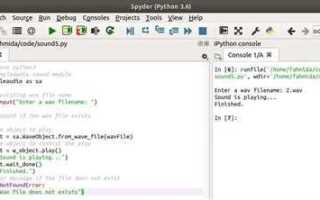
Извлечение текста из аудио стало важным инструментом в области обработки естественного языка. С развитием технологий, Python предоставил ряд мощных библиотек, которые позволяют легко и эффективно конвертировать аудио в текст. Этот процесс используется в различных сферах: от автоматической расшифровки интервью до создания систем распознавания речи для интерфейсов пользователей.
Одной из самых популярных библиотек для работы с аудио в Python является SpeechRecognition, которая поддерживает несколько движков распознавания речи, включая Google Web Speech API и CMU Sphinx. Важным преимуществом этой библиотеки является простота использования и широкая документация, что делает её отличным выбором для новичков. Важно помнить, что качество распознавания зависит от нескольких факторов, таких как чёткость речи, фоновый шум и особенности акцента.
Для работы с аудиофайлами в Python часто используется pydub, которая помогает конвертировать и обрабатывать аудио в различных форматах. В сочетании с SpeechRecognition эта библиотека позволяет улучшить качество распознавания речи, обрабатывая такие проблемы, как низкий битрейт или фоновый шум, до того, как передать файл на обработку распознающим алгоритмам.
Для повышения точности можно использовать линейные модели обучения, такие как DeepSpeech от Mozilla. Это нейросеть, предназначенная для распознавания речи, которая позволяет добиваться высокой точности даже в условиях сложного акустического фона. Однако её использование требует больших вычислительных мощностей и может быть не всегда целесообразным для всех проектов.
Установка необходимых библиотек для работы с аудио

Чтобы установить SpeechRecognition, используйте команду:
pip install SpeechRecognition
Для обработки аудиофайлов вам понадобится библиотека pydub, которая позволяет работать с различными форматами аудио, такими как WAV, MP3 и другие. Чтобы установить pydub, используйте команду:
pip install pydub
Кроме того, для конвертации аудиофайлов в формат WAV (если это необходимо) понадобится библиотека ffmpeg, которая используется pydub. Она может быть установлена следующим образом:
pip install ffmpeg-python
Если вы планируете использовать сервисы Google для распознавания речи, потребуется установить библиотеку google-cloud-speech, которая предоставляет доступ к API Google Speech-to-Text. Команда для установки:
pip install google-cloud-speech
После установки базовых библиотек необходимо настроить ключ доступа для использования API. Для этого создайте проект в консоли Google Cloud, активируйте API и получите файл с ключом, который укажете в своем проекте.
В некоторых случаях может быть полезна библиотека numpy, особенно если вы планируете проводить дополнительные вычисления или анализ звуковых данных. Установите её с помощью:
pip install numpy
Для работы с текстовыми данными и их дальнейшей обработки, рекомендую также использовать pandas, если требуется анализировать извлеченную информацию. Она поможет организовать данные в таблицы и упростит работу с большими объемами текста.
После установки всех библиотек вы готовы перейти к следующему шагу – разработке скрипта для извлечения текста из аудио.
Как преобразовать аудио в текст с использованием библиотеки SpeechRecognition
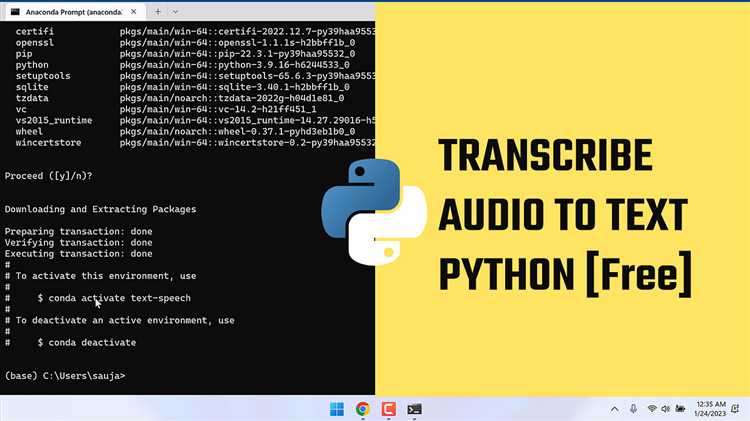
Библиотека SpeechRecognition позволяет легко преобразовывать речь в текст с помощью различных сервисов распознавания речи. Один из самых простых способов использования этой библиотеки заключается в работе с аудиофайлами, записанными в таких форматах, как WAV или MP3.
