

Регулярные выражения (или regex) в JavaScript используются для работы с текстовыми строками. Это мощный инструмент для поиска, замены, валидации данных и других операций с текстом. Правильное использование регулярных выражений позволяет значительно повысить производительность кода и избежать повторяющихся решений.
Основы синтаксиса регулярных выражений в JavaScript основываются на паттернах, которые состоят из символов и метасимволов. Для создания регулярного выражения в JavaScript используют два способа: через литерал (например, /abc/) или через конструктор RegExp (new RegExp('abc')). Литералы проще и удобнее, но конструктор может быть полезен, если необходимо динамически генерировать регулярные выражения.
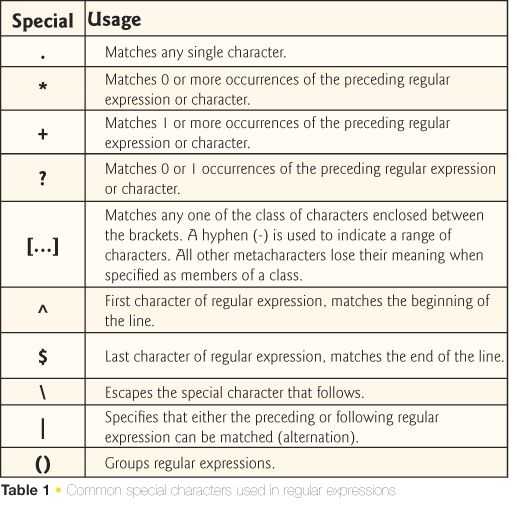
Для составления регулярного выражения важна точность: метасимволы, такие как \d (цифры), \w (буквы и цифры), или ^ (начало строки) позволяют задавать точные условия для поиска. Использование модификаторов, таких как g (глобальный поиск) или i (игнорировать регистр), расширяет функциональность регулярных выражений, что делает их еще более гибкими и мощными.
Рекомендации по созданию регулярных выражений:
- Тестируйте регулярные выражения с помощью встроенных инструментов браузера или онлайн-платформ для отладки.
- Избегайте излишней сложности: чем проще и понятнее выражение, тем проще его поддерживать.
- Оптимизируйте выражения для производительности, избегая чрезмерного использования повторяющихся элементов.
В следующем разделе мы подробно рассмотрим создание регулярных выражений для разных случаев, включая поиск по строкам, замену текста и валидацию ввода пользователя.
Как использовать литеральный синтаксис для создания регулярного выражения

Литеральный синтаксис регулярных выражений в JavaScript предоставляет удобный и компактный способ создания регулярных выражений. Он позволяет избежать использования конструктора RegExp, делая код более читаемым и кратким.
Для использования литерального синтаксиса регулярное выражение помещается между двумя косыми чертами /.... Например:
/abc/Такое выражение будет искать строку "abc" в тестируемом тексте. Литеральный синтаксис предпочтительнее, когда регулярное выражение известно заранее и не требует динамического построения.
Примеры литеральных регулярных выражений
/\d+/– находит одно или несколько чисел (цифр) подряд./^abc/– находит строку, начинающуюся с"abc"./abc$/– находит строку, заканчивающуюся на"abc"./\bword\b/– ищет слово "word", при этом оно будет ограничено границами слова.
Внимание: если в выражении используются специальные символы, такие как +, *, ?, ., [, ], (, ), \, их необходимо экранировать с помощью обратного слэша. Например, чтобы найти точку, используйте /\./ вместо /./.
Преимущества использования литерального синтаксиса

- Читаемость: код становится проще для восприятия, так как не нужно использовать конструктор
RegExp. - Производительность: литеральный синтаксис более быстрый, так как регулярное выражение компилируется один раз при загрузке скрипта.
- Наглядность: выражение сразу видно и не требует дополнительных манипуляций.
Литеральный синтаксис удобен в случае статичных выражений. Для динамических регулярных выражений, например, когда паттерн создается на основе данных, лучше использовать конструктор RegExp.
