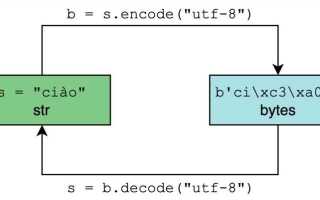
Определение кодировки файла – важная задача при работе с текстовыми данными. Несоответствие кодировки может привести к некорректному отображению текста или возникновению ошибок при его обработке. В Python существует несколько подходов для решения этой задачи, каждый из которых имеет свои особенности и области применения.
Часто используемые библиотеки для определения кодировки включают chardet и cchardet, а также стандартный модуль codecs. Библиотека chardet является одной из самых популярных, обеспечивая автоматическое определение кодировки с высокой точностью. Однако важно помнить, что она может ошибаться, особенно при работе с небольшими файлами или файлами, содержащими текст в нескольких кодировках.
Для начала работы с chardet достаточно установить библиотеку с помощью команды pip install chardet и использовать ее для анализа файла. Однако даже при использовании chardet не всегда возможно получить стопроцентно точный результат, и всегда полезно проверять результат вручную, если есть сомнения.
Кроме того, можно использовать стандартный модуль codecs, который позволяет открывать файлы в разных кодировках, но не всегда предоставляет возможность детектировать кодировку. В некоторых случаях полезно комбинировать методы из разных библиотек для повышения точности анализа.
Правильный выбор метода зависит от задач, с которыми вы столкнулись. Например, для автоматического извлечения кодировки из больших объемов данных, где ошибка может привести к серьезным последствиям, лучше воспользоваться более сложными и надежными решениями, таким как chardet или cchardet.
Как использовать модуль chardet для определения кодировки
pip install chardetОсновной функцией модуля является chardet.detect(), которая принимает на вход байтовую строку и возвращает результат в виде словаря с определённой кодировкой. Рассмотрим пример:
import chardet
# Открытие файла в бинарном режиме
with open('example.txt', 'rb') as file:
data = file.read()
# Определение кодировки
result = chardet.detect(data)
print(result)
Метод detect() возвращает словарь, который включает:
- encoding – определённая кодировка;
- confidence – степень уверенности в правильности распознавания (от 0 до 1);
- language – язык текста (не всегда присутствует и не всегда точен).
В большинстве случаев, определение кодировки происходит быстро и точно, но бывают исключения. Например, если текст содержит смешанные кодировки или слишком маленькие объёмы данных, точность может снизиться.
Для работы с большими объёмами данных и для повышения точности можно передавать в chardet.detect() фрагменты текста, а не весь файл. Это полезно в случае, когда файл слишком большой для обработки целиком:
with open('large_file.txt', 'rb') as file:
chunk = file.read(1024) # Чтение 1024 байтов
result = chardet.detect(chunk)
print(result)
Важно помнить, что chardet не всегда может точно распознать кодировку, особенно если данные повреждены или кодировки имеют схожие характеристики. В таких случаях рекомендуется использовать дополнительные методы для проверки, например, пробное открытие файла с предположенной кодировкой или использование других инструментов.
Также можно комбинировать chardet с другими библиотеками для повышения надёжности, например, использовать модуль codecs для безопасного открытия файлов с подозрительной кодировкой:
import codecs
# Пример использования с предполагаемой кодировкой
with codecs.open('example.txt', 'r', encoding='utf-8', errors='replace') as file:
text = file.read()
Таким образом, модуль chardet остаётся одним из самых удобных и простых инструментов для распознавания кодировок в Python, особенно при работе с неизвестными или смешанными кодировками.
Применение метода `open()` для автодетекции кодировки
Метод `open()` в Python может быть использован для автоматического определения кодировки файла с помощью параметра `encoding`. Вместо того чтобы заранее указывать кодировку, можно воспользоваться функцией `chardet` или встроенными возможностями Python для определения типа кодировки. Однако, начиная с версии Python 3.10, появился способ автодетекции кодировки непосредственно при открытии файла, что значительно упрощает работу с файлами, чья кодировка заранее неизвестна.
Применение этого метода возможно благодаря модулю `open()` с использованием аргумента `encoding=’auto’`. Однако стоит отметить, что Python использует библиотеку `utf-8` по умолчанию, что подразумевает необходимость наличия явной настройки в случае других кодировок.
Для примера, можно открыть файл без явного указания кодировки, и Python сам попытается определить кодировку на основе содержимого файла. Однако в таких случаях часто возникают проблемы с нестандартными или редкими кодировками, которые могут быть неправильно интерпретированы. Поэтому при работе с текстовыми файлами, чьи кодировки могут сильно отличаться, рекомендуется использовать внешние библиотеки.