Для начала необходимо установить саму библиотеку. Это можно сделать с помощью pip:
pip install SpeechRecognition
После установки библиотеки можно приступить к преобразованию аудио в текст. Для этого нужно создать объект распознавания и загрузить аудиофайл. Пример кода для простого преобразования:
import speech_recognition as sr
recognizer = sr.Recognizer()
with sr.AudioFile('audio_file.wav') as source:
audio = recognizer.record(source)
text = recognizer.recognize_google(audio, language='ru-RU')
print(text)
В этом примере используется метод `recognize_google`, который обращается к бесплатному API Google для распознавания речи. Для работы с другими сервисами (например, Microsoft или IBM Watson) необходимо заменить этот метод на соответствующий и, возможно, передать дополнительные параметры, такие как ключи API.
Распознавание может работать с разными источниками звука. Помимо файлов, можно использовать и микрофоны. Чтобы записать аудио через микрофон, нужно использовать метод `recognizer.listen()`, как показано ниже:
with sr.Microphone() as source:
print("Говорите...")
audio = recognizer.listen(source)
text = recognizer.recognize_google(audio, language='ru-RU')
print(text)
При работе с микрофоном стоит учитывать фоновый шум, который может повлиять на точность распознавания. Для минимизации влияния шума можно использовать метод `recognizer.adjust_for_ambient_noise()`, который автоматически настраивает чувствительность микрофона:
with sr.Microphone() as source:
recognizer.adjust_for_ambient_noise(source)
print("Говорите...")
audio = recognizer.listen(source)
text = recognizer.recognize_google(audio, language='ru-RU')
print(text)
Важно помнить, что метод `recognize_google` требует подключения к интернету, так как вся обработка происходит на серверах Google. Для офлайн-работы можно использовать другие движки распознавания, такие как PocketSphinx, который также поддерживается библиотекой SpeechRecognition.
Для получения более точных результатов можно разделить аудиофайл на более короткие части и обрабатывать их поочередно, что поможет избежать ошибок при длительных записях. Также полезно использовать модели для улучшения распознавания на специфичных акцентах или для работы с шумными записями.
Использование Google Web Speech API для распознавания речи
Для начала работы с Google Web Speech API необходимо установить библиотеку SpeechRecognition, которая предоставляет удобный интерфейс для использования этого сервиса. Установить её можно с помощью команды:
pip install SpeechRecognitionПосле установки, для использования Google Web Speech API, создайте объект распознавателя речи и укажите API как источник. Вот пример кода для синхронного распознавания речи с использованием микрофона:
import speech_recognition as sr
recognizer = sr.Recognizer()
microphone = sr.Microphone()
with microphone as source:
print("Говорите...")
audio = recognizer.listen(source)
try:
text = recognizer.recognize_google(audio, language="ru-RU")
print(f"Распознанный текст: {text}")
except sr.UnknownValueError:
print("Не удалось распознать речь")
except sr.RequestError:
print("Ошибка подключения к сервису Google Web Speech API")Основные параметры API включают language, который позволяет указать язык распознавания (например, «ru-RU» для русского). Это важно для корректного распознавания текста с учетом особенностей произношения и лексики.
