В Python строка – это последовательность символов, а список – упорядоченная коллекция объектов. Преобразование строки в список необходимо, когда требуется работать с отдельными элементами строки: символами, словами, подстроками определённой структуры. Способ преобразования зависит от цели: разбить строку по пробелам, символам, разделителям или по шаблону.
Функция split() – основной инструмент для разбиения строки. Без аргументов она делит строку по пробелам, удаляя лишние. Например: ‘яблоко груша банан’.split() вернёт [‘яблоко’, ‘груша’, ‘банан’]. С аргументом можно указать конкретный разделитель: ‘12,45,78’.split(‘,’) даст [’12’, ’45’, ’78’].
Если требуется разбить строку на отдельные символы, используют функцию list(): list(‘python’) преобразует строку в [‘p’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’]. Это не работает с пробелами или разделителями – в этом случае результат будет включать их как отдельные элементы.
Для более сложного разбиения применяют модуль re и функцию re.split(). Например, re.split(r’\W+’, ‘слово1,слово2;слово3’) вернёт [‘слово1’, ‘слово2’, ‘слово3’], игнорируя знаки препинания. Это удобно при работе с текстами без строгой структуры.
Преобразование строки в список – не универсальная операция, а инструмент, выбор которого зависит от структуры исходных данных и целей обработки. Чем точнее подход, тем чище и предсказуемее результат.
Разделение строки по пробелам с помощью split()
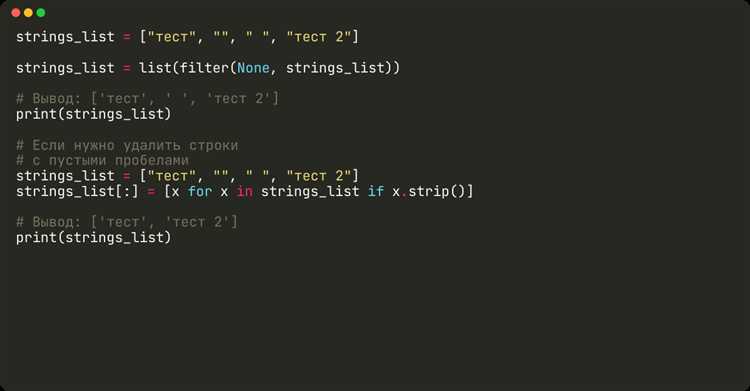
Метод split() без аргументов разбивает строку по всем подряд идущим пробелам, включая табуляции и переводы строк, игнорируя пустые элементы. Это поведение важно при обработке неформатированного текста.
- Вызов
"Пример строки с двумя пробелами".split()вернёт['Пример', 'строки', 'с', 'двумя', 'пробелами']. - Строка
" ".split()возвращает пустой список:[], поскольку нет слов. - Строка с табуляцией
"текст\tс табуляцией".split()возвращает['текст', 'с', 'табуляцией'].
Если требуется точное разделение только по одиночным пробелам, следует явно указать аргумент:
"a b c".split(" ")вернёт['a', '', 'b', 'c'], включая пустые элементы.
Для очистки строки перед разбиением рекомендуется применять strip() или replace():
s.strip().split()удалит пробелы в начале и конце строки перед разбиением.s.replace("\n", " ").replace("\t", " ").split()подойдёт для нормализации пробельных символов.
Метод split() не меняет исходную строку. Результат – новый список строк. Для последующей обработки (поиск, фильтрация, сортировка) рекомендуется работать уже с полученным списком.
Преобразование строки в список символов через list()

Функция list() преобразует строку в список, где каждый элемент – отдельный символ исходной строки. Это позволяет напрямую получить доступ к символам по индексам, модифицировать отдельные элементы или использовать методы списков для обработки символов.
Пример: list(«Python») вернёт [‘P’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’]. Строка разбивается без дополнительных условий – каждый символ, включая пробелы, цифры и знаки препинания, включается в результат.
Метод полезен при необходимости итерироваться по символам с возможностью изменения или удаления, чего нельзя сделать со строкой, так как она неизменяема. Полученный список можно сортировать, фильтровать или сжимать, применяя функции filter(), sorted() и другие.
Если строка пустая, результатом будет пустой список: list(«») → []. При работе с Unicode-символами каждый символ воспринимается как отдельная единица, независимо от количества байт в кодировке.
