Работа с парами данных, где один список представляет ключи, а другой – значения, встречается довольно часто при программировании на Python. Если вам нужно эффективно создать словарь из двух списков, важно понимать, как это сделать правильно и без лишних вычислительных затрат. Python предлагает несколько способов решения этой задачи, каждый из которых имеет свои особенности.
Наиболее очевидным методом является использование встроенной функции zip(). Эта функция объединяет два списка в кортежи, где каждый кортеж содержит элемент из первого списка и элемент из второго. Затем можно применить dict() для преобразования этих кортежей в словарь. Такой способ отличается высокой читаемостью и часто используется в повседневной практике Python-разработчиков.
Однако стоит учитывать, что если списки имеют разную длину, zip() остановится на минимальной длине. Это может привести к потере данных, если один из списков длиннее другого. В таких случаях можно воспользоваться itertools.zip_longest, которая позволяет дополнить более короткий список значениями по умолчанию.
Кроме того, для создания словаря можно использовать генераторы, которые позволяют написать более компактный и гибкий код, а также улучшить производительность при обработке больших данных.
Использование функции zip для создания словаря
Функция zip в Python позволяет эффективно объединить два списка в пары, где элементы из первого списка будут соответствовать элементам из второго. Это идеальный способ для создания словаря, где элементы первого списка станут ключами, а элементы второго – значениями. Рассмотрим, как это работает на практике.
Для начала нужно понять, как работает функция zip. Она принимает два или более итерируемых объекта и возвращает итератор, который генерирует кортежи, состоящие из элементов, соответствующих индексам из каждого из переданных объектов. Например:
list1 = ['a', 'b', 'c']
list2 = [1, 2, 3]
zipped = zip(list1, list2)
print(list(zipped)) # [('a', 1), ('b', 2), ('c', 3)]Теперь, чтобы преобразовать эти пары в словарь, достаточно передать результат работы zip в функцию dict:
dictionary = dict(zip(list1, list2))
print(dictionary) # {'a': 1, 'b': 2, 'c': 3}В данном примере list1 содержит ключи, а list2 – соответствующие значения. Если длины списков различаются, то функция zip завершит объединение по длине самого короткого списка. Если важно учесть все элементы, можно использовать itertools.zip_longest, которая заполнит недостающие значения по умолчанию:
from itertools import zip_longest
list1 = ['a', 'b', 'c']
list2 = [1, 2]
dictionary = dict(zip_longest(list1, list2, fillvalue=None))
print(dictionary) # {'a': 1, 'b': 2, 'c': None}Этот метод идеально подходит для быстрого и компактного создания словаря из двух списков. Главное – убедиться, что порядок элементов в списках имеет значение, так как ключи и значения будут связаны согласно их порядку в исходных коллекциях.
Как обработать разные длины списков при создании словаря
Когда два списка, из которых нужно создать словарь, имеют разную длину, необходимо заранее предусмотреть стратегию обработки такого случая. Стандартный подход с использованием функции zip() не подходит, так как она объединяет элементы списков до самой короткой длины. Это может привести к потере данных, если один список длиннее другого.
Для обработки ситуации с различными длинами списков можно использовать несколько вариантов:
1. Обрезка лишних элементов
Если важно сохранить только элементы, которые могут быть сопоставлены, можно воспользоваться функцией zip() для объединения элементов списков и создания словаря. Элементы лишнего списка будут проигнорированы. Например, если список ключей длиннее, то только столько пар будет создано, сколько элементов в списке значений:
keys = ['a', 'b', 'c']
values = [1, 2]
result = dict(zip(keys, values)) # {'a': 1, 'b': 2}
2. Заполнение отсутствующих значений значением по умолчанию
Если необходимо сохранить все элементы из обоих списков, можно использовать функцию itertools.zip_longest(), которая позволяет заполнять недостающие элементы значением по умолчанию, например, None, для того, чтобы избежать потери данных:
from itertools import zip_longest
keys = ['a', 'b', 'c']
values = [1, 2]
result = dict(zip_longest(keys, values, fillvalue=None)) # {'a': 1, 'b': 2, 'c': None}
3. Применение пользовательской логики для несовпадающих длин
В случае, если требуется более сложная логика для обработки различных длин списков (например, циклическое повторение значений), можно написать собственную функцию для объединения списков:
def custom_zip(keys, values, fillvalue=None):
result = {}
len_diff = len(keys) - len(values)
if len_diff > 0:
values.extend([fillvalue] * len_diff)
elif len_diff < 0:
keys.extend([fillvalue] * -len_diff)
for k, v in zip(keys, values):
result[k] = v
return result
keys = ['a', 'b', 'c']
values = [1, 2]
result = custom_zip(keys, values, fillvalue='default') # {'a': 1, 'b': 2, 'c': 'default'}
Таким образом, для обработки различных длин списков можно выбрать подход, который наилучшим образом соответствует задаче: либо обрезать лишние элементы, либо использовать значение по умолчанию, либо реализовать собственную логику для объединения данных.