Google Web Speech API использует мощные алгоритмы машинного обучения, что позволяет ему работать с речью в реальном времени и с минимальными задержками. Однако следует учитывать, что для работы с API требуется интернет-соединение, так как вся обработка происходит на стороне серверов Google.
Ограничения API: Бесплатная версия API имеет ограничения по количеству запросов в день, а также лимиты по времени для одного запроса (до 60 секунд для одного сегмента аудио). Для более интенсивного использования доступна платная версия с расширенными возможностями.
Для повышения точности распознавания можно использовать дополнительные параметры, такие как show_all, который возвращает список возможных вариантов текста, а не только наиболее вероятный результат:
text = recognizer.recognize_google(audio, show_all=True)Это может быть полезно в ситуациях, когда требуется обработать неоднозначные или нечеткие фразы.
Вместо использования микрофона, Google Web Speech API также поддерживает распознавание речи из аудиофайлов. Для этого можно передать путь к файлу в метод recognize_google:
with sr.AudioFile("audio.wav") as source:
audio = recognizer.record(source)
text = recognizer.recognize_google(audio)
print(f"Распознанный текст: {text}")Поддержка различных форматов аудио файлов (WAV, AIFF и других) позволяет эффективно работать с уже записанными звуковыми данными.
Google Web Speech API – это удобный и мощный инструмент для интеграции функций распознавания речи в различные проекты на Python. Правильная настройка параметров и разумное использование лимитов помогут добиться высокой точности распознавания при минимальных затратах времени и ресурсов.
Как улучшить точность распознавания с помощью настройки параметров
Для достижения высокой точности распознавания речи в Python важно правильно настроить параметры используемой библиотеки, будь то `SpeechRecognition`, `pyaudio` или другие инструменты. Важные аспекты настройки включают выбор подходящего языка, конфигурацию микрофона, обработку шума и улучшение качества аудио.
1. Выбор правильного распознавателя
Каждый распознаватель имеет свои особенности. Например, `Google Speech Recognition` оптимизирован для высококачественного аудио, а `Sphinx` может работать с менее качественными записями, но при этом точность распознавания может быть ниже. При выборе распознавателя важно учитывать тип данных, с которыми предстоит работать.
2. Настройка микрофона
Качество микрофона напрямую влияет на точность распознавания. Использование профессионального микрофона с фильтрацией шума позволит значительно улучшить результат. В библиотеке `pyaudio` можно настроить параметры микрофона, такие как частота дискретизации и размер буфера. Например, установка высокого значения частоты дискретизации (например, 44100 Гц) может повысить качество записи, что в свою очередь улучшит распознавание.
3. Устранение шума
Шумовые помехи в аудиофайле ухудшают точность распознавания. Для минимизации этого эффекта можно использовать фильтрацию шума. В Python существует несколько библиотек для обработки звука, например, `noisereduce` или `pydub`, которые позволяют фильтровать шумы, снижая их влияние на точность распознавания.
4. Разделение на фрагменты
Длинные аудиофайлы следует разделять на более короткие фрагменты. Важно, чтобы каждый фрагмент не превышал 30-60 секунд, поскольку более длинные записи могут привести к ошибкам из-за лимита обработки или недостаточной вычислительной мощности.
5. Настройка порога для распознавания
Параметр порога чувствительности в библиотеке `SpeechRecognition` определяет, как долго программа будет ждать появления речи. Установка правильного порога позволяет избежать пропуска слов или нежелательных пауз. Например, использование параметра `energy_threshold` поможет настроить чувствительность микрофона в зависимости от уровня фонового шума.
6. Использование модели для конкретного контекста
Модели для распознавания речи можно обучить на специфичных данных, что особенно полезно для специфических терминов или акцентов. Например, если ваша задача связана с медицинской или технической тематикой, использование предварительно обученной модели или настройка для конкретных словарей повысит точность.