Пример использования `open()` с автодетекцией кодировки:
import chardet
def read_file_auto(file_path):
with open(file_path, 'rb') as file:
raw_data = file.read()
result = chardet.detect(raw_data)
encoding = result['encoding']
with open(file_path, 'r', encoding=encoding) as file:
return file.read()
В этом примере файл сначала открывается в бинарном режиме (`’rb’`), что позволяет зафиксировать необработанные данные для анализа. Библиотека `chardet` анализирует их и определяет наиболее подходящую кодировку. После этого файл открывается заново, но уже в режиме текстового чтения с кодировкой, полученной через автодетекцию.
Также стоит упомянуть, что метод `open()` в Python может повлиять на производительность при работе с большими файлами, поскольку открытие в бинарном режиме и последующий анализ данных требуют дополнительных вычислительных ресурсов. В таких случаях важно тестировать работу скриптов на больших объемах данных и выбирать оптимальные подходы к обработке файлов.
Как использовать кодировку при открытии файла с помощью библиотеки codecs
Библиотека codecs позволяет явно указать кодировку при работе с файлами, что особенно полезно при чтении текста в нестандартных кодировках, таких как cp1251 или utf-16. Это предотвращает ошибки декодирования, которые могут возникнуть при использовании встроенной функции open().
Для открытия файла в нужной кодировке используется функция codecs.open(), синтаксис которой аналогичен стандартной функции open(), но с обязательным указанием параметра encoding.
import codecs
with codecs.open('example.txt', 'r', encoding='cp1251') as f:
content = f.read()
print(content)Режим 'r' указывает на чтение. Можно также использовать режимы 'w' или 'a' для записи или добавления. Если файл содержит BOM (Byte Order Mark), библиотека codecs автоматически определит порядок байтов при использовании кодировок utf-16 и utf-32.
При записи текста важно указывать кодировку явно, чтобы избежать несовместимости при последующем чтении:
with codecs.open('output.txt', 'w', encoding='utf-8') as f:
f.write('Текст на русском')Использование codecs оправдано при работе с файлами, где кодировка известна заранее или отличается от utf-8, которая используется по умолчанию в большинстве современных систем.
Алгоритм работы с UTF-8 и проблематика BOM
UTF-8 – переменно-длина кодировка, где символ может занимать от одного до четырёх байт. При этом последовательность байтов однозначно определяет границы символов. Однако некоторые редакторы и системы добавляют в начало файла специальные три байта – BOM (Byte Order Mark): 0xEF, 0xBB, 0xBF. Эта сигнатура не требуется по стандарту UTF-8 и может вызывать ошибки при обработке.
Для корректной работы с такими файлами следует учитывать наличие BOM при открытии. В Python utf-8-sig позволяет автоматически удалить BOM при чтении:
with open("example.txt", "r", encoding="utf-8-sig") as f:
content = f.read()
Если открыть файл с обычной utf-8, BOM останется в начале строки как невидимый символ \ufeff, что может привести к сбоям при сравнении строк или разборе заголовков CSV.
При записи файлов в UTF-8 рекомендуется использовать utf-8 без сигнатуры, чтобы избежать лишних байтов в начале. В случае необходимости добавления BOM (например, для совместимости с Excel), можно явно указать кодировку:
with open("output.csv", "w", encoding="utf-8-sig") as f:
f.write("column1,column2\nvalue1,value2")
Чтобы определить наличие BOM без чтения всего файла, можно проверить первые три байта:
with open("file.txt", "rb") as f:
start = f.read(3)
has_bom = start == b'\xef\xbb\xbf'
Поддержка BOM в UTF-8 остаётся спорной: она не влияет на порядок байтов, как в UTF-16, и чаще всего мешает. Рекомендуется избегать её добавления, если в этом нет конкретной необходимости.
Как определить кодировку с использованием библиотеки cchardet
Библиотека cchardet представляет собой высокопроизводительный аналог chardet, реализованный на C++. Она подходит для обработки больших объёмов данных, где важна скорость.
Для начала установите пакет:
pip install cchardetПример использования:
import cchardet
with open('файл.txt', 'rb') as f:
raw_data = f.read()
result = cchardet.detect(raw_data)
print(result)
Функция detect возвращает словарь с ключами ‘encoding’ и ‘confidence’. Первый содержит предполагаемую кодировку, второй – степень уверенности от 0 до 1. Например:
{'encoding': 'windows-1251', 'confidence': 0.99}Для повышения точности не обрабатывайте слишком короткие фрагменты – предпочтительно считывать не менее нескольких килобайт. Также избегайте чтения по частям – cchardet работает лучше при анализе всего содержимого сразу.
