При работе с строками в Python важно учитывать, что стандартное сравнение строк чувствительно к регистру символов. Это означает, что строки с разным регистром считаются различными, даже если они по содержанию идентичны. Для многих задач, таких как обработка данных пользователей или текстового поиска, игнорирование регистра может существенно упростить работу. Python предоставляет несколько способов для реализации такого поведения, каждый из которых имеет свои особенности и применимость.
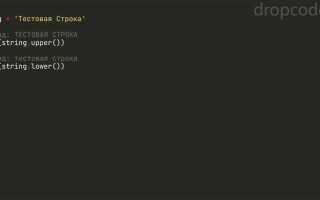
Первый и самый простой способ – это использование метода str.lower() или str.upper(). Эти методы преобразуют все символы строки в нижний или верхний регистр соответственно. После этого можно безопасно сравнивать строки без учета регистра. Такой подход эффективен для одноразовых сравнений, но его стоит избегать, если операции над строками выполняются часто, так как это может привести к излишним вычислениям.
Для более оптимизированных решений лучше использовать функции из модуля re, которые позволяют проводить регулярные выражения с игнорированием регистра. Использование флага re.IGNORECASE делает регулярные выражения нечувствительными к регистру, что удобно для поиска или замены текста в больших объемах данных.
Не стоит забывать, что в некоторых случаях игнорирование регистра может влиять на корректность работы алгоритмов, например, при проверке паролей или при сортировке. Всегда учитывайте контекст задачи, выбирая подходящий метод для сравнения строк.
Использование метода lower() для приведения строк к единому регистру
Метод lower() в Python используется для преобразования всех символов строки в нижний регистр. Это особенно полезно, когда необходимо игнорировать регистр при сравнении строк. Он изменяет строку без модификации оригинала, возвращая новую строку, где все символы приведены к нижнему регистру.
Пример использования метода:
text = "Hello World"
lower_text = text.lower()
Важно помнить, что метод lower() не изменяет исходную строку, а возвращает новую строку. Это позволяет избежать нежелательных изменений в оригинальных данных. Чтобы сравнить строки без учета регистра, можно использовать такой подход:
str1 = "Hello"
str2 = "hello"
if str1.lower() == str2.lower():
print("Строки равны")
Метод lower() идеально подходит для сравнений, где важен только смысл строк, а регистр не играет роли. Однако стоит помнить, что его использование может быть неэффективным для очень больших наборов данных, так как преобразование каждой строки требует дополнительных вычислительных ресурсов. В таких случаях рекомендуется проверять необходимость игнорирования регистра на уровне всей программы или алгоритма.
Кроме того, метод lower() работает корректно только с символами латинского алфавита. Для работы с другими языками (например, с кириллицей) он также будет корректно преобразовывать символы, но могут возникнуть исключения при использовании специфичных символов.
Как применить метод upper() для сравнения строк без учета регистра
Метод upper() в Python позволяет преобразовать все символы строки в заглавные. Этот подход удобен для сравнения строк без учета регистра, так как при его использовании все буквы становятся одинаковыми по регистру. Сравнение строк, приведённых к одному регистру, помогает избежать ошибок, связанных с различиями в написании символов.
Пример использования метода upper() для сравнения строк:
str1 = "Python"
str2 = "python"
if str1.upper() == str2.upper():
print("Строки одинаковы без учета регистра.")
else:
print("Строки различаются.")
В приведённом примере, несмотря на различия в регистрах, строки будут считаться равными после применения метода upper().
Этот метод может быть полезен в различных сценариях, например, при обработке пользовательского ввода, когда важно учесть только саму сущность строки, игнорируя её стиль написания.
Однако стоит учитывать, что метод upper() меняет все символы в строке, включая те, которые могут быть нечувствительны к регистру, например, символы в некоторых языках или специальные знаки. В таких случаях может быть более подходящим использование метода casefold(), который является более универсальным для игнорирования регистра при сравнении строк.
Использование метода casefold() для нормализации строк перед сравнением
Метод casefold() предназначен для нормализации строк перед их сравнением, особенно когда важно игнорировать различия в регистре символов. В отличие от метода lower(), который лишь преобразует символы в нижний регистр, casefold() применяется для более глубокой нормализации, обеспечивая корректное сравнение строк, учитывая особенности некоторых языков.
Основное отличие casefold() от lower() заключается в поддержке языковых нюансов. Например, в немецком языке буквы ß и ss считаются эквивалентными при сравнении, и метод casefold() учитывает это различие. Метод также подходит для строк, содержащих символы, где регистровая форма может влиять на результат сравнения.
Пример использования метода:
string1 = "Straße"
string2 = "strasse"
if string1.casefold() == string2.casefold():
print("Строки одинаковы.")
else:
print("Строки разные.")
В этом примере строки сравниваются с учетом локализации, что позволяет избежать ложных различий между символами, которые в других случаях могли бы привести к ошибочному результату.
Метод casefold() эффективен, когда необходимо провести сравнение строк, не учитывая регистр и местные особенности символов, что делает его более предпочтительным для международных приложений и систем, работающих с многозначными символами.
