В Python матрица обычно представляется в виде списка списков, где каждая вложенная структура соответствует строке. Однако во многих задачах требуется линейное представление данных, например, при сериализации, вычислениях или передаче по сети. В таких случаях возникает необходимость преобразовать двумерную структуру в одномерный список.
Для этого можно использовать как базовые конструкции языка, так и функции стандартной библиотеки. Простейший способ – вложенный цикл: пройти по каждой строке и элементу в ней, добавляя значения в новый список. Такой подход дает полный контроль над порядком элементов и позволяет применить дополнительные фильтры при необходимости.
Более лаконичный вариант – использовать генераторы списков: [elem for row in matrix for elem in row]. Это решение эквивалентно вложенным циклам, но короче и читабельнее. При этом важно понимать, что вложенные списки могут иметь разную длину или содержать другие структуры, что требует дополнительной обработки.
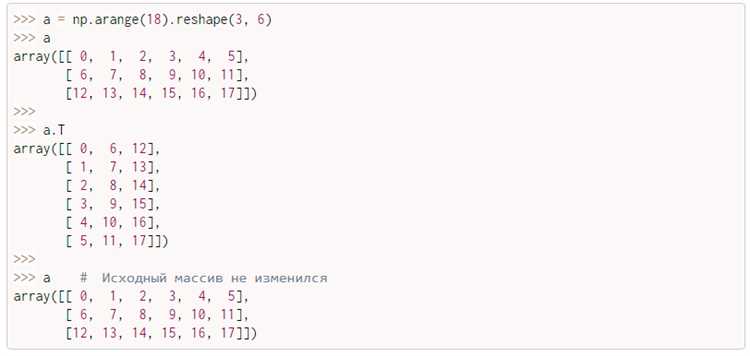
Если матрица представлена с использованием библиотеки NumPy, рекомендуется метод flatten() или функция ravel(). Первый возвращает копию данных, второй – представление без копирования, что важно для работы с большими массивами. В случае необходимости преобразования в стандартный список можно вызвать .tolist().
При работе с вложенными структурами, которые глубже двух уровней, полезно использовать модуль itertools и функцию chain.from_iterable. Это особенно актуально при обработке данных произвольной вложенности, например, при работе с JSON.
Как превратить двумерную матрицу в плоский список с помощью list comprehension
Для преобразования двумерной матрицы в одномерный список применяется вложенный list comprehension. Это позволяет обойтись без вызова дополнительных функций и сохранить читаемость кода.
Пример: пусть имеется матрица matrix = [[1, 2], [3, 4], [5, 6]]. Чтобы получить плоский список [1, 2, 3, 4, 5, 6], используйте конструкцию: flat = [item for row in matrix for item in row].
Порядок for row in matrix перед for item in row важен: он определяет правильную последовательность обхода элементов по строкам. Ошибка в порядке приведёт к логическим сбоям, особенно при работе с асимметричными структурами.
Если в матрице возможны вложенные структуры глубже второго уровня, list comprehension следует заменить на рекурсивную функцию или использовать itertools.chain с дополнительной обработкой.
Для проверки корректности результата можно использовать assert flat == [1, 2, 3, 4, 5, 6]. Это позволит убедиться, что развёртывание выполнено без потерь данных.
Использование встроенной функции sum для объединения вложенных списков

Функция sum() может применяться к вложенным спискам для преобразования матрицы в одномерный список. Синтаксис: sum(матрица, []), где второй аргумент указывает начальное значение аккумулятора – пустой список.
Важно учитывать, что sum() предназначена для чисел, но в случае списков она также выполняет конкатенацию, если начальное значение – список. Пример:
matrix = [[1, 2], [3, 4], [5, 6]]
flat_list = sum(matrix, [])
print(flat_list) # [1, 2, 3, 4, 5, 6]
Этот способ эффективен для небольших и средних структур. Однако при работе с большими матрицами предпочтительнее использовать itertools.chain(), так как sum() выполняет поэлементную конкатенацию, создавая новый список на каждом шаге, что приводит к квадратичной сложности по времени.
Рекомендуется избегать sum() в критичных по производительности участках кода. Для быстрой проверки структуры или при обучении она подходит, но в продакшене стоит использовать специализированные решения.
