Автоматизация тестирования и взаимодействия с веб-страницами часто сталкивается с задачей обхода капчи, которая используется для предотвращения действия ботов. В этой статье рассмотрим, как можно использовать Selenium в связке с Python для обхода таких механизмов защиты, что позволяет автоматизировать взаимодействие с сайтами, где капча блокирует доступ.
Для начала стоит понимать, что капча – это не единый механизм, а совокупность различных типов проверок: от простых текстовых задач до сложных изображений с различными символами. Selenium, как инструмент для управления браузером, позволяет эмулировать действия пользователя, что в ряде случаев дает возможность обойти такие механизмы. Однако важно помнить, что использование таких подходов должно быть законным и этичным, так как обход капчи может нарушать условия использования сайтов.
Для обхода капчи с помощью Selenium и Python часто применяются разные методы, в том числе использование сервисов для распознавания капчи, имитация пользовательского поведения или интеграция с API, которые решают капчу автоматически. Также важно учитывать, что не все капчи можно обойти таким способом, так как системы защиты постоянно совершенствуются. Чтобы минимизировать риск блокировки, необходимо тщательно выбирать методы и подходы, а также правильно конфигурировать драйверы Selenium для работы с различными типами капчи.
В следующем разделе мы подробнее разберем, как настроить Selenium для работы с капчей и какие инструменты можно использовать для автоматического решения задач безопасности.
Как настроить Selenium для работы с браузером и капчей
Для настройки Selenium и его использования с браузером важно правильно выбрать драйвер, настроить его для работы с браузером и учесть особенности обхода капчи.
Начнем с установки необходимых пакетов. Для работы с Selenium через Python потребуется установить сам Selenium и драйвер браузера. Для установки используйте команду:
pip install selenium
Для работы с конкретным браузером необходимо загрузить соответствующий драйвер. Например, для Chrome – это ChromeDriver, который можно скачать с официального сайта: https://sites.google.com/a/chromium.org/chromedriver/. Убедитесь, что версия драйвера соответствует версии установленного браузера. Драйвер необходимо поместить в папку, доступную для системы, или указать путь до него в настройках Selenium.
Чтобы запустить браузер, используйте следующий код:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='путь_к_chromedriver')
driver.get('https://example.com')
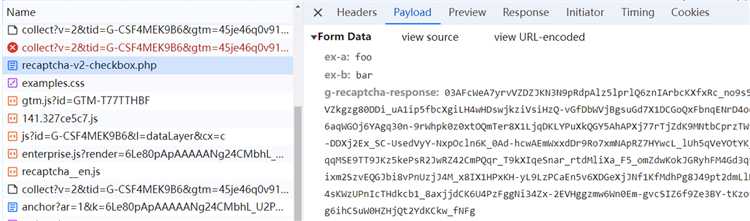
После настройки браузера для работы с капчей важно учесть, что современные сайты используют сложные механизмы защиты. Наиболее распространёнными являются reCAPTCHA от Google и hCaptcha. Их обход не является тривиальной задачей и зачастую требует дополнительной настройки.
Для обхода reCAPTCHA можно использовать сервисы для решения капчи, такие как 2Captcha или Anti-Captcha. Эти сервисы предоставляют API, с помощью которого можно отправить изображение капчи, получить ответ и передать его обратно на сайт. Для интеграции с Selenium и сервисами капчи используйте Python-библиотеки, предоставляемые этими сервисами.
Пример интеграции с 2Captcha:
import requests
from selenium import webdriver
API_KEY = 'ваш_api_ключ_2captcha'
site_key = 'site_key_сайта'
driver = webdriver.Chrome(executable_path='путь_к_chromedriver')
driver.get('https://example.com')
Получаем решение капчи
captcha_response = requests.post(
'http://2captcha.com/in.php',
data={'key': API_KEY, 'method': 'userrecaptcha', 'googlekey': site_key, 'pageurl': driver.current_url}
).text
Вставляем решение капчи в форму
driver.execute_script('document.getElementById("g-recaptcha-response").innerHTML = "{}";'.format(captcha_response))
driver.find_element_by_id('submit_button').click()
Для обхода hCaptcha потребуется немного другой подход. Характерной особенностью hCaptcha является то, что она может блокировать автоматические запросы, если не будет соблюдено несколько условий, таких как нормальное поведение пользователя (например, движение мыши). Один из способов решения hCaptcha – использование специализированных сервисов, таких как 2Captcha, которые предлагают решение именно для hCaptcha.
