В языке программирования Python для работы со строками существует несколько способов нахождения индекса символа. Одним из наиболее эффективных методов является использование встроенной функции index(). Эта функция позволяет легко найти позицию первого вхождения символа в строку, возвращая его индекс. Если символ отсутствует, будет сгенерировано исключение ValueError, что требует дополнительной обработки ошибок.
Кроме index(), в Python существует метод find(), который работает аналогично, но возвращает -1 в случае отсутствия символа в строке, вместо того чтобы генерировать исключение. Это делает его полезным для случаев, когда необходимо избежать обработки ошибок и просто узнать, присутствует ли символ в строке.
Для поиска индекса символа в строках с учетом регистров или с применением регулярных выражений, можно использовать модуль re. Регулярные выражения позволяют более гибко управлять поиском, например, искать все вхождения символов или их сочетаний, а также производить поиск с учетом или без учета регистра.
Каждый из этих методов имеет свои особенности, и в зависимости от контекста задачи следует выбирать оптимальный вариант для эффективной работы со строками в Python.
Использование метода find() для поиска индекса
Метод find() в Python позволяет найти индекс первого вхождения подстроки в строке. Он возвращает индекс первого символа, с которого начинается найденная подстрока. Если подстрока не найдена, возвращается значение -1.
Пример использования:
text = "Привет, мир!"
index = text.find("мир")
print(index) # Выведет 8Метод find() чувствителен к регистру, поэтому для поиска с игнорированием регистра можно предварительно привести строки к одному регистру:
text = "Привет, мир!"
index = text.lower().find("мир")
print(index) # Выведет 8Также можно задать диапазон индексов для поиска, указав начальный и конечный индекс в качестве параметров. Это позволяет ограничить область поиска, что полезно в некоторых ситуациях, например, когда нужно искать символы только после определенной позиции:
text = "Привет, мир! Привет, мир!"
index = text.find("мир", 10) # Поиск после 10-го индекса
print(index) # Выведет 20Метод find() эффективен, когда нужно найти первое вхождение подстроки, но для поиска всех вхождений рекомендуется использовать метод re.finditer() из модуля re.
Метод index() и его отличие от find()

Методы index() и find() позволяют искать индекс символа или подстроки в строках, но их поведение существенно отличается в случае, если искомый элемент не найден.
Метод index() выбрасывает исключение ValueError, если искомый элемент не найден. Это важно учитывать при работе с данным методом, так как необходимо либо обработать исключение, либо заранее удостовериться в наличии подстроки. Например:
text = "Пример строки"
index = text.index("строка") # вернёт индекс начала подстроки
# text.index("отсутствует") # вызовет ValueError, если подстрока не найдена
В отличие от index(), метод find() возвращает -1, если элемент не найден, что позволяет избежать выброса исключения и делает код более безопасным при проверке наличия подстроки. Пример:
find_index = text.find("строка") # вернёт индекс начала подстроки
find_not_found = text.find("отсутствует") # вернёт -1, если подстрока не найдена
Когда нужно работать с подстрокой, которая может отсутствовать, лучше использовать find(), так как это позволяет избежать лишних проверок и исключений. Если же отсутствие подстроки должно быть обязательно обработано, и необходимо точно знать её отсутствие, выбирайте index().
В обоих методах можно использовать дополнительные параметры для ограничения поиска по диапазону, но это вряд ли повлияет на выбор метода. Главное различие заключается в способе обработки ошибки, что определяет предпочтение одного из методов в зависимости от ситуации.
Как обрабатывать ошибку ValueError при отсутствии символа
При работе с методами поиска символов в строках, такими как index(), Python выбрасывает ошибку ValueError, если символ не найден. Это поведение важно учитывать, чтобы избежать необработанных исключений, которые могут привести к сбоям в программе.
Для корректной обработки этой ошибки можно использовать блоки try...except, которые позволят продолжить выполнение программы без остановки.
- Использование
try...exceptдля перехвата ошибки:
try:
index = my_string.index('a')
except ValueError:
print("Символ не найден в строке.")
- Также можно использовать
inдля предварительной проверки наличия символа в строке перед вызовомindex():
if 'a' in my_string:
index = my_string.index('a')
else:
print("Символ не найден.")
- Дополнительный способ – использование метода
find(), который возвращает-1вместо возбуждения ошибки, если символ не найден:
index = my_string.find('a')
if index == -1:
print("Символ не найден.")
else:
print(f"Символ найден на позиции {index}.")
