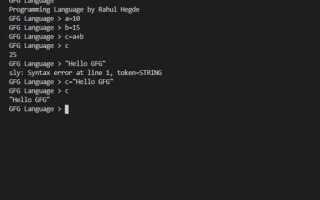
Разработка компилятора – это не просто теория, а практическое применение множества аспектов программирования и теории языков. В этой статье мы подробно рассмотрим, как создать свой компилятор на Python, начиная с базовых понятий и заканчивая построением рабочего инструмента для трансляции исходного кода в машинный. Основное внимание будет уделено последовательным этапам разработки, от лексического анализа до генерации кода.
Перед тем как приступить к реализации компилятора, важно понимать ключевые компоненты компиляции. Это лексический анализ, синтаксический анализ, семантический анализ, оптимизация и генерация кода. Все эти стадии важны и требуют детальной проработки. В Python для каждой из них существуют мощные инструменты, которые значительно упростят задачу.
Лексический анализ – это первый этап, на котором исходный код разбивается на элементы, называемые токенами. Для этого удобно использовать библиотеку ply, которая предоставляет возможности для создания лексера и парсера на основе регулярных выражений и грамматик. На этом этапе важно корректно описать все возможные элементы языка, такие как идентификаторы, ключевые слова и операторы.
На следующем шаге – синтаксическом анализе – токены группируются в структуры, соответствующие правилам грамматики. Для этого используют PLY или аналогичные библиотеки, которые позволяют задать синтаксические правила и автоматически строить абстрактное синтаксическое дерево (AST). Именно это дерево будет основой для дальнейшей работы с кодом.
После синтаксического анализа наступает этап генерации кода, на котором компилятор создает машинный код или промежуточный язык. В Python можно генерировать байт-код, что позволяет запускать программы на различных платформах без изменений исходного кода. Для создания простого интерпретатора или виртуальной машины можно использовать стандартные библиотеки Python или написать собственную реализацию виртуальной машины.
Как выбрать тип компилятора для проекта на Python

Выбор типа компилятора зависит от ряда факторов, включая цели проекта, требуемую производительность и специфические ограничения. Важно понимать, что Python, будучи интерпретируемым языком, не имеет традиционного компилятора, как C или C++, однако существуют различные подходы, позволяющие компилировать код Python для улучшения его выполнения или интеграции с другими языками.
1. Использование стандартного CPython
Если вашей целью является обеспечение совместимости с большинством библиотек и инструментов Python, стоит рассмотреть использование CPython – официального интерпретатора Python. Он работает хорошо для большинства стандартных приложений, но не подходит для задач, требующих высокой скорости выполнения. Если приоритетом является стабильность и поддержка, CPython будет оптимальным выбором.
2. PyPy: интерпретатор с JIT-компиляцией
PyPy использует технологию JIT-компиляции, что позволяет значительно ускорить выполнение Python-кода по сравнению с CPython. Это подходящий вариант для проектов, где важна производительность, например, для вычислительных задач или игр. Однако стоит учитывать, что PyPy не всегда совместим с некоторыми сторонними библиотеками, особенно теми, которые используют C-расширения.
3. Cython: компиляция в C
Cython предоставляет возможность компилировать Python-код в C, что позволяет повысить производительность. Этот инструмент используется, когда нужно ускорить выполнение отдельных частей программы, сохраняя при этом удобство разработки на Python. Это идеальный выбор для интеграции с кодом на C или C++, а также для написания расширений для Python, требующих высокой производительности.
4. Nuitka: полная компиляция в исполняемый файл
Nuitka преобразует Python-код в C/C++ и компилирует его в нативный исполняемый файл. Это решение полезно, если нужно создать самостоятельное приложение без зависимости от Python-интерпретатора. Nuitka поддерживает большинство стандартных библиотек Python, но возможны проблемы с более сложными сторонними пакетами, особенно если они используют специфические библиотеки.
5. PyInstaller и cx_Freeze: создание исполняемых файлов
Если задача состоит в том, чтобы собрать Python-программу в единый исполняемый файл, PyInstaller или cx_Freeze будут удобными инструментами. Эти инструменты не компилируют код в нативный язык, но упаковывают Python-программу в один файл, который может быть запущен на целевой системе. Они полезны для распространения приложений, но не увеличивают производительность самого кода.