Важно помнить, что автоматический обход капчи нарушает условия использования большинства сервисов. Поэтому, перед применением подобных методов, тщательно изучите юридические аспекты и риски.
Использование прокси-серверов для обхода капчи в Selenium
Для обхода капчи с использованием Selenium часто применяют прокси-серверы, которые помогают скрыть реальный IP-адрес и распределить запросы между несколькими источниками. Это снижает вероятность блокировки аккаунта или IP-адреса, а также помогает имитировать действия различных пользователей.
Использование прокси-серверов позволяет развернуть систему, способную эффективно обходить капчи, минимизируя вероятность их появления. Чтобы настроить прокси-серверы в Selenium, необходимо учитывать несколько ключевых аспектов.
1. Типы прокси-серверов
Для успешного обхода капчи необходимо правильно выбрать тип прокси:
- Резидентные прокси – предоставляют IP-адреса реальных пользователей, что делает запросы менее подозрительными для веб-сайтов.
- Дата-центровые прокси – работают быстрее, но могут быть распознаны как автоматические запросы, что повышает шанс появления капчи.
- Мобильные прокси – имитируют устройства мобильных пользователей, что помогает обходить капчи, проверяющие устройства.
2. Настройка прокси в Selenium
Чтобы настроить использование прокси-сервера в Selenium, следует передать прокси в параметры браузера через WebDriver. Пример настройки для браузера Chrome:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://:')
driver = webdriver.Chrome(options=options)
driver.get("http://example.com")
Вместо
3. Использование ротирующих прокси
Для повышения эффективности рекомендуется использовать сервисы, которые предлагают ротирующие прокси-серверы. Эти прокси-серверы автоматически меняют IP-адрес через определенные интервалы времени или при каждом новом запросе, что значительно снижает вероятность того, что система зафиксирует аномальную активность и предложит капчу.
4. Оценка качества прокси
Не все прокси-серверы одинаково эффективны при обходе капчи. Важно выбирать проверенные сервисы с высокой пропускной способностью и качественным обслуживанием. Рекомендуется использовать прокси-серверы с низким временем отклика и высокой степенью анонимности.
- Анонимность: Прокси-сервер должен скрывать реальный IP-адрес, чтобы минимизировать шансы на обнаружение.
- Скорость: Прокси должны обеспечивать стабильную и быструю передачу данных, чтобы избежать замедления работы программы.
- Наличие капч-резистентных решений: Некоторые сервисы предоставляют прокси с функцией автоматического обхода капчи.
5. Подключение нескольких прокси-серверов
Для более сложных задач можно подключить несколько прокси-серверов и рандомизировать их использование. В Selenium это можно реализовать через создание списка прокси и использование случайного выбора при каждом запросе. Это помогает снизить вероятность того, что сайт заблокирует все запросы сразу.
import random
from selenium import webdriver
proxy_list = ["proxy1:port", "proxy2:port", "proxy3:port"]
proxy = random.choice(proxy_list)
options = webdriver.ChromeOptions()
options.add_argument(f'--proxy-server=http://{proxy}')
driver = webdriver.Chrome(options=options)
driver.get("http://example.com")
6. Проблемы с прокси и их решение
- Прокси заблокированы: Некоторые веб-сайты могут блокировать IP-адреса прокси-серверов. Для решения этой проблемы необходимо использовать более надежные или ротирующие прокси-серверы.
- Низкая скорость: Важно выбирать прокси с высокой пропускной способностью, так как низкая скорость может повлиять на эффективность обхода капчи.
Использование прокси-серверов значительно улучшает шансы на успешный обход капчи при автоматизированном тестировании с Selenium. Однако важно учитывать, что сам процесс обхода капчи может быть нарушением условий использования некоторых сайтов. Всегда проверяйте условия сайта и действуйте в рамках закона.
Решение капчи с помощью интеграции с сервисами распознавания изображений

Одним из популярных сервисов для автоматизации решения капчи является 2Captcha. Он предоставляет API, которое можно интегрировать в код на Python с помощью библиотек, таких как requests. После отправки изображения капчи на сервер, 2Captcha возвращает решение, которое затем может быть использовано для автоматического заполнения формы. Важным моментом является возможность обработки не только стандартных капч, но и сложных вариаций, например, с изображениями объектов.
Пример интеграции с 2Captcha выглядит следующим образом: необходимо сначала получить API-ключ, затем отправить изображение капчи на сервер через API и дождаться ответа с результатами распознавания. Для этого можно использовать библиотеку Python requests для отправки POST-запросов. Полученное решение капчи автоматически вставляется в нужное поле формы в Selenium.