Когда стоит использовать itertools.chain для работы с матрицами
itertools.chain особенно полезен при необходимости быстро «развернуть» двумерную матрицу в одномерный список без вложенных циклов. Это актуально, когда требуется передать данные в функции, ожидающие последовательность без вложенности: например, при передаче значений в функции визуализации или сериализации.
При работе с большими матрицами chain эффективен по памяти. Он создает итератор, не копируя содержимое матрицы в новый список до фактической итерации. Это снижает нагрузку на оперативную память по сравнению с использованием списковых включений [item for row in matrix for item in row], которые сразу создают полный список.
Используйте itertools.chain, если:
- Нужна плоская последовательность значений из матрицы.
- Важно сохранить ленивую модель вычислений.
- Работаете с генераторами или другими итераторами внутри матрицы.
Пример: list(chain.from_iterable(matrix)) позволит эффективно получить одномерный список из списка списков. Особенно это актуально, когда каждая строка матрицы генерируется динамически или поступает из потока данных.
Как извлечь только элементы главной диагонали в одномерный список
Для получения главной диагонали из квадратной матрицы в виде одномерного списка следует выбрать элементы, расположенные на пересечении одинаковых индексов строк и столбцов. Это можно реализовать с помощью генератора списков.
Пример: пусть дана матрица matrix = [[4, 2, 7], [9, 5, 1], [6, 8, 3]]. Главная диагональ включает элементы matrix[0][0], matrix[1][1] и matrix[2][2], то есть [4, 5, 3].
Реализация:
matrix = [[4, 2, 7],
[9, 5, 1],
[6, 8, 3]]
diagonal = [matrix[i][i] for i in range(len(matrix))]
print(diagonal) # [4, 5, 3]Если необходимо обработать матрицу произвольного размера, сначала следует убедиться, что она квадратная, иначе извлечение главной диагонали приведёт к ошибке или частичным данным. Для проверки используйте условие all(len(row) == len(matrix) for row in matrix).
Если матрица не квадратная, можно ограничиться минимальной из длины строк и количества строк: min(len(matrix), len(matrix[0])). Это позволит безопасно получить диагональные элементы даже в прямоугольных матрицах.
Пример для неквадратной матрицы:
matrix = [[1, 2, 3],
[4, 5, 6]]
n = min(len(matrix), len(matrix[0]))
diagonal = [matrix[i][i] for i in range(n)]
print(diagonal) # [1, 5]Преобразование матрицы с сохранением индексов элементов
Для преобразования матрицы в список с сохранением индексов элементов в Python можно использовать встроенные функции и различные способы представления данных. Обычно задача требует сохранить структуру индексов (строка и столбец) при преобразовании двумерной структуры в одномерную.
Рассмотрим пример матрицы:
matrix = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]
При преобразовании в список можно сохранить индексы каждого элемента. Для этого можно воспользоваться списковым включением (list comprehension) или функцией enumerate.
Использование enumerate для сохранения индексов
Для получения индекса элемента в матрице можно использовать функцию enumerate, которая позволяет отслеживать как строку, так и столбец:
indexed_list = [(i, j, matrix[i][j]) for i, row in enumerate(matrix) for j, val in enumerate(row)]
i— индекс строки.j— индекс столбца.matrix[i][j]— значение элемента в соответствующей ячейке.
В результате получаем список кортежей, где каждый кортеж содержит индексы строки и столбца и значение элемента:
[(0, 0, 1), (0, 1, 2), (0, 2, 3), (1, 0, 4), (1, 1, 5), (1, 2, 6), (2, 0, 7), (2, 1, 8), (2, 2, 9)]
Использование библиотеки numpy
Если для работы с матрицами используется библиотека numpy, то преобразование также можно выполнить с сохранением индексов:
import numpy as np matrix = np.array([ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]) indexed_list = [(i, j, matrix[i, j]) for i in range(matrix.shape[0]) for j in range(matrix.shape[1])]
В этом случае мы обращаемся к элементам матрицы через индексы, используя matrix[i, j]. В результате получаем аналогичный список, как в предыдущем примере.