Каждый из этих подходов имеет свои преимущества. Блок try...except может быть полезен, если нужно обработать различные исключения, а find() дает возможность избежать исключений и сразу работать с результатом.
Поиск индекса первого вхождения символа
Для поиска индекса первого вхождения символа в строке в Python используется метод find(). Этот метод возвращает индекс первого вхождения подстроки в строку или -1, если символ не найден.
Пример использования:
text = "Привет, мир!"
index = text.find('и')
print(index) # Выведет: 4Если символ не встречается в строке, метод вернёт -1:
text = "Привет, мир!"
index = text.find('z')
print(index) # Выведет: -1Важно помнить, что find() не вызывает исключения, если символ не найден. Это позволяет избежать дополнительных проверок и упрощает код.
Метод find() работает с первым вхождением символа. Если требуется найти все вхождения или начать поиск с определённого индекса, можно передать дополнительные аргументы. Например, find(‘и’, 5) начнёт поиск с 5-го индекса.
Альтернативно, метод index() выполняет ту же задачу, но выбрасывает исключение ValueError, если символ не найден. Выбор метода зависит от того, требуется ли обработка ошибок или можно обойтись без них.
Поиск индекса последнего вхождения символа с методом rfind()
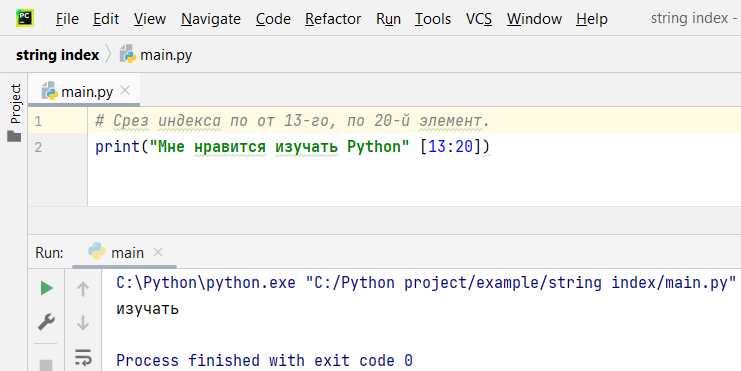
Метод rfind() в Python используется для поиска индекса последнего вхождения подстроки в строке, начиная с конца. Это особенно полезно, когда необходимо найти последний символ или подстроку, не перебирая строку вручную.
Синтаксис метода: str.rfind(substring, start=0, end=len(str)). Он возвращает индекс первого символа в последнем вхождении подстроки substring в строке. Если подстрока не найдена, возвращается -1. Параметры start и end позволяют ограничить область поиска, задавая начало и конец диапазона для поиска.
Пример использования метода:
text = "abcabcabc"
index = text.rfind("b")
print(index) # 5В этом примере метод вернет индекс последнего символа «b» (в позиции 5). Метод ищет в строке справа налево, начиная с конца, что позволяет эффективно находить последние вхождения символов.
Для поиска в ограниченном диапазоне строки, можно указать параметры start и end. Например, чтобы найти последний символ «b» только в первой половине строки, можно задать диапазон поиска:
index = text.rfind("b", 0, len(text)//2)
print(index) # 3Метод rfind() идеально подходит для задач, где важен порядок поиска с конца, например, при анализе путей файлов или обработки строковых данных с несколькими одинаковыми символами.
Поиск индекса символа с учётом регистра
В Python поиск индекса символа с учётом регистра осуществляется с помощью метода find() или index(). Оба метода работают одинаково, но различаются поведением при отсутствии символа в строке: find() возвращает -1, а index() вызывает исключение ValueError.
По умолчанию поиск чувствителен к регистру, то есть символы в верхнем и нижнем регистре считаются разными. Например, строка "Python" не будет содержать символа 'p', а метод find('p') вернёт -1, поскольку символ 'P' в строке имеет другой регистр.