Для повышения надежности распознавания можно использовать сервисы, которые предлагают дополнительные алгоритмы для работы с изображениями. Например, AntiCaptcha, которое поддерживает решение не только текстовых капч, но и капч с изображениями объектов или сложными геометрическими фигурами. Интеграция с такими сервисами позволяет повысить эффективность обхода капчи в проектах, где используются нестандартные типы защиты.
Необходимо учитывать, что автоматизация распознавания капчи с помощью таких сервисов имеет несколько ограничений. Во-первых, сервисы часто требуют, чтобы запросы поступали с определенной частотой, чтобы избежать блокировок. Во-вторых, качество распознавания может зависеть от сложности изображения. Чтобы повысить вероятность успешного решения, рекомендуется отправлять изображения в максимально возможном качестве и разрешении.
Также стоит отметить, что некоторые сервисы защиты, такие как reCAPTCHA v3, используют дополнительные методы проверки, которые не ограничиваются только изображениями, а могут включать анализ поведения пользователя. В таких случаях интеграция с сервисами распознавания изображений может быть неэффективной. Решение таких капч может потребовать использования более сложных методов, включая эмуляцию пользовательского поведения с помощью Selenium или других инструментов для работы с браузерами.
Таким образом, интеграция с сервисами распознавания изображений через Python и Selenium является мощным инструментом для обхода капчи. Однако для эффективного использования важно правильно выбрать сервис в зависимости от типа капчи, а также учитывать ограничения и особенности каждого конкретного случая.
Автоматизация обработки reCAPTCHA через API с Selenium
Первый шаг – регистрация на сервисе 2Captcha. После регистрации пользователю предоставляется уникальный API-ключ, который необходимо использовать для отправки запросов на решение капчи. Важно помнить, что работа с таким сервисом требует наличия действующего ключа и некоторых настроек, чтобы интеграция была успешной.
Далее, используя Selenium, необходимо имитировать действия пользователя на веб-странице с reCAPTCHA. Когда капча появляется, скрипт должен захватить необходимую информацию для отправки запроса на сервис 2Captcha. Это может включать URL страницы, тип капчи и данные, которые помогут сервису решить задачу.
Для получения решения капчи через API 2Captcha, необходимо выполнить POST-запрос на их сервер с нужными параметрами. В ответ будет получен ID задачи, который затем можно использовать для получения результата. Пример запроса с использованием Python выглядит так:
import requests
api_key = 'ваш_ключ_API'
site_key = 'site_key_капчи'
url = 'url_страницы_с_капчей'
response = requests.post('http://2captcha.com/in.php', data={
'key': api_key,
'method': 'userrecaptcha',
'googlekey': site_key,
'pageurl': url
})
task_id = response.text.split('|')[1]
После отправки запроса с задачей, необходимо периодически проверять состояние задачи, отправляя запросы с использованием ID задачи. После того как капча будет решена, сервис вернет вам ответ в виде текста, который можно вставить в поле формы на веб-странице.
Для извлечения решения капчи из ответа, можно использовать следующий код:
solution = requests.post('http://2captcha.com/res.php', data={
'key': api_key,
'action': 'get',
'id': task_id
}).text
if 'OK' in solution:
captcha_answer = solution.split('|')[1]
# вставить captcha_answer в поле формы с reCAPTCHA
После получения ответа от 2Captcha, остается лишь ввести его в поле reCAPTCHA и отправить форму. Важно помнить, что не всегда решение капчи будет успешным, и для минимизации ошибок, рекомендуется добавлять проверки и повторные попытки.
Таким образом, с использованием Selenium и API 2Captcha можно эффективно автоматизировать процесс обхода reCAPTCHA, значительно ускоряя работу с веб-страницами, требующими верификации пользователя.
Как использовать Selenium для обхода текстовых капч

Обход текстовых капч с использованием Selenium требует некоторых усилий и дополнительных инструментов, так как капчи предназначены для блокировки автоматических скриптов. Простой запуск браузера с Selenium не всегда решает проблему. Вот несколько шагов для реализации обхода текстовых капч.
Для начала, необходимо настроить Selenium для работы с браузером, используя Python. Важно, чтобы на устройстве был установлен драйвер для выбранного браузера, например, ChromeDriver для Google Chrome.
Пример кода для начала работы с Selenium:
from selenium import webdriver
driver = webdriver.Chrome(executable_path="путь_к_chromedriver")
driver.get("URL_с_капчей")
После запуска страницы с капчей, есть несколько вариантов обхода:
- Использование OCR (оптическое распознавание символов): Для распознавания текста на капче можно использовать библиотеки, такие как Tesseract. Эта техника позволяет извлечь текст с изображения капчи и передать его в форму для отправки.