Использование функций для обработки матриц

Можно создать отдельную функцию для преобразования матрицы в список с сохранением индексов:
def matrix_to_indexed_list(matrix): return [(i, j, matrix[i][j]) for i, row in enumerate(matrix) for j, val in enumerate(row)]
Теперь эту функцию можно использовать для любой матрицы, передавая ее в качестве аргумента. Пример использования:
indexed_list = matrix_to_indexed_list(matrix)
Преимущества подхода
- Легкость в реализации и читаемости кода.
- Гибкость при добавлении дополнительных операций, например, фильтрации или сортировки элементов.
- Возможность использовать индексы в дальнейшем для обращения к отдельным элементам или обработки данных.
Заключение
Преобразование матрицы в список с сохранением индексов элементов позволяет легко работать с каждым элементом, зная его позицию в исходной структуре. Этот метод полезен при анализе данных, требующих учета местоположения каждого значения в матрице.
Работа с матрицами, содержащими None или пустые значения

При работе с матрицами в Python могут возникать ситуации, когда элементы содержат значения None или пустые значения. Эти значения могут возникать в результате отсутствия данных или ошибок при их обработке. В таких случаях важно грамотно обрабатывать эти элементы для дальнейших операций.
Если в матрице встречаются значения None, такие элементы могут вызвать ошибки при попытке выполнения арифметических операций или других вычислений. Чтобы избежать этого, необходимо заранее обработать такие значения, заменив их на подходящие, например, на нули или другие значения, подходящие для вашей задачи.
Замена None на конкретное значение: Для замены значений None на другой элемент, например, на ноль, можно использовать цикл или генераторы. Пример:
matrix = [[1, None, 3], [None, 5, None], [7, 8, None]]
new_matrix = [[0 if x is None else x for x in row] for row in matrix]Этот код создаст новую матрицу, где все элементы, равные None, будут заменены на 0.
Фильтрация пустых значений: В некоторых случаях нужно избавиться от элементов, содержащих пустые значения, например, если они не несут полезной информации. Для этого можно применить фильтрацию. Для матрицы, представленной в виде списка списков, можно использовать генераторы:
matrix = [[1, '', 3], ['', 5, ''], [7, '', 8]]
new_matrix = [[x for x in row if x != ''] for row in matrix]Этот код удалит пустые строки из каждой строки матрицы, оставив только те элементы, которые содержат данные.
Обработка значений None в числовых операциях: Если нужно выполнять вычисления с матрицей, содержащей None, и это может повлиять на результаты, можно воспользоваться функцией map или заменить None на нули с помощью numpy, которая предоставляет более удобные методы работы с такими данными:
import numpy as np
matrix = np.array([[1, None, 3], [None, 5, None], [7, 8, None]])
matrix = np.nan_to_num(matrix, nan=0)В этом примере numpy.nan_to_num заменяет все None (которые интерпретируются как NaN) на 0.
Проверка на None: При необходимости проверки элементов матрицы на присутствие значения None, можно использовать условные выражения. Например:
matrix = [[1, None, 3], [None, 5, None], [7, 8, None]]
for row in matrix:
for item in row:
if item is None:
print("Найдено None")Это позволит точно локализовать элементы с отсутствующими данными и выполнить необходимую обработку.
Работа с матрицами, содержащими None или пустые значения, требует внимательности и правильной обработки данных, чтобы избежать ошибок в дальнейшем. Применение соответствующих методов и функций поможет эффективно работать с такими матрицами и корректно обрабатывать их в ходе вычислений.
Преобразование матрицы строк в список чисел
Первый способ – использование метода extend() для объединения строк в один список:
matrix = [[1, 2], [3, 4], [5, 6]]
result = []
for row in matrix:
result.extend(row)
В результате получится плоский список [1, 2, 3, 4, 5, 6]. Метод extend() позволяет поочередно добавлять элементы каждой строки в итоговый список.
Альтернативный способ – использование спискового включения, который более компактен и читаем:
matrix = [[1, 2], [3, 4], [5, 6]]
result = [num for row in matrix for num in row]
Этот подход также преобразует матрицу в список, при этом его удобство заключается в одной строке кода. Результат будет аналогичен предыдущему – [1, 2, 3, 4, 5, 6].