7. Постобработка текста
Для улучшения точности можно использовать алгоритмы для постобработки текста. Применение алгоритмов, таких как коррекция орфографии и синтаксиса, позволяет уменьшить количество ошибок, возникающих при распознавании, и сделать результат более читаемым.
Каждая из этих настроек влияет на общую точность распознавания, и использование комбинации нескольких методов дает наилучший результат. Для достижения максимальной эффективности важно регулярно тестировать систему на разных типах аудио и корректировать параметры в зависимости от полученных данных.
Обработка шумов и улучшение качества аудио перед распознаванием
Для достижения высокой точности распознавания речи необходимо эффективно обрабатывать шумы в аудиофайле. Шумы могут значительно ухудшить качество распознавания, поэтому предварительная обработка звука играет ключевую роль. Существует несколько методов, которые позволяют улучшить качество аудио перед подачей его в систему распознавания речи.
- Фильтрация шума: Один из самых эффективных способов борьбы с фоновым шумом – использование алгоритмов фильтрации. Среди популярных методов выделяются:
- Фильтр Уиндерера: Применяется для удаления низкочастотных шумов, таких как гул вентиляторов или кондиционеров.
- Метод спектрального вычитания: Основан на оценке спектра шума в начале записи, после чего этот спектр вычитается из аудио.
- Генеративные методы: Использование нейронных сетей, таких как Denoising Autoencoders, позволяет удалять шумы, обучая модель на примерах шумных и чистых записей.
- Удаление эха: Для записи в помещениях с большим количеством отражающих поверхностей эхо становится существенной проблемой. Применение алгоритмов, таких как алгоритмы адаптивного фильтра, помогает минимизировать влияние эха и улучшить восприятие речи.
- Нормализация громкости: Аудиофайлы часто имеют различные уровни громкости. Нормализация позволяет выровнять уровень звука, устранив искажения, вызванные слишком высоким или низким уровнем сигнала. Для этого используют метод «peak normalization» или «RMS normalization», в зависимости от предпочтений.
- Экспансивная компрессия: Данный метод позволяет снизить разницу между тише звучащими и громкими частями аудио. Это помогает улучшить восприятие речи в условиях с переменным уровнем шума.
- Использование фреймирования и оконных функций: Разбиение аудиофайла на небольшие фреймы с последующим применением оконных функций (например, Хан или Хемминг) позволяет минимизировать эффекты артефактов и усилить нужные звуковые компоненты.
- Применение голосовых активностей: Использование алгоритмов Voice Activity Detection (VAD) помогает выявить и исключить участки без речи, такие как тишина или фоновые шумы. Это снижает объем обработки и улучшает точность распознавания речи.
Правильная комбинация этих методов позволяет значительно улучшить качество звука и повысить точность системы распознавания речи. Важно выбирать методы, которые соответствуют конкретной задаче и типу записи, чтобы достичь оптимального результата.
Сохранение и экспорт извлечённого текста в различные форматы
После извлечения текста из аудио с помощью Python важно сохранить результат в нужном формате для дальнейшего использования. В Python доступно несколько вариантов экспорта текста, каждый из которых имеет свои особенности и преимущества. Рассмотрим наиболее популярные форматы и методы их использования.
Первый и наиболее распространённый формат – это текстовый файл (.txt). Для сохранения текста в этом формате можно использовать встроенную функцию Python `open()`. Пример кода:
with open("output.txt", "w", encoding="utf-8") as file:
file.write(extracted_text)
Этот метод прост и универсален, подходя для большинства задач. Однако для более сложных случаев, например, если требуется сохранить форматирование или добавить метаинформацию, можно использовать формат .docx (Microsoft Word). Для работы с этим форматом удобно использовать библиотеку `python-docx`.
from docx import Document
doc = Document()
doc.add_paragraph(extracted_text)
doc.save("output.docx")
Если текст нужно экспортировать в формате PDF, можно воспользоваться библиотеками, такими как `reportlab` или `fpdf`. Для простого создания PDF-документов подходит `fpdf`:
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size=12)
pdf.multi_cell(0, 10, extracted_text)
pdf.output("output.pdf")
Для более профессиональных нужд или для создания сложных PDF-документов с изображениями и графикой можно использовать библиотеку `reportlab`, которая предоставляет широкий набор инструментов для работы с графическими элементами и форматированием.