Перевод списка кортежей в словарь с помощью dict()
Пример использования:
data = [('a', 1), ('b', 2), ('c', 3)]
result = dict(data)
print(result)Этот код создаст словарь {'a': 1, 'b': 2, 'c': 3}. Важно, чтобы каждый кортеж имел ровно два элемента: первый элемент будет ключом, второй – значением. Если кортежи будут содержать больше или меньше элементов, возникнет ошибка.
Если в списке кортежей встречаются дублирующиеся ключи, то в словаре останется только последнее значение, связанное с этим ключом. Например:
data = [('a', 1), ('b', 2), ('a', 3)]
result = dict(data)
print(result)Результат будет таким: {'a': 3, 'b': 2}. Пара ('a', 1) будет перезаписана значением 3, так как это последняя встречающаяся пара с ключом 'a'.
Функция dict() является удобным и быстрым методом для конвертации списка кортежей в словарь, особенно когда данные структурированы в таком виде и требуется быстро получить доступ к значениям по ключу.
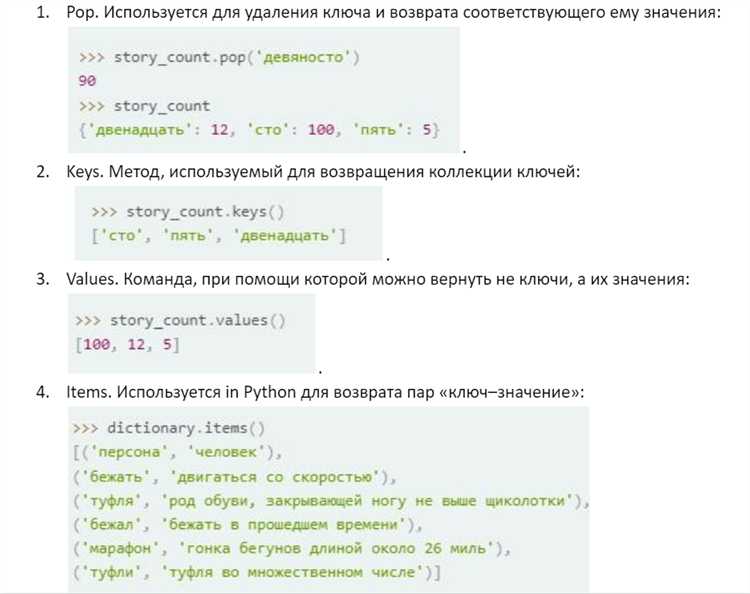
Как справиться с повторяющимися ключами при создании словаря
При создании словаря из двух списков в Python может возникнуть ситуация, когда один или несколько ключей повторяются. По умолчанию Python сохраняет только последний встреченный элемент для каждого ключа. Это может быть проблемой, если необходимо сохранить все значения для повторяющихся ключей. Существует несколько способов решить эту задачу.
- Использование defaultdict: Это один из самых простых методов. Класс
defaultdictиз модуляcollectionsпозволяет автоматически создавать списки для каждого нового ключа, в который можно добавлять значения.
from collections import defaultdict
keys = ['a', 'b', 'a', 'c']
values = [1, 2, 3, 4]
result = defaultdict(list)
for key, value in zip(keys, values):
result[key].append(value)
print(dict(result))
Результат: {'a': [1, 3], 'b': [2], 'c': [4]}
keys = ['a', 'b', 'a', 'c']
values = [1, 2, 3, 4]
result = {}
for key, value in zip(keys, values):
if key not in result:
result[key] = [value]
else:
result[key].append(value)
print(result)
Результат: {'a': [1, 3], 'b': [2], 'c': [4]}
pandas, можно создать словарь с группировкой значений по ключам с помощью метода groupby.