Как задать флаги регулярного выражения в JavaScript
Флаги регулярного выражения в JavaScript позволяют изменять поведение поиска. Их можно указать сразу после закрывающего слэша, непосредственно за паттерном. В языке JavaScript доступны следующие флаги:
g – глобальный поиск. При использовании этого флага регулярное выражение ищет все совпадения в строке, а не только первое.
i – игнорирование регистра. Этот флаг позволяет регулярному выражению находить совпадения без учета регистра символов (например, "a" и "A" будут равны).
m – многострочный режим. Включает поддержку многострочного поиска. Он изменяет поведение метасимволов ^ и $, позволяя им работать не только с началом и концом всей строки, но и с началом и концом каждой строки внутри многострочного текста.
s – режим "dotall". Флаг позволяет символу точки . матчить все символы, включая символы новой строки.
u – поддержка юникодных символов. Этот флаг необходим для работы с символами в юникоде, которые могут состоять из нескольких байтов.
y – "поиск с привязкой". Этот флаг изменяет поведение регулярного выражения так, чтобы поиск начинался только с позиции в строке, на которой завершился предыдущий поиск.
Флаги можно комбинировать, указывая их в любом порядке. Например, выражение /abc/i будет искать все вхождения "abc" в строке, игнорируя регистр символов. Для комбинированного использования можно написать, например, /abc/gmi, что включает глобальный поиск, игнорирование регистра и многострочный режим.
Важно помнить, что при использовании флагов производительность регулярных выражений может изменяться. Например, флаг g может быть менее эффективным для больших текстов, так как поисковая операция должна быть выполнена несколько раз.
Для проверки или изменения флагов регулярного выражения после его создания, можно использовать свойство flags, которое возвращает строку с текущими активными флагами.
Как использовать методы test() и exec() для проверки строк

Метод test() проверяет, соответствует ли строка заданному регулярному выражению. Он возвращает логическое значение: true, если совпадение найдено, и false, если нет. Этот метод полезен, когда нужно просто проверить, есть ли в строке определённый паттерн, не извлекая саму информацию.
Пример использования test():
const regex = /\d+/;
const str = "Текст с числом 1234.";
console.log(regex.test(str)); // trueМетод exec() выполняет более глубокую операцию. Он ищет совпадение и, если находит, возвращает массив, содержащий саму строку совпадения и дополнительную информацию, такую как индексы начала и конца совпадения. В отличие от test(), exec() возвращает не просто логическое значение, а массив с результатами, что делает его удобным для извлечения данных из строки.
Пример использования exec():
const regex = /\d+/;
const str = "Текст с числом 1234.";
const result = regex.exec(str);
console.log(result); // ["1234", index: 16, input: "Текст с числом 1234.", groups: undefined]Важное отличие: если регулярное выражение использует флаг g (глобальный поиск), то exec() будет искать все совпадения по очереди, возвращая результаты при каждом вызове. Для таких случаев обычно используют цикл, чтобы извлечь все совпадения.
Пример с флагом g:
const regex = /\d+/g;
const str = "Числа: 12, 34 и 56.";
let result;
while ((result = regex.exec(str)) !== null) {
console.log(result[0]); // 12, затем 34, затем 56
}Метод test() проще и быстрее, если требуется просто проверить наличие совпадений. exec() более гибок и подходит, если нужно получить дополнительную информацию о совпадении или извлечь несколько результатов.
Как извлекать данные с помощью регулярных выражений в JavaScript
Для извлечения данных из строк с помощью регулярных выражений в JavaScript используется метод match() и функции работы с группами захвата. Это позволяет выделять нужные части строки, соответствующие шаблону регулярного выражения.
1. Метод match(): используется для извлечения совпадений. Если регулярное выражение имеет глобальный флаг g, метод вернет массив всех совпадений, в противном случае – только первое совпадение.
Пример:
const text = "Я учусь в университете с 2020 года.";
const regex = /\d{4}/; // ищем год
const result = text.match(regex);
console.log(result); // ["2020"]
2. Группы захвата: в регулярных выражениях можно использовать круглые скобки для создания групп. Эти группы позволяют захватывать подстроки, которые можно использовать отдельно от остальной части совпадения.
