Циан – один из крупнейших сайтов недвижимости в России, который ежедневно обновляет тысячи объявлений о продаже и аренде жилья. Парсинг данных с таких ресурсов позволяет эффективно собирать актуальную информацию, анализировать рынок недвижимости, а также интегрировать полученные данные в различные системы или сервисы. С помощью Python можно автоматизировать процесс сбора информации с Циан, используя библиотеку requests для запросов и BeautifulSoup для извлечения данных.
Первый шаг в парсинге – это правильная настройка HTTP-запросов, чтобы сайт не заблокировал ваши попытки. Важно подбирать заголовки и параметры запросов так, чтобы они имитировали действия реального пользователя. Также стоит учесть использование сессий, что позволит избежать частых блокировок со стороны сервера.
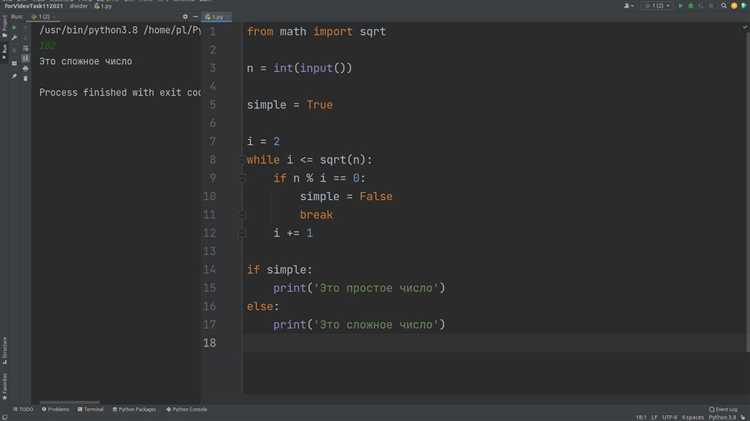
После того как запросы настроены, необходимо приступить к извлечению нужных данных. Для этого можно использовать BeautifulSoup, которая позволяет работать с HTML-разметкой и извлекать текстовые и структурированные данные, такие как стоимость, описание и фотографии. Важно помнить о возможных динамических данных на сайте, которые загружаются через JavaScript, что требует применения дополнительных инструментов, таких как Selenium.
Настройка окружения для парсинга: установка библиотек
Для успешного парсинга объявлений с сайта Циан потребуется несколько ключевых библиотек. Рассмотрим шаги по установке необходимых инструментов.
Первая библиотека, которую следует установить, – это requests. Она используется для отправки HTTP-запросов и получения данных с веб-страниц. Установить её можно с помощью команды:
pip install requests
Вторая важная библиотека – BeautifulSoup из пакета bs4, которая предназначена для парсинга HTML-кода. С её помощью можно извлекать нужные данные из полученных HTML-страниц. Для установки используйте команду:
pip install beautifulsoup4
Для более сложной работы с динамическими сайтами, где контент загружается с помощью JavaScript, понадобится библиотека selenium. Она позволяет автоматизировать взаимодействие с веб-страницами, например, кликать по элементам или прокручивать страницу. Установить её можно так:
pip install selenium
Если вы планируете работать с JavaScript-контентом, то также потребуется установить драйвер для браузера, например, ChromeDriver, соответствующий версии вашего браузера. Драйвер можно скачать с официального сайта и указать путь к нему в коде.
pip install pandas
Для работы с заголовками и метками HTTP-респондера удобно использовать библиотеку lxml, которая ускоряет процесс парсинга и работы с XML и HTML. Установить её можно командой:
pip install lxml
После установки этих библиотек, ваш инструмент парсинга будет готов к использованию. Важно следить за актуальностью версий библиотек, чтобы избежать ошибок совместимости в процессе разработки.
Использование requests для запроса данных с сайта

Библиотека requests позволяет отправлять HTTP-запросы к страницам Циан и получать HTML-код для последующего парсинга. Для корректной работы важно указать заголовки, имитирующие поведение браузера, иначе сервер может вернуть пустой ответ или перенаправить на капчу.