6. Платформенные решения
Если ваш проект ориентирован на специфическую платформу, рассмотрите использование специализированных компиляторов, таких как PyOxidizer, который позволяет создавать компиляцию для Windows, Linux и macOS, или другие решения, заточенные под определённые архитектуры. Эти инструменты помогут вам создавать приложения с минимальными зависимостями и оптимизированным размером.
Выбор компилятора зависит от ваших целей: CPython для стандартной совместимости, PyPy для повышения производительности, Cython для интеграции с C, Nuitka для создания исполняемых файлов, а PyInstaller и cx_Freeze для упаковки приложений. Важно учесть также потребности в совместимости с библиотеками и специфическими требованиями к производительности.
Как реализовать лексический анализатор для компилятора на Python
Для начала нужно понять, какие элементы кода мы будем распознавать. Чаще всего это следующие типы токенов:
- Ключевые слова (например, `if`, `else`, `while`)
- Идентификаторы (например, имена переменных, функции)
- Литералы (числовые, строковые)
- Операторы (например, `+`, `-`, `*`, `=`)
- Разделители (например, `;`, `,`, `(`, `)`, `{`, `}`)
Основной подход заключается в использовании регулярных выражений для распознавания этих элементов. Мы создадим несколько регулярных выражений, каждое из которых будет соответствовать одному из типов токенов. Важно, чтобы лексер был максимально быстрым, поэтому стоит избегать избыточных операций и лишних проверок. Также важно, чтобы он правильно обрабатывал возможные ошибки, такие как неожиданные символы.
Вот пример реализации лексического анализатора для простого языка на Python:
import re
# Определим регулярные выражения для каждого типа токенов
token_specification = [
('NUMBER', r'\d+'), # Целые числа
('ASSIGN', r'='), # Оператор присваивания
('ID', r'[A-Za-z]+'), # Идентификаторы (буквы)
('OP', r'[+\-*/]'), # Арифметические операторы
('LPAREN', r'\('), # Левый круглый скобки
('RPAREN', r'\)'), # Правый круглый скобки
('SKIP', r'[ \t\n]+'), # Пробелы, табуляции, новые строки
('MISMATCH', r'.'), # Все остальное (ошибки)
]
# Скомпилируем регулярные выражения в один общий паттерн
master_pattern = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)
def lexer(code):
line_num = 1
line_start = 0
for match in re.finditer(master_pattern, code):
kind = match.lastgroup
value = match.group()
if kind == 'SKIP':
continue
elif kind == 'MISMATCH':
raise RuntimeError(f'Неожиданный символ {value!r} на строке {line_num}')
elif kind == 'NUMBER':
value = int(value)
elif kind == 'ID':
if value in ('if', 'else', 'while'): # Пример для ключевых слов
kind = value.upper()
yield kind, value
# Пример использования
code = "x = 10 + 2 * (y - 3)"
for token in lexer(code):
print(token)
В этом примере мы определили несколько типов токенов с помощью регулярных выражений. В функции lexer происходит последовательное разбиение исходного кода на токены с помощью регулярных выражений, и каждый найденный токен передается с его типом. Если лексер встречает неожиданный символ, он выбрасывает ошибку с сообщением о проблеме.
Особенности работы лексического анализатора:
- Лексер должен игнорировать пробельные символы и символы новой строки, так как они не играют роли в синтаксическом анализе, но могут быть важны для структуры программы.
- Нужно правильно обрабатывать ошибки, чтобы в случае нераспознанного символа компилятор мог указать на источник проблемы.
- Поддержка ключевых слов, идентификаторов и литералов позволяет лексеру разделять код на важные компоненты, которые потом будет легче анализировать.
Этот лексический анализатор можно легко расширить, добавив поддержку новых типов токенов, например, строковых литералов, комментариев или новых операторов. Это даст возможность строить более сложные компиляторы для языков с более продвинутой грамматикой.
Как построить синтаксический анализатор на Python
Основная цель синтаксического анализатора – разобрать строку текста (например, исходный код программы) на составляющие элементы, такие как операторы, выражения и конструкции, и преобразовать их в структуру данных, удобную для дальнейшей обработки.
1. Лексический анализ
Перед тем как приступать к синтаксическому анализу, необходимо разбить исходный код на токены. Это делается с помощью лексического анализатора (токенизатора). Токены – это минимальные значимые единицы языка, такие как ключевые слова, идентификаторы, операторы, скобки и числа.