Пример интеграции Tesseract с Selenium:
import pytesseract
from PIL import Image
from selenium.webdriver.common.by import By
Сделать скриншот капчи
captcha_image = driver.find_element(By.ID, "captcha_image_id")
captcha_image.screenshot("captcha.png")
Использовать pytesseract для распознавания текста
captcha_text = pytesseract.image_to_string(Image.open("captcha.png"))
- Использование сервисов для решения капч: Существует множество сервисов, таких как 2Captcha, AntiCaptcha, которые предоставляют API для решения текстовых капч. Эти сервисы используют реальных людей для разгадывания капч. Вы можете интегрировать их в Selenium-скрипт.
Пример использования 2Captcha:
import requests
API_KEY = "ваш_ключ_API_2Captcha"
Отправка капчи на решение
def solve_captcha(image_path):
with open(image_path, "rb") as image_file:
response = requests.post(
"http://2captcha.com/in.php",
files={"file": image_file},
data={"key": API_KEY, "method": "post"}
)
request_result = response.text.split('|')
if request_result[0] == "OK":
return request_result[1]
return None
После получения ответа от сервиса, текст капчи можно вставить в соответствующее поле формы:
captcha_answer = solve_captcha("captcha.png")
if captcha_answer:
captcha_input = driver.find_element(By.ID, "captcha_input")
captcha_input.send_keys(captcha_answer)
- Использование прокси и антидетект-методов: Некоторые сайты могут блокировать доступ через Selenium или определять использование автоматических скриптов. Для обхода этих ограничений можно использовать прокси-серверы или антидетект-расширения. Они помогают маскировать запросы, чтобы сайт не распознавал, что с ним взаимодействует бот.
Кроме того, стоит помнить, что решение капч с помощью скриптов может нарушать правила использования сайтов, что может привести к блокировке аккаунтов или IP-адресов. Поэтому важно учитывать эти риски при автоматизации таких процессов.
Снижение вероятности появления капчи при автоматизации браузера с Selenium

Чтобы уменьшить вероятность появления капчи при использовании Selenium, важно действовать в нескольких направлениях, контролируя поведение бота и mimicking действия реального пользователя. Здесь приводятся ключевые рекомендации, которые помогут сделать автоматизацию более «человечной».
1. Настройка пользовательского агента (User-Agent)
Многие сайты анализируют строку User-Agent для определения ботов. Применение стандартного агента, используемого Selenium, увеличивает шансы на попадание в фильтры капчи. Использование случайных или реальных строк User-Agent значительно снижает вероятность блокировки. Пример кода:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
driver = webdriver.Chrome(options=options)
2. Использование прокси
Ротация IP-адресов через прокси-серверы помогает избежать блокировок, связанных с подозрительной активностью с одного и того же IP. Прокси могут быть как приватными, так и публичными, но лучше использовать более стабильные и надежные варианты, чтобы избежать ограничений со стороны сайта. Использование «горячих» прокси, меняющихся через заданные интервалы времени, значительно снижает риски.
3. Эмуляция поведения реального пользователя
Чем больше вы имитируете действия реального пользователя, тем меньше шанс, что система обнаружит вас как бота. Для этого можно использовать методы, такие как случайные задержки между действиями, эмуляция движения мыши и прокрутки страницы. Пример реализации задержки:
import time
import random
time.sleep(random.uniform(1.5, 3.5))
4. Работа с cookies
Пропуск этапа авторизации или постоянное использование свежих cookies может повлиять на вероятность появления капчи. Сохранение и повторное использование cookies между сессиями позволяет создать впечатление стабильной активности реального пользователя.
5. Взаимодействие с элементами страницы
Боты, как правило, не взаимодействуют с элементами интерфейса так, как это делает человек. Например, прокачка действий пользователя, таких как скроллинг, щелчки на ссылках и элементы на странице, делает поведение менее предсказуемым для алгоритмов распознавания ботов.
6. Использование методов предотвращения блокировок
Некоторые сайты используют JavaScript для определения ботов. В таких случаях следует отключать использование JavaScript в браузере или использовать специальные антикапча-решения, если таковые доступны для вашего проекта.
7. Уменьшение частоты запросов
Избегайте слишком частых или интенсивных запросов. Это один из самых очевидных сигналов для антибот-системы. Оптимизация запросов, включая снижение частоты или распределение их по времени, поможет избежать подозрений.