Пример базового GET-запроса к списку объявлений:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Accept-Language": "ru-RU,ru;q=0.9",
}
url = "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2®ion=1"
response = requests.get(url, headers=headers)
if response.status_code == 200:
html = response.text
else:
print(f"Ошибка запроса: {response.status_code}")
Обязательно контролировать статус ответа (response.status_code). Циан может возвращать 403 Forbidden при отсутствии заголовков или превышении количества запросов. Рекомендуется использовать задержки между запросами от 1 до 3 секунд, чтобы избежать бана.
Полезно логировать ответы и сохранять исходный HTML на диск для отладки:
with open("page.html", "w", encoding="utf-8") as f:
f.write(response.text)
Циан активно применяет защиту от ботов. Рекомендуется использовать прокси и менять User-Agent при большом количестве запросов. Ниже пример структуры рекомендованных заголовков:
| Заголовок | Значение |
|---|---|
| User-Agent | Имитирует браузер Chrome |
| Accept-Language | ru-RU,ru;q=0.9 |
| Connection | keep-alive |
| Upgrade-Insecure-Requests | 1 |
При необходимости аутентификации можно использовать requests.Session() для сохранения cookies между запросами. Это особенно полезно при работе с фильтрами или сохранёнными поисками на аккаунте пользователя.
Парсинг HTML-страниц с BeautifulSoup

Для извлечения информации с Циан необходимо сначала загрузить HTML-код страницы. Используйте библиотеку requests с заголовками User-Agent, имитирующими поведение браузера, чтобы избежать блокировок. Пример: headers = {"User-Agent": "Mozilla/5.0 ..."}.
После получения HTML-ответа создайте объект парсера: soup = BeautifulSoup(response.text, "html.parser"). Используйте метод soup.select() для точечного выбора элементов через CSS-селекторы. Для поиска заголовков объявлений: soup.select("div._93444fe79c--content--lVZ2h h3"). Для цены: soup.select("span._93444fe79c--price--lRU8S").
Перед парсингом рекомендуется сохранить HTML в файл для локальной отладки: with open("sample.html", "w", encoding="utf-8"). Это помогает анализировать структуру без постоянных запросов к серверу.
При работе с вложенными элементами используйте метод find() внутри циклов: item.find("span", class_="..."). Преобразуйте текст к нужному виду, удаляя пробелы и символы: price_text.replace("₽", "").replace("\xa0", "").strip().
Для обхода динамического контента, подгружаемого через JavaScript, BeautifulSoup бесполезен. Используйте requests-html или Selenium в таких случаях, но в рамках Циан большая часть данных доступна в статичном HTML.
Обращайте внимание на структуру классов: Циан использует нестабильные, автогенерируемые имена классов. Рекомендуется искать устойчивые маркеры, такие как наличие ключевых слов в тексте или атрибутов data-*.
Извлечение нужной информации: фильтрация и обработка данных
Первым шагом является выбор нужных элементов страницы для извлечения. В случае с Циан, это могут быть такие данные, как цена, площадь, количество комнат, расположение объекта и другие характеристики. Для этого удобно использовать библиотеки BeautifulSoup и Requests. Например, можно настроить фильтрацию по классу или id, которые однозначно соответствуют данным, необходимым для анализа.
После извлечения данных важно их структурировать. Простая форма, например, в виде списка или словаря, позволит более эффективно работать с данными в дальнейшем. Для хранения часто используют pandas DataFrame, что позволяет легко манипулировать данными и проводить необходимые преобразования.
Для обработки строковых данных можно использовать регулярные выражения, чтобы избавиться от лишних символов (например, валютных знаков или пробелов) и привести данные к нужному формату. Это особенно актуально для цен, которые могут быть представлены в разных форматах (с пробелами, с валютными знаками или без них).
Фильтрация данных также включает в себя удаление дубликатов. Это может быть важно, если несколько объявлений повторяются в результатах поиска. Простая команда drop_duplicates() в pandas позволит быстро избавиться от повторяющихся строк.