- Пример простого лексического анализатора с использованием регулярных выражений:
import re
# Определяем паттерны для различных токенов
token_specification = [
('NUMBER', r'\d+'), # Число
('ASSIGN', r'='), # Оператор присваивания
('ID', r'[A-Za-z]+'), # Идентификатор
('PLUS', r'\+'), # Оператор сложения
('MINUS', r'-'), # Оператор вычитания
('TIMES', r'\*'), # Оператор умножения
('DIVIDE', r'/'), # Оператор деления
('LPAREN', r'\('), # Левая скобка
('RPAREN', r'\)'), # Правая скобка
('SKIP', r'[ \t]+'), # Пропуск пробелов и табуляций
('MISMATCH', r'.'), # Неизвестный символ
]
# Компилируем регулярные выражения
master_pattern = '|'.join(f'(?P<{pair[0]}>{pair[1]})' for pair in token_specification)
pattern = re.compile(master_pattern)
# Лексический анализатор
def tokenize(code):
line_num = 1
line_start = 0
for mo in pattern.finditer(code):
kind = mo.lastgroup
value = mo.group()
if kind == 'SKIP':
continue
elif kind == 'MISMATCH':
raise RuntimeError(f'{value!r} unexpected on line {line_num}')
elif kind == 'NUMBER':
value = int(value)
yield kind, value
Этот токенизатор будет разбирать код на элементы, такие как числа, операторы и скобки, и передавать их в синтаксический анализатор.
2. Построение синтаксического дерева

После того как код разобран на токены, следующим шагом будет создание синтаксического дерева. Основным элементом синтаксического дерева является выражение, состоящее из операндов и операторов.
- Пример синтаксического анализатора, который строит дерево выражений:
class Expr:
pass
class Number(Expr):
def __init__(self, value):
self.value = value
class BinOp(Expr):
def __init__(self, left, op, right):
self.left = left
self.op = op
self.right = right
def parse_expr(tokens):
token_type, token_value = next(tokens)
if token_type == 'NUMBER':
return Number(token_value)
elif token_type == 'ID':
return Number(0) # Пока что можно обрабатывать как число
raise SyntaxError('Expected number or identifier')
def parse_binop(tokens):
left = parse_expr(tokens)
token_type, token_value = next(tokens)
if token_type in ['PLUS', 'MINUS']:
op = token_value
right = parse_expr(tokens)
return BinOp(left, op, right)
return left
В этом примере создаются классы для представления чисел и бинарных операций. При парсинге токенов мы начинаем с обработки чисел и операндов, а затем строим бинарные операции на основе полученных токенов.
3. Рекурсивный спуск
Для более сложных синтаксических конструкций, таких как операции с приоритетами и скобки, часто используется метод рекурсивного спуска. Это метод, при котором каждая функция анализирует определённую часть грамматики языка.
- Пример рекурсивного спуска для выражений с операциями сложения и умножения:
def parse_term(tokens):
left = parse_factor(tokens)
token_type, token_value = next(tokens)
while token_type in ['TIMES', 'DIVIDE']:
op = token_value
right = parse_factor(tokens)
left = BinOp(left, op, right)
token_type, token_value = next(tokens)
return left
def parse_factor(tokens):
token_type, token_value = next(tokens)
if token_type == 'NUMBER':
return Number(token_value)
elif token_type == 'LPAREN':
expr = parse_expr(tokens)
next(tokens) # Пропуск RPAREN
return expr
raise SyntaxError('Expected number or parenthesis')
Здесь мы видим рекурсивный спуск для обработки термов, которые могут быть сложными выражениями или числами, окружёнными скобками.
4. Обработка ошибок
Ошибки синтаксического анализа могут возникать в случае несоответствия кода грамматике. Важно предусмотреть обработку таких ошибок, чтобы программист мог понять, что и где не так.
- Пример обработки ошибки:
def parse_expr(tokens):
token_type, token_value = next(tokens)
if token_type == 'NUMBER':
return Number(token_value)
raise SyntaxError(f"Unexpected token {token_value}")
В случае возникновения ошибки синтаксического анализа программа должна выбросить исключение, указав на тип ошибки и место в исходном коде.
5. Завершение
Синтаксический анализатор, построенный с использованием рекурсивного спуска и обработки токенов, представляет собой мощный инструмент для разработки компиляторов. Понимание того, как работать с токенами и строить синтаксические деревья, важно для создания эффективных компиляторов на Python.