Используя эти методы в сочетании, можно значительно уменьшить вероятность того, что ваш Selenium-скрипт будет заблокирован капчей. Секрет успешной автоматизации заключается в том, чтобы максимально точно имитировать поведение реального пользователя и избегать подозрительных паттернов, которые могут быть интерпретированы как действия бота.
Вопрос-ответ:
Что такое капча и почему её обход становится актуальным?
Капча — это система, используемая для проверки, что пользователь является человеком, а не автоматической программой. Она служит для предотвращения спама, ботов и защиты веб-сайтов от недобросовестных действий. Обход капчи становится актуальным, когда необходимо автоматизировать процессы на веб-сайтах, где эта система используется для защиты. Например, это может быть важно для сбора данных с сайтов или тестирования.
Как работает Selenium в контексте обхода капчи?
Selenium — это инструмент для автоматизации веб-браузеров. Он позволяет управлять браузером с помощью Python и симулировать действия пользователя, такие как клики и ввод текста. Для обхода капчи с Selenium можно использовать несколько методов, включая автоматическую передачу данных через API капчи, использование прокси-серверов или интеграцию с сервисами распознавания капчи. Однако, важно отметить, что этот процесс может требовать дополнительной настройки и времени для корректной работы.
Какие существуют способы обхода капчи с помощью Python?
Существует несколько способов обхода капчи с использованием Python. Один из самых популярных — это использование библиотек, которые автоматически решают капчу, например, через сервисы распознавания изображений или текстов, такие как 2Captcha. Другим методом является использование прокси-серверов для маскировки IP-адресов, что помогает избежать блокировок. Также можно пробовать использовать headless-режим браузера с Selenium для симуляции действий реального пользователя и обхода простых капч.
Какие проблемы могут возникнуть при автоматическом обходе капчи с помощью Selenium?
При автоматическом обходе капчи могут возникать следующие проблемы: сложность в распознавании капчи, особенно если используется нестандартная форма или текст. Также сервисы распознавания капчи могут требовать оплату, что делает решение этой задачи не всегда выгодным. Некоторые сайты могут блокировать ваши IP-адреса, если они заметят попытки автоматического обхода, что приведет к необходимости использования прокси-серверов. Кроме того, использование таких методов может нарушать правила сайта, что может привести к юридическим последствиям.
Можно ли полностью автоматизировать решение капчи с помощью Selenium и Python?
Полностью автоматизировать решение капчи с помощью Selenium и Python не всегда возможно, поскольку современные капчи используют различные технологии, такие как анализ поведения пользователя или распознавание движения мыши, чтобы отличить ботов от людей. Тем не менее, для простых типов капчи, например, текстовых или изображений с буквами и цифрами, можно использовать сервисы распознавания капчи, такие как 2Captcha или AntiCaptcha, чтобы ускорить процесс. Для сложных капч, таких как reCAPTCHA, требуется больше усилий и, возможно, использование машинного обучения или человеческих решений.
Как обойти капчу с помощью Selenium и Python?
Для обхода капчи с использованием Selenium и Python существует несколько методов. Один из них — это использование рекапчи с внешними сервисами, которые предлагают API для автоматического решения капчи. Важно помнить, что использование таких методов должно быть этичным и соответствовать правилам сервисов. В процессе работы с Selenium необходимо сначала загрузить страницу с капчей, а затем использовать API для ее решения. Далее можно продолжить выполнение автоматизированных действий с сайтом. Также возможно применение метода проксирования и введения капчи вручную в случае сложных алгоритмов защиты. Однако стоит помнить, что не все решения капчи будут работать на разных типах защиты, и некоторые сайты могут применить дополнительные методы для предотвращения автоматических действий.
Как можно обойти капчу, если она активно препятствует автоматическому доступу?
Если капча активно блокирует автоматический доступ, существует несколько вариантов, которые можно использовать. Один из них — это использование сторонних сервисов для распознавания капчи, таких как 2Captcha или Anti-Captcha. Эти сервисы предлагают решения для различных типов капч, включая reCAPTCHA. Принцип работы заключается в том, что запрос на решение капчи отправляется на сервис, где его решает реальный человек, и возвращается ответ, который Selenium может использовать для автоматического заполнения формы. Также можно применить методы использования прокси-серверов для обхода блокировок, а для некоторых типов капчи возможно создание собственного алгоритма распознавания с использованием библиотек для машинного обучения, таких как TensorFlow или OpenCV. Однако следует помнить, что такие подходы могут быть не всегда легальными или этичными, в зависимости от политики сайта.