Важной частью обработки данных является проверка их корректности. Для этого стоит использовать регулярные выражения для проверки формата цен, а также диапазоны значений для числовых данных, например, площади или количества комнат. Если данные не соответствуют ожиданиям, их можно отбросить или исправить с помощью заданных алгоритмов.
Для дальнейшего анализа часто требуется сгруппировать данные по определенным признакам, например, по районам или ценовым категориям. В таких случаях удобно использовать функцию groupby() из pandas для агрегирования информации по нужным критериям.
Важно также настроить систему сохранения и обновления данных. Можно реализовать механизм, который будет периодически парсить новые объявления, обновляя базу данных, и фильтровать только те, которые соответствуют заранее заданным критериям. Для этого потребуется настроить регулярные запросы и фильтрацию данных по времени размещения объявлений или их актуальности.
Обработка пагинации для сбора всех объявлений
Для эффективного сбора данных с сайта Циан необходимо учесть, что объявления разделены на несколько страниц. Пагинация на сайте организована через номера страниц в URL или через динамическую подгрузку данных при прокрутке. В обоих случаях важно правильно обрабатывать переходы по страницам для сбора всех доступных данных.
В большинстве случаев пагинация реализована с использованием параметра в URL, например, page=1. Для корректного сбора всех объявлений необходимо перебирать все страницы, начиная с первой и заканчивая последней, которая может изменяться в зависимости от количества объявлений.
- Используйте цикл для перебора страниц. Например, если номер страницы начинается с 1 и увеличивается на 1, можно создать цикл до максимального значения.
- Для динамической загрузки контента используйте библиотеку Selenium, которая позволяет обрабатывать JavaScript и отслеживать подгрузку новых элементов при прокрутке.
Для определения последней страницы можно использовать несколько подходов:
- Посмотреть на общий количество объявлений и вычислить число страниц, исходя из стандартной пагинации (например, 20 объявлений на странице).
- Использовать информацию о последней странице, доступную на сайте, в некоторых случаях это может быть явный элемент в HTML-коде.
- Отслеживать изменения в URL или элементы на странице, которые указывают на последнюю страницу.
Пример обработки пагинации с использованием библиотеки BeautifulSoup:
import requests
from bs4 import BeautifulSoup
base_url = 'https://www.cian.ru/rent/'
page_number = 1
while True:
url = f"{base_url}?page={page_number}"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Обработка объявлений на текущей странице
ads = soup.find_all('div', class_='c6e8ba6cfe-idpJHz')
if not ads:
break # Если объявления не найдены, значит, мы на последней странице
for ad in ads:
# Извлечение данных из каждого объявления
pass
page_number += 1При использовании Selenium для обработки динамической пагинации следует учитывать, что сайт может подгружать новые объявления по мере прокрутки. В этом случае лучше использовать механизм ожидания и прокрутки страницы до конца перед сбором данных:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
driver.get('https://www.cian.ru/rent/')
# Ожидание загрузки страницы
time.sleep(3)
# Прокрутка страницы до конца
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
time.sleep(3) # Ждем, пока контент подгрузится
# Сбор данных
ads = driver.find_elements(By.CLASS_NAME, 'c6e8ba6cfe-idpJHz')
for ad in ads:
# Извлечение данных из каждого объявления
pass
driver.quit()Важно следить за корректностью работы пагинации, особенно при изменении структуры сайта. Тестирование на разных страницах и настройка таймеров помогут избежать пропуска данных при динамическом подгрузке.
Сохранение данных в формат CSV или базу данных
После того как данные с объявлений на Циан собраны с помощью парсера, их необходимо сохранить для дальнейшего использования. Это можно сделать двумя основными способами: в формате CSV или в базе данных. Каждый метод имеет свои особенности и зависит от объема данных и целей обработки.
Для сохранения в CSV используется стандартный модуль Python – csv, который позволяет быстро записывать данные в текстовый файл, разделённый запятыми. Это удобный способ для небольших объёмов данных, когда важно получить доступ к данным в табличном формате.
- CSV легко открыть в Excel или другом табличном редакторе.
- Файл можно легко передать между различными системами.
- Не требует установки дополнительных библиотек, так как является стандартной частью Python.