Обработка ошибок при неправильной кодировке в Python

При открытии файлов с некорректно указанной кодировкой часто возникает ошибка UnicodeDecodeError. Чтобы избежать прерывания выполнения программы, используйте обработку исключений и указание поведения при ошибках.
- Для подавления ошибок чтения можно использовать параметр
errors='ignore':
with open('файл.txt', encoding='utf-8', errors='ignore') as f:
данные = f.read()errors='replace'заменяет некорректные символы на�:
with open('файл.txt', encoding='utf-8', errors='replace') as f:
данные = f.read()try:
with open('файл.txt', encoding='utf-8') as f:
данные = f.read()
except UnicodeDecodeError as e:
print(f'Ошибка декодирования: {e}') # позиция и байт вызвавший ошибку- Модуль
chardetилиcharset-normalizerпозволяет определить предполагаемую кодировку перед чтением:
from charset_normalizer import from_path
результат = from_path('файл.txt').best()
with open('файл.txt', encoding=результат.encoding) as f:
данные = f.read()- Если файл содержит перемешанные кодировки, безопаснее обрабатывать его построчно:
with open('файл.txt', encoding='utf-8', errors='replace') as f:
for строка in f:
обработать(строка)Как проверить кодировку через системные утилиты и Python
В Unix-подобных системах можно использовать команду file с параметром -i или --mime-encoding. Пример:
file -i имя_файла.txt
В Windows можно установить chardet или charset-normalizer для Python и использовать их через скрипт. Пример с chardet:
python -m chardet имя_файла.txt
Аналогичная команда с charset-normalizer:
python -m charset_normalizer имя_файла.txt
В Python код можно реализовать так:
import chardet
with open("имя_файла.txt", "rb") as f:
данные = f.read()
результат = chardet.detect(данные)
print(результ['encoding'], результат['confidence'])Если используется charset-normalizer:
from charset_normalizer import from_path
результаты = from_path("имя_файла.txt")
лучший = результаты.best()
print(лучший.encoding, лучший.fingerprint)Для точности стоит проверять не менее 1-2 КБ содержимого. Если файл однороден (например, только цифры или латиница), автоопределение может дать некорректный результат. В таких случаях стоит сверять результат с предполагаемой локалью системы или анализировать вручную с учётом контекста использования.
Практическое применение: выбор кодировки для обработки текста
При работе с текстовыми файлами выбор кодировки зависит от источника данных и требований к совместимости. Если файл поступает из Windows-среды, чаще всего используется кодировка Windows-1251 (для русскоязычных данных). В Unix-системах по умолчанию применяется UTF-8.
Если необходимо обеспечить совместимость с веб-приложениями, предпочтительнее использовать UTF-8 без BOM, поскольку большинство браузеров и API ожидают именно эту кодировку. Для старых XML-документов или программ, требующих указания кодировки, может потребоваться UTF-8 с BOM или UTF-16.
В случае обработки больших массивов архивных данных, возможно, потребуется анализ содержимого и использование библиотеки chardet или charset-normalizer для автоматического определения кодировки. Например:
from charset_normalizer import from_path
result = from_path('example.txt')
encoding = result.best().encoding
Если файл содержит кириллицу и при открытии в UTF-8 возникают ошибки UnicodeDecodeError, стоит проверить его в Windows-1251 или KOI8-R. Часто встречающиеся фрагменты, такие как ‘Ð’, ‘Ñ’, ‘Ã’, указывают на неправильное чтение UTF-8 как Latin-1.
При сохранении результатов анализа или экспорта данных рекомендуется явно задавать кодировку:
with open('output.txt', 'w', encoding='utf-8') as f:
f.write(text)Если ожидается взаимодействие с Excel, следует использовать UTF-8 с BOM:
with open('excel_export.csv', 'w', encoding='utf-8-sig') as f:
f.write(csv_content)Для систем, где нет уверенности в поддержке Unicode, можно использовать Latin-1, но только если текст ограничен базовым латинским алфавитом.
Сводка рекомендаций:
| Сценарий | Рекомендуемая кодировка |
|---|---|
| Файлы из Windows | Windows-1251 |
| Файлы из Unix/Linux | UTF-8 |
| Совместимость с вебом | UTF-8 без BOM |
| Совместимость с Excel | UTF-8 с BOM (utf-8-sig) |
| Только латиница | Latin-1 |
| Неизвестная кодировка | Автоопределение через charset-normalizer |