Функция list() не подходит для разделения строки по словам или другим логическим единицам. Для этого следует использовать split().
Разделение строки по символу-разделителю
Для преобразования строки в список на основе символа-разделителя используется метод split(). Он принимает необязательный аргумент – строку-разделитель. Если указать, например, запятую, строка будет разбита на элементы в местах её появления.
Пример: 'яблоко,груша,слива'.split(',') вернёт ['яблоко', 'груша', 'слива']. Если разделитель отсутствует в строке, результатом будет список с одним элементом – исходной строкой.
Разделитель может быть любым символом: пробел (' '), двоеточие (':'), точка с запятой (';') и т.д. Если передать пустую строку в split(''), возникнет исключение ValueError.
Если строка содержит повторяющиеся подряд разделители, например 'a,,b' с разделителем ',', результат будет ['a', '', 'b']. Это важно учитывать при последующей обработке данных.
Для удаления лишних пробелов до или после разделённых элементов рекомендуется комбинировать split() с strip() или использовать генератор списков: [x.strip() for x in строка.split(',')].
Обработка строки с удалением пробелов и специальных символов

Перед преобразованием строки в список часто необходимо очистить её от лишних символов: пробелов, символов новой строки, табуляции и пунктуации. Для этого используют методы str.replace(), str.strip(), str.split() и модуль re для регулярных выражений.
Чтобы удалить все пробелы и спецсимволы, кроме букв и цифр, применяют следующую конструкцию:
import re
s = " Пример строки! С символами,\tпробелами и\nпереводами строк. "
s_clean = re.sub(r'[^a-zA-Zа-яА-Я0-9]', '', s)
Если нужно сохранить пробелы между словами, но убрать лишнее:
s = " Пример строки! С символами,\tпробелами и\nпереводами строк. "
s_clean = re.sub(r'[^\w\s]', '', s).strip()
Функция str.strip() удаляет пробелы и управляющие символы в начале и конце строки. Для удаления символов в середине строки используйте str.replace():
s = "тестовая строка\n"
s = s.replace('\n', '').replace('\t', '').replace(' ', '')
Для более гибкой очистки можно задать список символов, подлежащих удалению, и пройтись по строке:
remove_chars = ['\n', '\t', ',', '.', '!', '?', ' ']
s = "Тестовая, строка!\n"
for char in remove_chars:
s = s.replace(char, '')
После удаления ненужных символов строку можно безопасно разбивать на список:
s = "один;два;три"
s_list = s.split(';')
Обработка должна быть адаптирована под ожидаемый формат входных данных. Например, при парсинге CSV вместо удаления запятых строку следует разделить по ним.
Преобразование строки чисел в список целых или вещественных чисел
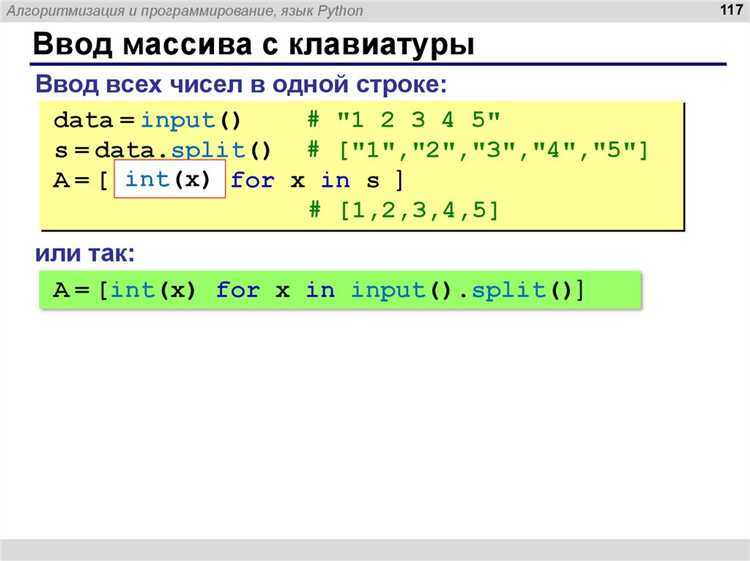
Для преобразования строки, содержащей числа, в список целых или вещественных чисел, необходимо использовать функцию split() для разделения строки на отдельные элементы и затем применить соответствующее преобразование к каждому элементу. Рассмотрим два случая: преобразование в целые и вещественные числа.