Чтобы найти индекс символа с учётом регистра, используйте стандартные методы без дополнительных настроек. Если вам нужно найти первый символ с учётом регистра, достаточно передать символ в метод поиска:
text = "Python"
index = text.find('P') # вернёт 0Если символ не найден, то можно обработать это через условие или с помощью обработки исключений:
text = "Python"
try:
index = text.index('p') # вызовет ValueError, если символ не найден
except ValueError:
print("Символ не найден")Также важно учитывать, что методы поиска работают с целыми строками. Для поиска индекса подстроки с учётом регистра можно передать подстроку в метод:
text = "Hello, World!"
index = text.find('World') # вернёт 7Важно помнить, что если нужно игнорировать регистр при поиске, следует использовать метод lower() или upper() для преобразования строки и символа в один регистр:
text = "Python"
index = text.lower().find('p') # вернёт 0Как найти индекс символа в строке с помощью регулярных выражений
Использование регулярных выражений (regex) в Python позволяет эффективно искать символы или группы символов в строках. Для нахождения индекса символа можно воспользоваться методом re.search() или re.finditer(), в зависимости от нужд задачи.
Регулярные выражения предоставляют гибкость при поиске символов с учётом дополнительных критериев, таких как шаблоны, экранирование и другие особенности. Рассмотрим несколько методов поиска индекса с использованием регулярных выражений.
Использование re.search()
Метод re.search() ищет первое совпадение шаблона в строке и возвращает объект match, с помощью которого можно получить индекс начала совпадения.
- Пример:
import re
text = "hello world"
pattern = "o"
match = re.search(pattern, text)
if match:
Метод match.start() возвращает индекс первого символа, который совпал с регулярным выражением.
Использование re.finditer()
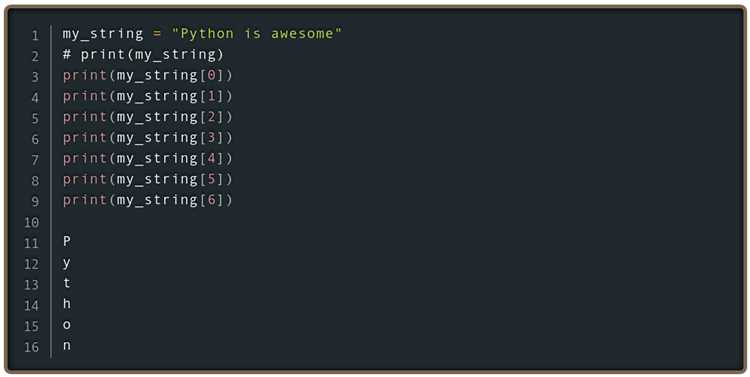
- 4
- 7
Метод match.start() будет возвращать индексы всех символов, совпадающих с регулярным выражением.
Особенности и рекомендации
- Регулярные выражения чувствительны к регистру. Если нужно найти символ без учёта регистра, используйте флаг
re.IGNORECASE. - При поиске нескольких символов или комбинаций символов важно использовать группировки или квантификаторы для точного соответствия шаблона.
- В случае поиска всех индексов в строке рекомендуется использовать
re.finditer()вместоre.search(), так как он возвращает все совпадения.
Регулярные выражения – мощный инструмент для поиска и извлечения информации из строк, включая индексы символов. Их использование позволяет значительно упростить задачи, связанные с обработкой текста в Python.
Поиск индекса символа с заданного положения в строке
В Python для поиска индекса символа в строке с заданного положения используется метод find(). Он позволяет начинать поиск не с начала строки, а с конкретной позиции, что может быть полезно в разных ситуациях, например, при анализе подстрок или при работе с длинными строками.
Метод find() принимает два параметра: индекс, с которого начинается поиск, и сам символ или подстроку. Если символ или подстрока не найдены, метод возвращает -1. Пример использования метода для поиска символа с заданной позиции:
text = "Пример строки для поиска"
index = text.find('р', 5)
print(index) # Выведет индекс первого вхождения символа 'р' начиная с позиции 5
В данном примере поиск символа 'р' начинается с позиции 5. Метод вернёт индекс первого вхождения этого символа, начиная с указанной позиции. Если символ не найден после заданной позиции, результатом будет -1.
Этот подход позволяет эффективно находить символы в строках, избегая ненужных вычислений для начальных частей строки. Метод find() может быть полезен, когда нужно работать с большими строками или выполнять несколько поисков в одном объекте данных.
Также стоит отметить, что метод rfind() работает аналогично find(), но ищет символ или подстроку с конца строки, что может быть полезно при обратном поиске.
Пример использования rfind():
text = "Пример строки для поиска"
index = text.rfind('р', 5)
print(index) # Выведет индекс последнего вхождения символа 'р' начиная с позиции 5
Таким образом, методы find() и rfind() позволяют гибко настроить поиск символов и подстрок с учётом начальной позиции, что делает их удобными для различных задач по обработке строк в Python.