Пример записи данных в CSV:
import csv
data = [
{"title": "Квартира 1", "price": 30000, "location": "Москва"},
{"title": "Квартира 2", "price": 45000, "location": "Петербург"}
]
with open('announcements.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=["title", "price", "location"])
writer.writeheader()
for row in data:
writer.writerow(row)
Для хранения данных в более структурированном виде или для работы с большими объёмами данных лучше использовать базу данных, например, SQLite или PostgreSQL. Это позволяет эффективно управлять и обновлять данные, а также выполнять сложные запросы и фильтрацию.
- SQLite идеально подходит для небольших проектов, так как не требует настройки серверной базы данных.
- PostgreSQL подойдёт для крупных проектов, где необходимо хранить миллионы записей и обеспечивать высокую производительность запросов.
- С помощью SQL можно создавать таблицы, индексы и связывать данные в разные сущности.
Пример сохранения данных в SQLite:
import sqlite3
# Создание базы данных и таблицы
conn = sqlite3.connect('announcements.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS announcements (
id INTEGER PRIMARY KEY,
title TEXT,
price INTEGER,
location TEXT
)
''')
# Добавление данных в таблицу
data = [
{"title": "Квартира 1", "price": 30000, "location": "Москва"},
{"title": "Квартира 2", "price": 45000, "location": "Петербург"}
]
for row in data:
cursor.execute('''
INSERT INTO announcements (title, price, location)
VALUES (?, ?, ?)
''', (row['title'], row['price'], row['location']))
conn.commit()
conn.close()
Использование базы данных позволяет не только эффективно управлять данными, но и проводить различные операции, такие как сортировка, фильтрация и объединение данных, что может быть полезно при анализе объявлений.
Если требуется интеграция с другими сервисами или обеспечение высокой доступности, можно рассмотреть использование более сложных СУБД, таких как MySQL или PostgreSQL, в которых предусмотрены механизмы репликации, безопасности и масштабирования. Однако для большинства задач SQLite и CSV подходят оптимально.
Как обойти защиту от парсинга на Циан
Циан применяет несколько методов защиты от автоматического парсинга, чтобы защитить свою платформу от излишней нагрузки и нежелательной активности. Однако с определёнными подходами можно обойти эти защиты. Рассмотрим основные методы, которые можно использовать при парсинге данных с сайта Циан.
1. Использование прокси-серверов
Циан отслеживает IP-адреса и может блокировать подозрительные обращения, исходящие с одного и того же IP. Чтобы избежать блокировки, стоит использовать прокси-серверы. Это позволит скрыть реальный IP-адрес и распределить запросы между несколькими адресами. Важно использовать как можно больше прокси, чтобы уменьшить шанс блокировки. Лучше всего работать с прокси-серверами, которые меняют IP на каждой сессии, так как это ещё больше усложнит задачу защиты.
2. Эмуляция поведения человека
Циан использует капчи, поведение ботов и частоту запросов для идентификации автоматических систем. Чтобы обойти эту защиту, следует эмулировать поведение реального пользователя. Можно использовать библиотеки, такие как selenium, для симуляции кликов, прокрутки страниц и задержек между запросами. Это поможет снизить вероятность блокировки за подозрительную активность. Также рекомендуется рандомизировать интервалы между запросами, чтобы имитировать человеческие паузы.
3. Мимикрия заголовков HTTP
Циан может проверять заголовки запросов, и если они не соответствуют стандартному поведению браузеров, сайт может распознать бота. Для обхода защиты можно изменять заголовки HTTP, чтобы они соответствовали тем, которые отправляются реальным браузером. Примеры таких заголовков включают User-Agent, Referer, и Accept-Language. Использование реальных данных из браузера повысит вероятность успешного парсинга.
4. Работа с JavaScript
Циан активно использует JavaScript для динамической подгрузки данных, что усложняет парсинг с использованием обычных библиотек для HTTP-запросов. Чтобы обойти эту защиту, можно использовать инструменты, такие как selenium или playwright, которые могут выполнять JavaScript на странице, загружать контент и извлекать необходимые данные. Эти библиотеки позволяют работать с сайтами, которые генерируют контент через JavaScript, и предоставляют возможности для имитации реального поведения пользователя.