Применение регулярных выражений для игнорирования регистра при сравнении
Для игнорирования регистра при сравнении строк в Python можно использовать регулярные выражения. Модуль re предоставляет возможность учитывать или игнорировать регистр символов с помощью флагов. Это особенно полезно, когда необходимо сравнивать строки, не заботясь о различиях в верхнем и нижнем регистре.
В регулярных выражениях для игнорирования регистра применяется флаг re.IGNORECASE (или сокращенно re.I). Этот флаг заставляет регулярное выражение игнорировать различия между строчными и прописными буквами. Он применяется при вызове функции re.match(), re.search(), re.findall() и других.
Пример использования:
import re
pattern = r'hello'
string = 'HeLLo'
match = re.match(pattern, string, re.IGNORECASE)
if match:
print("Строки совпадают!")
else:
print("Строки не совпадают!")
Этот код выведет "Строки совпадают!", несмотря на различия в регистре символов.
Регулярные выражения позволяют также учитывать более сложные паттерны для поиска строк без учета регистра. Например, если нужно найти все вхождения слова "python", независимо от того, написано ли оно как "Python", "PYTHON" или "pyThOn", можно использовать следующий код:
pattern = r'python'
string = 'I love Python and PYTHON is awesome!'
matches = re.findall(pattern, string, re.IGNORECASE)
print(matches)
Результат будет следующим:
['Python', 'PYTHON']
Таким образом, использование флага re.IGNORECASE позволяет с легкостью искать и сравнивать строки, игнорируя различия в регистре.
Некоторые рекомендации:
- Используйте
re.IGNORECASE, когда необходимо выполнить регистронезависимый поиск в строках.
- Не стоит использовать этот флаг без необходимости, так как он может снизить производительность при обработке больших объемов данных.
- Регулярные выражения с флагом
re.IGNORECASE могут быть полезны при обработке пользовательского ввода или при поиске информации в текстах с неизвестным регистром.
Таким образом, регулярные выражения с флагом re.IGNORECASE – это мощный инструмент для работы с текстами, когда важно игнорировать различия в регистре символов.
Как сравнивать строки с учётом только буквенных символов, игнорируя регистр
При сравнении строк в Python важно учитывать, что часто необходимо игнорировать не только регистр символов, но и все не буквенные символы. Для этого можно использовать методы и функции, которые позволяют избавиться от чисел, пробелов, пунктуации и других символов, сохраняя только буквы в строках.
Первым шагом является приведение строк к единому регистру. Для этого применяются методы lower() или upper(), которые преобразуют все символы в строке в нижний или верхний регистр соответственно. Это гарантирует, что сравнение будет произведено без учёта регистра.
Для фильтрации только буквенных символов можно использовать регулярные выражения. Например, с помощью функции re.sub() можно удалить все символы, кроме букв. Регулярное выражение [^\w] удаляет все символы, кроме букв и цифр, но для нужд этого сравнения лучше использовать выражение [^a-zA-Z], чтобы оставить только буквы латинского алфавита, или расширить его для поддержки других алфавитов (например, кириллицы).
Пример кода:
import re
def normalize_string(s):
# Приводим строку к нижнему регистру и удаляем все не буквенные символы
return re.sub(r'[^a-zA-Zа-яА-Я]', '', s.lower())
# Пример сравнения
s1 = "Привет, мир!"
s2 = "привет мир"
if normalize_string(s1) == normalize_string(s2):
print("Строки одинаковы.")
else:
print("Строки разные.")
В этом примере строки приводятся к нижнему регистру, а затем удаляются все символы, не являющиеся буквами. После этого сравнение строк выполняется без учёта регистра и других символов, таких как запятые и пробелы.
Для случаев, когда необходимо учесть только буквы определённого алфавита или языка, можно адаптировать регулярное выражение. Например, для работы только с кириллицей достаточно использовать [^а-яА-Я], а для мультиязычных приложений – создать комплексное регулярное выражение, включающее диапазоны всех нужных символов.
Таким образом, применение комбинации методов для нормализации строк и фильтрации ненужных символов позволяет эффективно сравнивать строки с учётом только буквенных символов, игнорируя регистр.
Использование str.equals() для сравнения строк без учёта регистра

Метод str.equals() в Python не существует. Однако для сравнения строк без учёта регистра используется метод lower() или casefold(), который позволяет привести строки к одному регистру и затем сравнить их. Ниже рассматривается, как это сделать на практике.
Метод lower() преобразует все символы строки в нижний регистр. В отличие от него, casefold() является более универсальным, так как также учитывает культурные особенности, такие как различия в регистре в разных языках.
str.lower() – преобразует строку в нижний регистр, игнорируя большинство языковых особенностей.str.casefold() – приводит строку к стандартному виду, игнорируя особенности локализации и языка, например, в случае с немецким символом "ß".