Если строка состоит из целых чисел, разделённых пробелами или другими разделителями, можно использовать метод split() для получения списка строк, а затем преобразовать каждую строку в целое число с помощью функции int(). Например:
numbers = "1 2 3 4 5"
int_list = [int(x) for x in numbers.split()]
print(int_list)Этот код создаст список: [1, 2, 3, 4, 5].
Если числа в строке могут быть вещественными, то следует использовать функцию float() для преобразования каждого элемента в вещественное число. Например:
numbers = "1.1 2.2 3.3 4.4"
float_list = [float(x) for x in numbers.split()]
print(float_list)Результат: [1.1, 2.2, 3.3, 4.4].
Чтобы обработать строку, содержащую числа, разделённые различными символами (например, запятыми или точками с запятой), можно указать разделитель в методе split(). Например, для строки, разделённой запятыми:
numbers = "1.1,2.2,3.3,4.4"
float_list = [float(x) for x in numbers.split(',')]
print(float_list)В результате будет создан список: [1.1, 2.2, 3.3, 4.4].
Если в строке встречаются некорректные данные, например, символы, которые нельзя преобразовать в числа, стоит обрабатывать исключения. Использование конструкции try-except позволяет избежать ошибок и продолжить выполнение программы:
numbers = "1.1 2.2 three 4.4"
float_list = []
for item in numbers.split():
try:
float_list.append(float(item))
except ValueError:
pass
print(float_list)Этот код проигнорирует элементы, не являющиеся числами, и вернёт: [1.1, 2.2, 4.4].
Преобразование строки с кавычками в список значений

Когда строка содержит значения, заключенные в кавычки, например, "apple","banana","cherry", и требуется преобразовать её в список, важно учесть тип кавычек и разделители. Стандартный способ преобразования подобной строки в список – использование метода split() с указанием подходящего разделителя. Однако если строка состоит из элементов, окружённых кавычками, необходимо сначала избавиться от этих кавычек.
Пример строки: '"apple","banana","cherry"
Для того чтобы правильно обработать такую строку, можно воспользоваться следующим подходом:
str_input = '"apple","banana","cherry"'
str_input = str_input.replace('"', '') # Убираем кавычки
result = str_input.split(',') # Разделяем строку по запятой
print(result)
В результате получится список значений: ['apple', 'banana', 'cherry'].
Другим вариантом является использование регулярных выражений для более сложных случаев, например, когда элементы строки могут быть разделены различными символами, а кавычки могут встречаться внутри значений. В этом случае поможет модуль re.
import re
str_input = '"apple","banana","cherry"'
result = re.findall(r'"([^"]+)"', str_input)
print(result)
Результат: ['apple', 'banana', 'cherry'].
Этот метод будет полезен, если в строке есть дополнительные символы или если элементы могут быть заключены в одинарные или двойные кавычки.
Работа со строкой JSON для получения списка
Пример: если у вас есть строка JSON, представляющая список, вам нужно просто передать её в функцию json.loads(), чтобы получить Python-список. Важно, чтобы строка JSON была корректной, иначе будет выброшено исключение json.JSONDecodeError.
import json
json_str = '["apple", "banana", "cherry"]'
python_list = json.loads(json_str)
Если строка JSON содержит сложные вложенные структуры, например, список словарей, json.loads() корректно преобразует её в соответствующие вложенные объекты Python. Пример:
json_str = '[{"name": "Alice", "age": 30}, {"name": "Bob", "age": 25}]'
python_list = json.loads(json_str)
После того как строка преобразована в список, можно работать с данными, как с обычными объектами Python. Важно учитывать, что данные в JSON-строке должны быть валидными: строки должны быть заключены в двойные кавычки, а не в одинарные. Также необходимо следить за правильностью вложенности и использования запятых между элементами.
Для успешной работы с JSON-строками важно использовать исключения. Например, если строка не является валидной JSON-строкой, Python выбросит исключение json.JSONDecodeError, которое можно обработать через блок try-except.
try:
python_list = json.loads(json_str)
except json.JSONDecodeError as e:
print(f"Ошибка декодирования JSON: {e}")
Таким образом, работа с JSON-строкой для получения списка в Python сводится к использованию json.loads(), соблюдению синтаксиса JSON и обработке возможных ошибок при неверном формате строки.