Пример:
const text = "Ее имя – Анна, ей 25 лет.";
const regex = /(\w+), ей (\d+) лет/;
const result = text.match(regex);
console.log(result[1]); // "Анна"
console.log(result[2]); // "25"
3. Использование exec(): этот метод работает подобно match(), но он возвращает подробную информацию о совпадении и группах захвата. Он особенно полезен при регулярных выражениях с флагом g, когда необходимо обработать все совпадения поочередно.
Пример:
const text = "Apple, Banana, Cherry";
const regex = /(\w+),/g;
let result;
while ((result = regex.exec(text)) !== null) {
console.log(result[1]);
}
4. Метод replace(): позволяет не только заменить часть строки, но и извлекать данные, если в качестве второго аргумента используется функция. Эта функция получает все группы захвата как параметры.
Пример:
const text = "Цена товара 1000 рублей.";
const regex = /(\d+) рублей/;
const result = text.replace(regex, (match, number) => {
return `Цена товара: ${number} единиц`;
});
console.log(result); // "Цена товара: 1000 единиц"
5. Применение split(): метод split() с регулярным выражением позволяет разделить строку на части, используя шаблон в качестве разделителя. Этот способ полезен, когда нужно извлечь элементы, разделенные одинаковыми признаками (например, запятыми или пробелами).
Пример:
const text = "apple, banana, cherry";
const regex = /\s*,\s*/; // удаление пробелов вокруг запятой
const result = text.split(regex);
console.log(result); // ["apple", "banana", "cherry"]
При правильном использовании регулярных выражений можно эффективно извлекать данные, будь то числа, слова или целые фразы. Важно понимать, какие методы и флаги использовать для достижения наилучшего результата в зависимости от требований задачи.
Как избежать распространённых ошибок при работе с регулярными выражениями

Регулярные выражения (regex) в JavaScript могут быть мощным инструментом для поиска и обработки строк, но они требуют осторожности. Неправильное использование может привести к ошибкам и сложным для отладки ситуациям. Вот несколько советов, которые помогут избежать распространённых ошибок при работе с регулярными выражениями.
1. Не забывайте экранировать специальные символы
Регулярные выражения содержат несколько символов с особыми значениями, например, точка (.) или звездочка (*). Если их не экранировать, они могут не выполнять желаемую функцию. Например, символ "точка" в regex означает "любой символ", а не буквальную точку. Чтобы использовать точку как обычный символ, необходимо экранировать её, добавив обратный слэш: \.
2. Не используйте регулярные выражения без флагов в случаях, когда это нужно
По умолчанию регулярные выражения в JavaScript работают только с первым совпадением в строке. Для поиска всех совпадений необходимо использовать флаг g. Например, выражение /\d+/g найдет все числа в строке, в отличие от /\d+/, которое найдет только первое число.
3. Тщательно проверяйте границы строк
Для поиска в начале или в конце строки используйте границы ^ (начало) и $ (конец). Без них выражение будет искать совпадения в любой части строки. Например, выражение /test/ найдет "test" в любой части строки, тогда как /^test/ найдет только в начале.
4. Используйте группы правильно
При работе с группами важно понимать, что они могут захватывать часть строки, что может повлиять на последующие операции. Для простого поиска без захвата используйте (?: ... ). Например, выражение /(?:abc)/ будет искать "abc", но не создавать отдельную группу.
5. Проверяйте свой regex с помощью инструментов
При написании регулярных выражений используйте онлайн-инструменты для тестирования, такие как regex101. Эти инструменты покажут, как работает ваше выражение, и помогут избежать логических ошибок.
6. Не игнорируйте производительность
Сложные регулярные выражения могут быть очень медленными, особенно при работе с большими строками. Постоянные операции поиска или замены могут сильно замедлить выполнение программы. Лучше избегать чрезмерно сложных выражений, таких как выражения с несколькими вложенными квантификаторами, которые могут привести к экспоненциальному времени выполнения.
7. Осторожно с глобальными и мультирежимными флагами
Использование флага g может изменить поведение некоторых методов, таких как test() и exec(). Например, после первого применения регулярного выражения с флагом g, индикатор поиска будет продолжать искать с того места, где остановился. Это может привести к неожиданным результатам, если вы не очищаете внутренний указатель регулярного выражения.