Чтобы сравнить строки без учёта регистра, можно использовать следующий код:
string1 = "Python"
string2 = "python"
if string1.lower() == string2.lower():
print("Строки равны (игнорируя регистр)")
else:
print("Строки не равны")
Если вам нужно более точное сравнение, которое также учитывает языковые особенности, используйте casefold():
string1 = "straße"
string2 = "STRASSE"
if string1.casefold() == string2.casefold():
print("Строки равны (с учётом особенностей регистров)")
else:
print("Строки не равны")
Таким образом, использование lower() и casefold() позволяет корректно сравнивать строки, игнорируя различия в регистре. Метод casefold() стоит применять в ситуациях, когда важно учитывать особенности конкретных языков.
Как сравнивать строки в разных кодировках без учета регистра
Сравнение строк в Python по умолчанию чувствительно к регистру. Когда строки находятся в разных кодировках, корректное их сравнение без учета регистра может быть сложным. Важно учитывать особенности каждой кодировки, чтобы избежать ошибок.
Прежде всего, важно привести строки к одинаковой кодировке перед сравнением. Например, UTF-8 является универсальной и широко поддерживаемой кодировкой, поэтому рекомендуется использовать её для преобразования строк. Преобразование строки в одну и ту же кодировку может быть выполнено с помощью метода `.encode()` и функции `decode()`. Например:
str1 = "Текст".encode("utf-8")
str2 = "ТЕКСТ".encode("utf-8")
После того как строки приведены к единой кодировке, можно привести их к единому регистру. Это можно сделать с помощью метода `.lower()` или `.upper()`, чтобы игнорировать регистр при сравнении. Например:
str1 = "Текст".encode("utf-8").decode("utf-8").lower()
str2 = "ТЕКСТ".encode("utf-8").decode("utf-8").lower()
if str1 == str2:
print("Строки равны.")
else:
print("Строки не равны.")
Этот подход позволяет корректно сравнивать строки независимо от регистра и кодировки. Однако нужно учитывать, что кодировка может влиять на способ интерпретации символов. Например, при работе с UTF-8 и кириллицей могут возникнуть ситуации, когда различия в кодировке (например, UTF-16 или Windows-1251) могут привести к неочевидным результатам, если строки не приведены к одной и той же кодировке.
Кроме того, если вам нужно сравнивать строки с учётом локали (например, с учётом особенностей кириллицы в разных языках), можно использовать метод `locale.strxfrm()`, который учитывает языковую локализацию при сравнении строк. Для этого перед сравнением нужно установить нужную локаль:
import locale
locale.setlocale(locale.LC_COLLATE, "ru_RU.UTF-8")
str1 = "Текст"
str2 = "текст"
if locale.strxfrm(str1) == locale.strxfrm(str2):
print("Строки равны с учетом локали.")
else:
print("Строки не равны с учетом локали.")
Это решение полезно в случае, если вы хотите учитывать не только регистр, но и особенности сортировки и сравнения строк в разных языках и кодировках.
Рекомендации по выбору метода сравнения строк в зависимости от задач
При сравнении строк в Python необходимо учитывать контекст задачи. Методы сравнения могут существенно различаться по производительности, удобству использования и точности, поэтому важно выбрать оптимальный подход.
Если требуется провести сравнение строк без учета регистра, самым эффективным решением будет использование метода str.lower() или str.casefold(). Первый метод подходит для большинства случаев, когда сравниваемые строки используют стандартный набор символов. str.casefold() является более универсальным, так как корректно обрабатывает специфические символы, такие как диакритические знаки в некоторых языках.
Если необходимо проводить частое сравнение строк, например, при обработке большого объема данных, можно рассмотреть вариант использования re.compile() с регулярными выражениями, где можно указать флаг re.IGNORECASE. Это даст возможность гибко настраивать поведение при сравнении строк, например, исключая или учитывая различные варианты символов.
В ситуациях, когда требуется точное сравнение, например, при работе с паролями или проверке идентичности строк, стоит использовать стандартное сравнение с операторами == или !=. Это обеспечит полную точность и быстрое выполнение операции, так как Python эффективно работает с этими операторами на низком уровне.
Для задач, связанных с обработкой данных в различных локалях, рекомендуется использовать методы сравнения строк, поддерживающие локализацию, такие как str.lower() в сочетании с модулями locale или unicodedata. Это важно, если строки могут содержать символы, которые отличаются в разных языках или регионах.
Кроме того, если важна производительность и необходимо избегать излишних преобразований, стоит использовать методы с минимальными затратами на память, такие как непосредственное сравнение символов без изменения регистра строк. Однако это подходит только для случаев, когда регистр не влияет на результат.
Вопрос-ответ:
Чем отличается метод `.lower()` от `.casefold()` при сравнении строк в Python?
Методы `.lower()` и `.casefold()` оба преобразуют строку в нижний регистр, но есть небольшие различия. Метод `.lower()` изменяет регистр символов на стандартный для английского языка (например, буквы с диакритическими знаками могут не изменяться). В отличие от этого, `.casefold()` предназначен для более глубокого игнорирования регистра, например, он корректно обрабатывает символы, такие как немецкие буквы (например, 'ß' будет преобразован в 'ss'). Поэтому, если требуется учитывать такие особенности, лучше использовать `.casefold()`. В большинстве случаев оба метода дают одинаковый результат для английских строк.