import pandas as pd
keys = ['a', 'b', 'a', 'c']
values = [1, 2, 3, 4]
df = pd.DataFrame({'key': keys, 'value': values})
result = df.groupby('key')['value'].apply(list).to_dict()
print(result)
Результат: {'a': [1, 3], 'b': [2], 'c': [4]}
groupby из модуля itertools. Этот метод работает быстрее, когда данные уже отсортированы, но требует предварительной сортировки.
from itertools import groupby
keys = ['a', 'b', 'a', 'c']
values = [1, 2, 3, 4]
data = sorted(zip(keys, values), key=lambda x: x[0])
result = {k: [v for _, v in group] for k, group in groupby(data, key=lambda x: x[0])}
print(result)
Результат: {'a': [1, 3], 'b': [2], 'c': [4]}
Выбор метода зависит от задачи. Если порядок ключей не важен, defaultdict – наиболее удобный способ. Если данные требуют дополнительной обработки или анализов, можно использовать pandas. Если же необходимо минимизировать зависимости, достаточно обычного словаря с проверкой ключа или использования itertools.groupby для отсортированных данных.
Как создать словарь, используя генераторы словарей
Генераторы словарей в Python позволяют создать словарь с использованием компактного синтаксиса, который напоминает генераторы списков. Они полезны, когда требуется преобразовать или фильтровать данные с минимальными усилиями.
Чтобы создать словарь с помощью генератора, используется конструкция вида:
dict((key, value) for key, value in iterable)
Здесь `iterable` – это любой итерируемый объект, например, список или кортеж. Генератор создает пары "ключ-значение", которые передаются в функцию dict() для формирования конечного словаря.
Пример генератора словаря из двух списков:
keys = ['a', 'b', 'c'] values = [1, 2, 3] result = dict((key, value) for key, value in zip(keys, values))
В этом примере используется функция zip(), которая комбинирует два списка в кортежи, затем генератор перебирает их и создает пары ключ-значение. Результатом будет словарь {'a': 1, 'b': 2, 'c': 3}.
Генераторы словарей также поддерживают условия для фильтрации элементов. Например, можно создать словарь, содержащий только те элементы, которые соответствуют определенному условию:
numbers = [1, 2, 3, 4, 5]
squared = {n: n**2 for n in numbers if n % 2 == 0}
В данном примере создается словарь, где ключами будут четные числа из списка numbers, а значениями – их квадраты. Результат будет: {2: 4, 4: 16}.
Использование генераторов словарей помогает избежать необходимости в дополнительных циклах и условных операторах, упрощая код и делая его более читаемым.
Оптимизация работы с большими списками при создании словаря

Для создания словаря из двух больших списков (например, списков ключей и значений) рекомендуется использовать функцию `zip()`. Это решение избегает необходимости создавать дополнительные промежуточные структуры данных, как при использовании обычных циклов или комбинирования списков. Пример оптимального подхода:
dict(zip(keys, values))Этот способ значительно экономит время, так как работает за один проход по данным и напрямую создает пары "ключ-значение". Важно, чтобы списки имели одинаковую длину, иначе избыточные элементы из более длинного списка будут проигнорированы.
Для еще более эффективной работы с большими данными можно использовать генераторы. Они позволяют избежать создания всего списка в памяти, что критично при работе с огромными объемами данных. Например, использование генератора внутри функции `dict()` будет выглядеть так:
dict((key, value) for key, value in zip(keys, values))Данный способ не создает промежуточный список и снижает использование памяти. Этот подход особенно полезен при обработке данных в реальном времени, когда объем данных может быть значительно большим, чем размер оперативной памяти.
Кроме того, для работы с огромными списками можно использовать модули, такие как `itertools` или `numpy`, которые обеспечивают дополнительные оптимизации при манипуляциях с большими наборами данных. Например, в случае числовых данных, использование `numpy.array` вместо обычных списков может ускорить создание словаря за счет более быстрого доступа к элементам.
Если входные данные содержат дубликаты в ключах, то Python автоматически оставит только последнее значение для каждого ключа. Это стоит учитывать, чтобы избежать потери информации. Если необходимо сохранить все значения для одинаковых ключей, можно использовать `collections.defaultdict` для добавления значений в списки:
from collections import defaultdict
d = defaultdict(list)
for key, value in zip(keys, values):
d[key].append(value)Такой подход позволит избежать потерь данных и обеспечит корректное объединение значений по одинаковым ключам.