8. Понимание порядка выполнения выражений
Порядок выполнения квантификаторов важен для корректности работы регулярного выражения. Например, выражение /a*b/ будет пытаться найти ноль или более символов "a", после которых следует "b". Но если вы поменяете порядок на /b*a/, поиск изменится, и будут найдены все случаи, где "b" может предшествовать "a".
Как оптимизировать регулярные выражения для производительности в JavaScript

Оптимизация регулярных выражений в JavaScript критична для повышения производительности, особенно при работе с большими объемами данных. Ниже приведены рекомендации по улучшению их эффективности.
- Использование литералов вместо конструктора: Создание регулярных выражений с помощью литералов ({/pattern/}) быстрее, чем через конструктор RegExp, так как литералы компилируются один раз, а конструктор – каждый раз при вызове.
- Избегание ненужных групп: Часто в регулярных выражениях используются ненужные группы (с круглыми скобками), которые могут замедлить выполнение. Если вам не нужно сохранять результаты группы, замените их на необязательные символы или другие оптимальные конструкции.
- Снижение сложности паттернов: Чем сложнее регулярное выражение, тем дольше его выполнение. Избегайте использования больших наборов символов в квадратных скобках, особенно если они охватывают широкий диапазон символов. Используйте точные символы там, где это возможно.
- Минимизация использования квантов ".*": Квантификаторы ".*" и ".*?" часто приводят к «жадным» операциям, что может сильно замедлить работу. Вместо этого используйте более конкретные паттерны, например, точное количество символов или более специфические символы.
- Использование флагов с умом: Флаги, такие как "g" (глобальный) и "i" (нечувствительность к регистру), могут повлиять на производительность. Флаг "g" может ускорить обработку, если нужно искать все совпадения, но его чрезмерное использование без нужды приведет к лишней нагрузке.
- Использование кэширования: Регулярные выражения можно кэшировать, чтобы избежать их повторной компиляции при многократных вызовах. Это полезно, когда одно и то же регулярное выражение используется несколько раз в одном и том же контексте.
- Регулярные выражения с фиксированной длиной: Если регулярное выражение имеет заранее известную длину строки, это может ускорить его обработку. Например, фиксированное количество символов (например, "^[a-zA-Z0-9]{10}$") будет выполнено быстрее, чем использование множества символов.
- Оптимизация структуры выражений: Использование альтернатив (|) может значительно замедлить выполнение, если паттерны сильно различаются. Лучше оптимизировать их, чтобы минимизировать количество альтернатив, используя комбинацию других операторов, таких как "?" и "+".
Следуя этим рекомендациям, можно существенно повысить производительность регулярных выражений в JavaScript, что особенно важно при обработке больших объемов данных или в реальном времени.
Вопрос-ответ:
Что такое регулярные выражения в JavaScript?
Регулярные выражения в JavaScript — это мощный инструмент для поиска и обработки текста, который позволяет находить совпадения с заданными шаблонами в строках. Они представляют собой особый синтаксис, который включает символы и метасимволы для указания, какие символы должны быть найдены в тексте. Регулярные выражения используются, например, для проверки форматов данных, таких как адреса электронной почты или номера телефонов.
Как создать регулярное выражение в JavaScript?
В JavaScript регулярное выражение можно создать двумя способами: с помощью литерального синтаксиса или конструктора `RegExp`. Литерал выглядит так: `/шаблон/`, а через конструктор — `new RegExp('шаблон')`. Например, регулярное выражение для поиска всех цифр в строке можно записать как `/\d+/` или `new RegExp('\\d+')`.
Как использовать регулярные выражения для валидации email-адреса в JavaScript?
Для проверки правильности email-адреса можно использовать регулярное выражение, которое проверяет стандартный формат. Пример простого выражения для валидации email: `/^[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$/`. Это регулярное выражение проверяет, чтобы адрес начинался с букв, цифр или спецсимволов, за которым следует символ `@`, домен и окончание в виде точки и доменной зоны (например, `.com`).