Как создать таблицу символов для компилятора на Python
Первая задача при создании таблицы символов – определить, какую информацию необходимо хранить. Обычно это включает в себя:
- Имя символа (например, имя переменной или функции).
- Тип символа (целое число, строка, функция и т. д.).
- Местоположение символа (например, адрес в памяти или строка исходного кода).
- Область видимости (глобальная, локальная и т. д.).
- Дополнительные атрибуты, такие как значения по умолчанию, параметры функции и т. д.
Для создания таблицы символов на Python часто используют словарь, где ключами будут идентификаторы символов, а значениями – соответствующие метаданные. Вот пример, как это можно реализовать:
symbol_table = {}
def add_symbol(name, symbol_type, scope, location):
symbol_table[name] = {
'type': symbol_type,
'scope': scope,
'location': location
}
def get_symbol(name):
return symbol_table.get(name, None)
В данном примере функция add_symbol добавляет символ в таблицу, а get_symbol позволяет извлечь информацию о символе по его имени.
Следующий шаг – управление областью видимости. Таблица символов должна отслеживать, в какой области видимости находится каждый символ. Например, глобальные переменные будут доступны в любой части программы, а локальные – только внутри соответствующих функций. Для этого можно использовать вложенные структуры данных, где каждому символу сопоставляется не только информация о типе и местоположении, но и информация об области видимости.
def add_symbol_with_scope(name, symbol_type, scope, location):
if scope not in symbol_table:
symbol_table[scope] = {}
symbol_table[scope][name] = {
'type': symbol_type,
'location': location
}
В этой реализации область видимости хранится в качестве ключа верхнего уровня словаря. Это позволяет легко искать символы в рамках конкретной области видимости.
Также стоит обратить внимание на корректную работу с переменными в разных областях видимости. Если символ с одинаковым именем встречается в разных областях, нужно правильно обрабатывать его, чтобы избежать путаницы. Один из способов – поддержка стековой структуры для областей видимости, где каждый новый уровень области видимости добавляет новый слой символов.
Таблица символов должна быть интегрирована с другими частями компилятора, например, с анализатором лексем и синтаксическим анализатором. Она служит важной ролью в анализе программы и в дальнейшем процессе генерации кода. Таким образом, создание таблицы символов – это важный шаг на пути к созданию компилятора, который требует тщательной проработки структуры данных и учета особенностей областей видимости и типов данных.
Как реализовать генерацию промежуточного кода на Python
Процесс создания промежуточного кода начинается с анализа исходного кода и его представления в виде дерева. Для этого можно использовать модуль ast Python. Этот модуль позволяет анализировать исходный код и строить дерево синтаксиса, которое служит отправной точкой для дальнейшей генерации промежуточного кода.
После того как исходный код был представлен в виде AST, следующим шагом является трансформация этого дерева в промежуточный код. В качестве промежуточного кода можно использовать, например, трехадресный код. Каждый узел в этом коде будет представлять операцию с двумя операндами и результатом. Это позволяет легко оптимизировать и модифицировать программу. Пример трехадресной инструкции: t1 = a + b, где t1 – временная переменная, а a и b – операнды.
Для реализации такой генерации на Python можно написать класс, который будет обходить AST и генерировать соответствующие промежуточные инструкции. Например, для обработки арифметических выражений можно создать функцию, которая будет анализировать узлы дерева и генерировать код для сложения, вычитания, умножения и других операций.
Пример функции для генерации трехадресного кода для выражения:
def generate_three_address_code(ast):
code = []
temp_var_counter = 0
def new_temp_var():
nonlocal temp_var_counter
temp_var_counter += 1
return f"t{temp_var_counter}"
def process_node(node):
if isinstance(node, ast.BinOp): # Операция типа a + b
left = process_node(node.left)
right = process_node(node.right)
result = new_temp_var()
code.append(f"{result} = {left} {node.op} {right}")
return result
elif isinstance(node, ast.Name): # Переменная
return node.id
elif isinstance(node, ast.Constant): # Константа
return str(node.value)
process_node(ast)
return code
Этот пример создает промежуточный код для бинарных операций. Важно отметить, что обработка других типов операций и выражений будет требовать дополнительных проверок и обработки различных типов узлов дерева.
