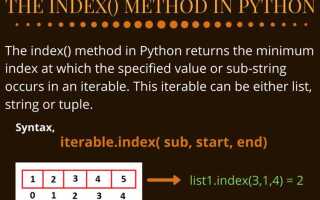
Работа со строками в Python предполагает частое использование операций поиска символов. Когда требуется определить позицию символа в строке, важно знать, какие методы использовать, чтобы получить точный индекс с учётом регистра и возможного отсутствия символа.
Метод str.find() возвращает индекс первого вхождения символа или подстроки. Если символ не найден, метод возвращает -1. Такой подход полезен, когда необходимо избежать исключений и просто проверить наличие символа.
Для ситуаций, где требуется строгий контроль и обработка ошибок, лучше использовать str.index(). Этот метод аналогичен find(), но выбрасывает исключение ValueError, если символ не найден. Это позволяет явно обрабатывать ошибочные случаи в коде и избегать скрытых проблем.
Если задача состоит в поиске всех вхождений символа, необходимо использовать цикл и метод str.find() с указанием стартового индекса. Альтернативный способ – генераторное выражение с функцией enumerate(), которое позволяет получить индексы всех вхождений за одну итерацию.
В задачах, связанных с обратным поиском, применяется метод str.rfind(), который возвращает индекс последнего вхождения символа. Он также возвращает -1 при отсутствии совпадений, что делает его безопасным в простых проверках.
Знание точных особенностей этих методов позволяет выбирать наиболее эффективный способ поиска символа в зависимости от контекста – будь то обработка пользовательского ввода, разбор текстовых файлов или работа с логами.
Как найти первый индекс символа в строке с помощью метода find()
Метод find() возвращает индекс первого вхождения указанного символа в строке. Если символ не найден, возвращается -1. Метод чувствителен к регистру и не вызывает исключений при отсутствии символа, что делает его безопасной альтернативой index().
Синтаксис:
строка.find(символ[, start[, end]])Примеры:
текст = "Пример строки"
позиция = текст.find("р")
print(позиция) # 2Вызов find("р") возвращает 2, поскольку символ «р» впервые встречается на позиции 2 (нумерация с нуля). Метод допускает указание диапазона поиска:
позиция = текст.find("р", 3)
print(позиция) # 8Если указанный символ отсутствует в диапазоне, результатом будет -1:
позиция = текст.find("р", 9)
print(позиция) # -1Рекомендуется использовать find() при неуверенности в наличии символа в строке. Это предотвращает возникновение исключения и упрощает обработку условий поиска.
Что возвращает метод find(), если символ не найден
Метод find() возвращает -1, если указанный символ или подстрока отсутствуют в исходной строке. Это ключевое отличие от метода index(), который в аналогичной ситуации вызывает исключение ValueError.
str.find('a')вернёт позицию первого вхождения символа'a'.str.find('z')вернёт-1, если'z'не найден в строке.
Значение -1 удобно для безопасной проверки без необходимости оборачивать вызов в try/except. Это позволяет сократить количество кода и повысить читаемость.
- Проверяйте результат
find()напрямую:if s.find('x') != -1. - Не сравнивайте результат с
None– это ошибка. - Для обхода всех несовпадений используйте цикл с проверкой
while pos != -1.
Используйте find() при анализе строк, когда важно избежать исключений, особенно в пользовательском вводе или при парсинге нестабильных данных.
Отличие методов find() и index() при поиске символа

Методы find() и index() используются для получения позиции первого вхождения символа в строке, но различаются в поведении при отсутствии искомого значения.
find() возвращает -1, если символ не найден. Это удобно, когда требуется безопасная проверка наличия без генерации исключений. Пример: 'abc'.find('x') вернёт -1.
index() выбрасывает исключение ValueError при отсутствии символа. Это полезно, если отсутствие значения считается ошибкой, которую следует обработать явно. Пример: 'abc'.index('x') приведёт к ошибке выполнения.
Если требуется просто узнать, содержится ли символ в строке, безопаснее использовать find(). Если отсутствие символа должно прерывать выполнение или обрабатываться отдельно, используйте index() с конструкцией try/except.
Поиск с обоими методами можно ограничить диапазоном, передав параметры start и end. Оба метода поддерживают одинаковую сигнатуру: строка.find(символ, start, end) и строка.index(символ, start, end).
Как найти все вхождения символа в строке и их индексы

Для получения всех индексов вхождений символа в строку используйте перебор с функцией enumerate(). Это обеспечивает прямой доступ к индексу и значению одновременно.
строка = "python-практика"
символ = "а"
индексы = [i for i, c in enumerate(строка) if c == символ]
print(индексы) # [8, 14]Если регистр не должен влиять на результат, приведите строку и символ к одному регистру:
строка = "Python-Практика"
символ = "п"
индексы = [i for i, c in enumerate(строка.lower()) if c == символ.lower()]
print(индексы) # [0, 7]- Используйте list comprehension – он быстрее и компактнее обычного цикла.
- Не применяйте
str.find()в цикле – он неэффективен для множественных вхождений. - Для поиска нескольких символов можно использовать
if c in набор_символов.
Пример для нескольких символов:
строка = "abcabcabc"
символы = {"a", "b"}
индексы = [i for i, c in enumerate(строка) if c in символы]
print(индексы) # [0, 1, 3, 4, 6, 7]Для Unicode-символов, таких как эмодзи или символы других алфавитов, способ не меняется:
строка = "😀😃😄😀"
символ = "😀"
индексы = [i for i, c in enumerate(строка) if c == символ]
print(индексы) # [0, 3]- Убедитесь, что строка – именно
str, а неbytes. - Если обрабатываете большие объемы текста – используйте генераторы вместо списков.
- Для поиска в конце строки инвертируйте строку и пересчитайте индексы вручную.
Поиск символа в строке с начала, с конца и с указанной позиции