Оба метода эффективны, однако, при больших объемах данных или высоких требованиях к скорости выполнения, может быть полезно рассмотреть использование библиотеки NumPy, которая предоставляет функции для работы с многомерными массивами. Например, с помощью numpy.flatten() можно получить одномерный массив за одну операцию:
import numpy as np
matrix = np.array([[1, 2], [3, 4], [5, 6]])
result = matrix.flatten()
Этот метод предпочтителен для больших массивов данных, так как NumPy использует оптимизированные алгоритмы для обработки массивов.
Как обработать матрицу разной вложенности и привести её к плоскому виду
Для работы с матрицами разной вложенности в Python необходимо учитывать, что матрицы могут иметь различные уровни вложенности, что влияет на выбор метода преобразования в одномерный список.
Чтобы привести матрицу разной вложенности к плоскому виду, существует несколько подходов. Каждый из них зависит от того, насколько глубоко вложены элементы. Наиболее эффективный способ – использование рекурсии.
Рекурсивный метод
Рекурсивный подход заключается в обходе каждого элемента матрицы. Если элемент является списком, функция рекурсивно вызывает себя для каждого вложенного списка. В противном случае элемент добавляется в итоговый список.
def flatten(matrix): flat_list = [] for element in matrix: if isinstance(element, list): flat_list.extend(flatten(element)) else: flat_list.append(element) return flat_list
Этот метод работает эффективно, но может потребовать оптимизаций, если матрица содержит слишком глубоко вложенные списки.
Использование стека
Если рекурсия не подходит, например, из-за ограничений по глубине стека, можно использовать итеративный метод с помощью стека. Преимущество этого метода – возможность обработки больших матриц без переполнения стека.
def flatten_iterative(matrix): flat_list = [] stack = [matrix] while stack: current = stack.pop() if isinstance(current, list): stack.extend(current) else: flat_list.append(current) return flat_list
Метод с использованием стека представляет собой итеративное решение задачи. Каждый элемент, который является списком, добавляется обратно в стек для дальнейшей обработки.
Применение генераторов
В Python можно использовать генераторы для создания одноразовых последовательностей. Это позволяет писать более компактный и эффективный код, не создавая временных списков, что экономит память при обработке больших данных.
def flatten_generator(matrix): for element in matrix: if isinstance(element, list): yield from flatten_generator(element) else: yield element
Генераторный подход позволяет обрабатывать элементы «по мере их поступления», что делает его отличным выбором для работы с большими вложенными структурами данных.
Особенности выбора метода
- Для матриц средней вложенности рекурсия или генераторы обеспечат читаемость и лаконичность кода.
- Если данные содержат очень глубоко вложенные списки, лучше использовать итеративный метод с использованием стека, чтобы избежать проблем с переполнением стека.
- Генераторы обеспечивают эффективную работу с памятью, но их использование может потребовать дополнительного внимания к особенностям работы с итераторами.
В каждом конкретном случае необходимо выбирать подход, исходя из сложности данных и потребностей в производительности. Использование рекурсии и генераторов упрощает код, в то время как итеративный метод с использованием стека подойдёт для более сложных и глубоких структур данных.
Вопрос-ответ:
Что такое преобразование матрицы в список в Python?
Преобразование матрицы в список в Python — это процесс, при котором двумерная структура данных (матрица) преобразуется в одномерный список. Это может быть полезно для упрощения работы с данными или для дальнейших операций, требующих одномерных структур. Например, если матрица представляет собой список списков, то её элементы можно извлечь в один список с помощью различных методов, таких как цикл или функции из библиотеки NumPy.
Какие преимущества и недостатки разных методов преобразования матрицы в список?
Каждый метод имеет свои особенности. Использование циклов (например, через `for`-циклы) является универсальным и понятно для большинства пользователей, однако это может быть менее эффективно, особенно при работе с большими матрицами. В то же время, методы из библиотеки NumPy (например, `.flatten()`) позволяют делать это более компактно и быстрее для больших данных, но требуют предварительной установки библиотеки. Использование list comprehension часто является самым компактным и читаемым способом, особенно в небольших проектах или при работе с небольшими матрицами. Однако в случае работы с большими объемами данных, NumPy может оказаться более быстрым вариантом.