Также стоит учитывать, что промежуточный код можно оптимизировать. Например, операции с одинаковыми результатами можно сгруппировать, повторяющиеся выражения – удалить, а временные переменные – сократить. Оптимизация промежуточного кода позволяет улучшить производительность конечной программы, минимизируя избыточные вычисления.
Кроме того, создание промежуточного кода – это только часть процесса компиляции. После его генерации необходимо выполнить этапы оптимизации и кодогенерации для создания целевого кода, который может быть выполнен на конкретной платформе. Тем не менее, промежуточный код служит важным связующим звеном между исходным кодом и конечным машинным кодом.
Как создать оптимизацию кода в компиляторе на Python
Для начала необходимо построить промежуточное представление (IR) программы. Оно служит связующим звеном между исходным кодом и целевым машинным кодом. В Python можно реализовать это с помощью различных форматов IR, например, абстрактного синтаксического дерева (AST) или трехадресных команд (TAC).
Основные этапы оптимизации:
1. Удаление мертвого кода. Мертвый код – это код, который не влияет на результат выполнения программы. Примером может быть переменная, которая инициализируется, но не используется. Такой код можно легко удалить на этапе анализа данных.
2. Преобразование выражений. Оптимизация арифметических выражений может значительно повысить производительность. Например, выражение «x * 2» можно заменить на «x << 1" (если x целое число), что будет более эффективным на уровне ассемблера.
3. Вычисление констант. Некоторые выражения могут быть вычислены во время компиляции, а не во время выполнения программы. Это позволяет уменьшить нагрузку на процессор. В Python можно реализовать анализ константных выражений и заменить их на результат во время компиляции.
4. Алгоритмы оптимизации на уровне данных. Сюда можно отнести, например, такие подходы, как устранение избыточных вычислений. Пример: если одна и та же операция выполняется несколько раз с одинаковыми параметрами, её можно вычислить один раз и сохранить результат для дальнейшего использования.
5. Оптимизация циклов. Циклы – это часто узкие места в производительности. Оптимизация их выполнения может значительно улучшить результат. Одним из методов является цикл-распаковка или замена вложенных циклов на более эффективные структуры.
6. Использование специальных библиотек. В Python для ускорения выполнения можно использовать внешние библиотеки, такие как NumPy или Cython, которые эффективно реализуют математические операции на низком уровне. Например, многие вычисления можно передать на C-расширения, тем самым значительно повысив скорость.
После реализации этих этапов, оптимизированный код можно компилировать в машинный код с использованием стандартных инструментов, таких как GCC или LLVM, или вручную, если требуется. Однако важно понимать, что любые изменения, направленные на оптимизацию, должны проходить через тщательное тестирование, чтобы избежать ошибок, связанных с преобразованием кода.
Как реализовать генерацию машинного кода или байт-кода на Python
Для реализации генерации машинного кода или байт-кода на Python необходимо использовать несколько ключевых шагов. Рассмотрим процесс на примере создания компилятора для простого языка программирования.
На первом этапе нужно преобразовать исходный код в промежуточный представление, которое потом будет интерпретироваться или компилироваться в конечный машинный код или байт-код. В Python для этого можно использовать библиотеку llvmlite или pyllvm, которые предоставляют инструменты для работы с LLVM (Low-Level Virtual Machine). LLVM – это инфраструктура для разработки компиляторов, и она позволяет генерировать машинный код для различных архитектур.
После того, как вы создали абстрактное синтаксическое дерево (AST) вашего языка, следующим шагом является генерация байт-кода. Для этого потребуется определить набор инструкций, который будет выполняться на виртуальной машине, например, создавая стек и манипулируя его содержимым. В Python для этого можно воспользоваться стандартной библиотекой dis, которая позволяет работать с байт-кодом Python и анализировать его структуру. Каждый объект в Python – это не просто данные, а код, который интерпретируется виртуальной машиной Python. Знание этих принципов поможет при создании собственного байт-кода.
Процесс генерации машинного кода начинается с того, что нужно создать набор инструкций, которые будут интерпретироваться машиной. Каждый оператор или выражение преобразуется в соответствующие низкоуровневые команды, которые понятны процессору. Важным элементом на этом этапе является оптимизация кода – уменьшение числа операций и улучшение производительности. Для этой задачи можно использовать инструменты, такие как LLVM optimizer, которые помогают автоматизировать этот процесс.