Для поиска первого вхождения символа с начала строки используется метод str.find(). Он возвращает индекс первого найденного символа или -1, если символ не найден:
'пример'.find('е') # результат: 2
Метод str.index() работает аналогично, но вызывает исключение ValueError, если символ отсутствует:
'пример'.index('з') # ValueError: substring not found
Для поиска с конца применяется str.rfind(). Он возвращает индекс последнего вхождения символа:
'ананас'.rfind('а') # результат: 4
Метод str.rindex() также ищет с конца, но выбрасывает исключение при отсутствии символа:
'ананас'.rindex('х') # ValueError
Чтобы начать поиск с определённой позиции, указывается аргумент start в методах find() и index():
'экзамен'.find('е', 3) # результат: 6
Для ограничения диапазона поиска можно использовать второй аргумент end:
'экзамен'.find('е', 3, 6) # результат: -1
Аналогично работают rfind() и rindex(), только поиск выполняется справа налево в заданном диапазоне:
'экзамен'.rfind('е', 0, 5) # результат: 1
Обработка ошибок при использовании метода index() для поиска символа
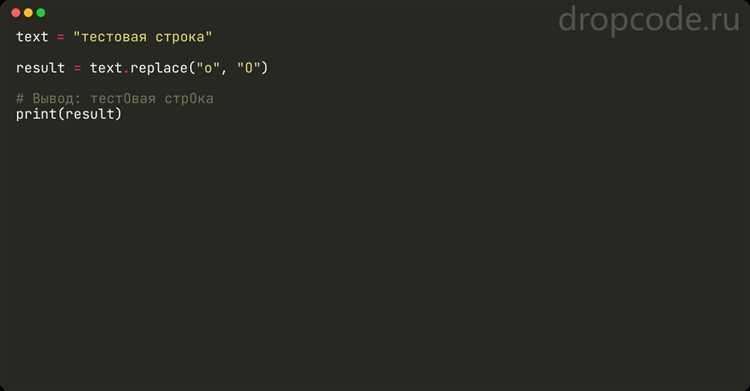
Метод index() в Python используется для поиска первого вхождения подстроки или символа в строке. Однако его использование может привести к возникновению ошибок, если искомый элемент не найден. В таких случаях метод выбрасывает исключение ValueError, что важно учитывать при разработке программ.
Для предотвращения сбоев программы рекомендуется обрабатывать ошибки с помощью конструкции try...except. Это позволяет избежать завершения работы программы при отсутствии символа в строке и предоставить пользователю понятное сообщение об ошибке.
Пример обработки ошибки:
try:
position = my_string.index('a')
except ValueError:
print("Символ не найден в строке")
Такой подход гарантирует, что программа продолжит выполнение, если символ не будет найден. Важно помнить, что метод index() возвращает индекс первого вхождения, а если символ или подстрока не присутствуют, будет выброшено исключение.
Еще одной хорошей практикой является использование метода in для предварительной проверки наличия символа в строке перед использованием index(). Это поможет избежать ненужных исключений и улучшить читаемость кода.
if 'a' in my_string:
position = my_string.index('a')
else:
print("Символ не найден в строке")
Использование таких проверок также увеличивает производительность программы, особенно если строки большие, и позволяет избежать затрат на обработку исключений в случае отсутствия символа.
Таким образом, правильная обработка ошибок при использовании метода index() помогает повысить стабильность программы и предотвращает ее аварийные завершения при неудачных поисках символов.
Поиск символа в строке с учётом регистра и без него

В Python для поиска символов в строках часто используются методы find() и index(), которые различаются поведением при отсутствии символа. Эти методы можно настроить на поиск с учётом регистра или без него в зависимости от задачи.
По умолчанию методы find() и index() учитывают регистр символов. Это означает, что символ ‘a’ будет найден только в том случае, если в строке встречается именно маленькая буква ‘a’, а не ‘A’. Например:
text = "Пример строки"
position = text.find('р') # Найдёт первую букву 'р' (маленькая)
Чтобы выполнить поиск без учёта регистра, можно использовать метод lower() или upper() для приведения всей строки к одному регистру перед выполнением поиска. Это полезно, если необходимо найти все вхождения символа независимо от его регистра. Пример:
text = "Пример Строки"
position = text.lower().find('с') # Поиск будет выполнен без учёта регистра
Однако, такой подход имеет и недостатки. Приведение строки к одному регистру может быть неэффективным для длинных строк, особенно если необходимо выполнить несколько поисков. В таких случаях целесообразно использовать регулярные выражения, которые позволяют учитывать или игнорировать регистр через флаг re.IGNORECASE. Пример:
import re
text = "Пример Строки"
position = re.search('с', text, re.IGNORECASE) # Поиск без учёта регистра
Для поиска всех вхождений символа или подстроки без учёта регистра можно использовать re.findall(), что обеспечит более высокую производительность при множественных запросах.
Таким образом, выбор метода зависит от конкретных требований. Если важна скорость поиска для небольших строк, можно использовать lower() или upper(). Для сложных случаев с регулярными выражениями и большим объёмом данных предпочтительнее использование re.IGNORECASE.