5. Постепенный сбор данных
Для минимизации риска блокировки важно собирать данные постепенно, а не за один сеанс. Лучше планировать парсинг на длительный период времени, разбивая запросы на небольшие пакеты. Использование временных задержек между запросами позволит избежать выявления неестественной активности и снизить вероятность блокировки со стороны сервера.
6. Обработка капчи
Циан активно использует капчи для защиты от ботов. Для автоматического обхода капчи можно использовать сервисы решения капчи, такие как 2Captcha или Anti-Captcha. Эти сервисы предоставляют API для решения капчи в реальном времени, что позволяет продолжить парсинг без вмешательства человека.
7. Использование API
Если доступно официальное API для получения данных, стоит воспользоваться им. Циан предоставляет API для некоторых категорий данных, что значительно упростит процесс получения информации и исключит риски, связанные с парсингом веб-страниц. Однако важно учитывать, что для использования API могут быть ограничения по частоте запросов, поэтому для большого объёма данных придётся адаптировать систему сбора информации.
8. Мониторинг изменений защиты
Платформы, такие как Циан, постоянно обновляют свои системы защиты от ботов. Важно следить за изменениями в их политике безопасности. Например, могут появляться новые методы защиты, такие как изменение структуры страниц или введение новых типов капчи. Регулярный анализ изменений на сайте поможет адаптировать парсинг под актуальные условия.
Вопрос-ответ:
Что такое парсинг объявлений с Циан и как это работает?
Парсинг объявлений с Циан — это процесс извлечения информации с веб-страниц сайта Циан с помощью программных средств. С помощью Python можно использовать библиотеки, такие как BeautifulSoup и Requests, чтобы программно загрузить страницы и извлечь нужные данные, например, цену, описание, площадь квартиры и контактные данные. Процесс начинается с того, что с помощью запросов загружается HTML-код страницы, который затем обрабатывается, чтобы выделить важную информацию.
Какие Python-библиотеки используются для парсинга Циан?
Для парсинга данных с сайта Циан часто используют несколько популярных библиотек. Одна из них — это BeautifulSoup, которая помогает обрабатывать HTML-код страниц. Вместе с ней часто используется Requests для отправки HTTP-запросов к сайту и получения данных. Еще одной полезной библиотекой является Selenium, которая позволяет работать с динамическими веб-страницами, на которых данные загружаются с помощью JavaScript. Эти инструменты помогают эффективно собирать нужную информацию из различных разделов сайта.
Как избежать блокировки при парсинге с Циан?
Чтобы избежать блокировки при парсинге с Циан, необходимо соблюдать несколько рекомендаций. Во-первых, не стоит отправлять слишком много запросов за короткий промежуток времени. Для этого можно использовать задержки между запросами или случайные интервалы, чтобы сделать действия более естественными. Во-вторых, можно использовать прокси-серверы, чтобы скрыть свой реальный IP-адрес. В-третьих, важно соблюдать правила сайта, не нарушая их условия использования. Также рекомендуется использовать заголовки User-Agent, чтобы имитировать запросы от реальных пользователей.
Какие данные можно собрать с сайта Циан при парсинге?
При парсинге с сайта Циан можно собрать различные данные, такие как информация о квартире или доме: цена, площадь, количество комнат, этаж, тип дома, местоположение, описание объявления и фотографии. Также можно извлечь контактные данные, например, телефон или ссылку на профиль владельца. Важно помнить, что доступность и точность данных могут зависеть от формата самого сайта и структуры страницы.
Как автоматизировать процесс парсинга на Python?
Для автоматизации парсинга с Циан на Python можно создать скрипт, который будет запускаться по расписанию, например, с помощью библиотеки schedule. Скрипт будет подключаться к сайту, извлекать актуальные данные и сохранять их в файл или базу данных. Можно настроить регулярные обновления, чтобы каждый день собирать новые объявления. Для этого скрипт будет использовать библиотеки Requests или Selenium для получения страниц, а BeautifulSoup для анализа и извлечения информации.