Если ваша цель – создание байт-кода, который будет выполняться на виртуальной машине, то на этом этапе важно разработать собственную виртуальную машину, которая будет интерпретировать инструкции, сгенерированные компилятором. В качестве примера можно взять Python-бейт-код, где каждый оператор превращается в набор байт-кодов, которые интерпретируются Python-интерпретатором.
Для генерации байт-кода вручную в Python можно использовать модуль compile(), который принимает исходный код как строку и генерирует байт-код, готовый к исполнению. С помощью marshal можно сохранить сгенерированные байт-коды в файлы, чтобы потом их загружать и исполнять.
Когда байт-код или машинный код готовы, следующим шагом является их оптимизация. Например, можно использовать подходы, такие как dead code elimination (удаление мертвого кода), constant folding (сведение выражений с постоянными значениями к единому значению), или loop unrolling (разворачивание циклов для ускорения выполнения).
Для более сложных компиляторов стоит обратить внимание на поддержку различных архитектур и платформ, что требует дополнительной работы с низкоуровневыми инструментами и знания особенностей каждой архитектуры. Библиотека PyInstaller или Cython может быть полезной для создания исполняемых файлов и работы с кодом, который должен быть совместим с различными операционными системами.
Вопрос-ответ:
Что такое компилятор и зачем его создавать?
Компилятор — это программа, которая переводит исходный код, написанный на одном языке программирования, в код, понятный компьютеру. Создание собственного компилятора помогает лучше понять, как работают языки программирования, а также позволяет настроить его под свои нужды. Компилятор может быть полезен для оптимизации кода, создания новых языков или инструментов для работы с кодом.
Какие этапы необходимы для создания компилятора на Python?
Для создания компилятора нужно пройти несколько ключевых этапов: сначала разрабатывается лексический анализатор, который разбивает исходный код на токены (основные элементы языка). Затем пишется синтаксический анализатор, который строит дерево разбора и проверяет корректность структуры программы. После этого идет семантический анализ, где проверяется правильность логики и типизация данных. На последнем этапе создается генератор кода, который переводит промежуточное представление в машинный код или байт-код.
Какие библиотеки Python могут помочь при разработке компилятора?
Для разработки компилятора на Python существует несколько полезных библиотек. Например, PLY (Python Lex-Yacc) предоставляет инструменты для лексического и синтаксического анализа. ANTLR — это еще одна мощная библиотека для генерации парсеров. Также можно использовать библиотеку Lark, которая является более современной и гибкой для работы с грамматиками. Эти инструменты помогут организовать создание компилятора и упростят работу с анализом и генерацией кода.
Что такое грамматика языка, и как она используется при создании компилятора?
Грамматика языка — это набор правил, которые определяют, как правильно строятся программы на этом языке. В компиляторе грамматика используется для синтаксического анализа, когда проверяется, соответствует ли исходный код правилам языка. Это важно, потому что компилятор должен уметь различать правильные конструкции и ошибки в коде. Грамматика описывается через термины, такие как нетерминальные и терминальные символы, и затем используется для построения синтаксического дерева.
Как сделать компилятор, который будет работать с пользовательскими ошибками?
Обработка ошибок — важный аспект при создании компилятора. Для этого нужно реализовать механизм, который будет отслеживать синтаксические и семантические ошибки в коде. Например, при синтаксическом анализе компилятор должен выводить сообщения об ошибках, указывая на строку и колонку, где ошибка произошла. Также полезно добавить диагностику для типовых ошибок, таких как неправильные операции с данными или обращение к несуществующим переменным. Чем яснее будут сообщения об ошибках, тем проще пользователям будет исправить их.
Как начать создавать компилятор на Python?
Для создания компилятора на Python важно понять, что это комплексный процесс, который включает несколько ключевых этапов. Первоначально вам необходимо изучить теорию компиляции, включая грамматики и алгоритмы синтаксического анализа. Затем, нужно выбрать подходящий способ представления исходного кода (например, абстрактное синтаксическое дерево), и научиться работать с лексическим анализом, который разбивает исходный код на токены. После этого следует создание парсера, который анализирует эти токены, и генерация промежуточного представления или байткода. В заключение, компилятор должен преобразовать этот промежуточный код в машинный код. Эти шаги могут показаться сложными, но с пониманием основ и практическим подходом вы сможете создать рабочий компилятор. Также полезно использовать библиотеки Python, такие как ply или lark, которые упрощают процесс построения анализаторов.