Для работы с более структурированными данными, например, таблицами или метаданными, удобно использовать формат .csv (Comma-Separated Values). Для записи текста в .csv можно воспользоваться встроенной библиотекой `csv`:
import csv
with open("output.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([extracted_text])
Если текст требует дальнейшего анализа или обработки, и его необходимо сохранить в более гибком формате, хорошим выбором будет формат .json, который поддерживает вложенные структуры данных. Для записи текста в .json используется стандартная библиотека `json`:
import json
data = {"extracted_text": extracted_text}
with open("output.json", "w", encoding="utf-8") as file:
json.dump(data, file, ensure_ascii=False, indent=4)
В случае, когда текст нужно интегрировать в веб-приложение или предоставить его в виде API, возможно использование формата .html. Для этого можно создать простой HTML-документ с помощью библиотеки `html` или вручную создать строку с HTML-разметкой:
with open("output.html", "w", encoding="utf-8") as file:
file.write(html_content)
Каждый из этих форматов имеет свои особенности и области применения. Выбор зависит от того, как будет использоваться извлечённый текст и какие требования к его обработке и представлению.
Вопрос-ответ:
Какие библиотеки Python нужно использовать для извлечения слов из аудио?
Для извлечения слов из аудио с помощью Python часто используют библиотеки, такие как `SpeechRecognition` и `pydub`. `SpeechRecognition` позволяет работать с различными сервисами распознавания речи, например, Google Speech API, Microsoft Bing Voice Recognition или локальными движками. Библиотека `pydub` помогает в обработке аудио, например, в изменении формата или разделении на части. Также можно использовать другие инструменты для более сложных задач, например, `DeepSpeech` от Mozilla.
Как улучшить точность распознавания речи на Python?
Для улучшения точности распознавания речи на Python можно применять несколько методов. Во-первых, стоит использовать качественные аудиофайлы без шума. Важным аспектом является предобработка звука: например, фильтрация шума с помощью библиотеки `pydub`. Во-вторых, можно настроить параметры API для более точного распознавания речи, а также использовать специализированные модели для вашего языка или акцента, такие как модели от Google или `DeepSpeech` для более точного результата. Также полезно обучать модель на конкретных данных, если необходимо повысить точность для специфической тематики или терминологии.
Что такое модель DeepSpeech и как её использовать для извлечения слов из аудио?
Модель DeepSpeech — это система для распознавания речи, разработанная Mozilla. Она основана на нейронных сетях и может эффективно распознавать текст из аудио. Чтобы использовать DeepSpeech в Python, нужно сначала установить соответствующий пакет и загрузить модель. После этого аудиофайл передается на вход модели, и она генерирует текст. Важно заметить, что для работы с DeepSpeech потребуется достаточно мощное оборудование, особенно если нужно обрабатывать большие объемы данных в реальном времени.
Какие проблемы могут возникнуть при распознавании речи и как их решить?
При распознавании речи могут возникнуть различные проблемы, такие как помехи в аудио, низкое качество записи или акценты, которые сложны для стандартных моделей. Чтобы снизить влияние этих проблем, можно использовать фильтрацию шума или увеличить качество записи аудио. Также, если возникает проблема с распознаванием специфических терминов или акцентов, можно тренировать модель с использованием дополнительных данных или выбрать модели, лучше подходящие для конкретных условий. В случае плохой работы с акцентами можно попробовать использовать более специализированные движки, ориентированные на конкретный регион.