В Python для поиска дубликатов в списке можно использовать несколько подходов, в зависимости от объема данных и требований к производительности. Чаще всего задачи по поиску дубликатов требуют быстрого и эффективного метода, особенно когда речь идет о больших коллекциях. Важно понимать, что использование стандартных циклов может быть неэффективным для больших списков, поэтому выбор алгоритма имеет значение.
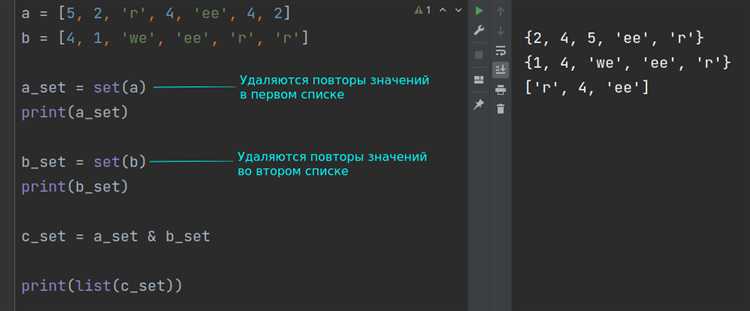
Один из наиболее простых и эффективных способов – использовать структуру данных set, которая автоматически исключает повторяющиеся элементы. Для нахождения дубликатов достаточно пройти по списку и добавлять элементы в множество, проверяя их наличие. Этот метод работает за время O(n), где n – количество элементов в списке.
Однако если важно не только найти дубликаты, но и сохранить их порядок появления, стоит обратить внимание на использование collections.Counter, который позволяет отслеживать количество повторений каждого элемента в списке. Такой подход также имеет линейную сложность и даёт более точную информацию о частоте каждого элемента.
Использование структуры данных set для поиска дубликатов
Структура данных set в Python идеально подходит для быстрого поиска дубликатов в списке. Это связано с тем, что set хранит только уникальные элементы и обеспечивает операцию проверки принадлежности за среднее время O(1). Рассмотрим, как эффективно использовать set для этой задачи.
Основная идея заключается в том, чтобы пройти по всем элементам списка и добавить их в set. Если элемент уже присутствует в set, значит, он является дубликатом. Если нет, добавляем его в set.
Пример реализации:
def find_duplicates(lst):
seen = set()
duplicates = set()
for item in lst:
if item in seen:
duplicates.add(item)
else:
seen.add(item)
return duplicatesВ этом примере два set: seen для хранения уникальных элементов, и duplicates для хранения найденных дубликатов. Процесс работает следующим образом:
- Проходим по каждому элементу списка.
- Если элемент уже есть в
seen, добавляем его вduplicates. - Если элемента в
seenнет, добавляем его туда.
Этот метод работает с линейной сложностью O(n), что значительно быстрее, чем использование вложенных циклов для сравнения каждого элемента с каждым.
При использовании set для поиска дубликатов важно учитывать, что порядок элементов не сохраняется. Если необходимо сохранить порядок, нужно использовать другие подходы, например, комбинацию list и set или коллекцию OrderedDict.
Использование set подходит для большинства случаев, когда задача заключается в нахождении дубликатов в списках, содержащих примитивные типы данных (числа, строки и т.д.). Однако если элементы сложнее (например, объекты), необходимо будет переопределить методы сравнения для работы с такими элементами в set.
Метод с использованием коллекции Counter для подсчёта повторений

Коллекция Counter из модуля collections предоставляет эффективный способ подсчёта количества вхождений элементов в списке. Этот метод особенно полезен при поиске дубликатов, так как позволяет легко получить информацию о каждом элементе и его количестве в одной операции.
Для использования Counter достаточно передать список в качестве аргумента. Коллекция автоматически подсчитает, сколько раз каждый элемент встречается, и вернёт объект, где ключи – это уникальные элементы, а значения – их количество в исходном списке.
Пример кода:
from collections import Counter
Исходный список
data = [1, 2, 2, 3, 4, 5, 5, 5, 6]
Подсчёт повторений
counter = Counter(data)
duplicates = {key: value for key, value in counter.items() if value > 1}
print(duplicates)
В данном примере создаётся словарь, где ключи – это элементы с повторениями, а значения – их количество. Это полезно, если необходимо получить только те элементы, которые встречаются больше одного раза.
Метод Counter значительно ускоряет процесс анализа списка, особенно если необходимо обработать большое количество данных. Он позволяет быстро выявить и обработать дубликаты, без необходимости вручную перебирать элементы и вести дополнительные подсчёты.
Как найти дубликаты с помощью стандартной функции filter()

Функция filter() в Python позволяет эффективно фильтровать элементы списка на основе заданного условия. Для поиска дубликатов она может быть использована в комбинации с функцией count(), что позволяет выявить повторяющиеся элементы в коллекции.
Для начала определим функцию, которая будет возвращать все элементы списка, встречающиеся более одного раза. Для этого используем filter() и lambda, которая будет проверять количество вхождений каждого элемента в исходный список:
numbers = [1, 2, 3, 4, 2, 5, 6, 1, 7] duplicates = list(filter(lambda x: numbers.count(x) > 1, numbers)) print(duplicates)
Этот код создаёт список duplicates, который будет содержать все повторяющиеся элементы исходного списка. Важно отметить, что данное решение не удаляет дубликаты, а только находит их все.
Так как filter() возвращает только те элементы, которые соответствуют условию (в данном случае, встречаются более одного раза), результат будет включать все такие элементы, не учитывая их частоту повторений. Чтобы избежать множественного появления одинаковых дубликатов в финальном списке, можно дополнительно преобразовать результат в set:
duplicates = list(set(filter(lambda x: numbers.count(x) > 1, numbers))) print(duplicates)
Этот подход позволяет избавиться от повторов, оставив только уникальные дубликаты.
Однако важно помнить, что использование count() для каждого элемента списка делает алгоритм менее эффективным при работе с большими данными, так как функция count() проходит по всему списку каждый раз для каждого элемента. В таких случаях лучше использовать более оптимизированные способы, такие как использование collections.Counter.
Поиск дубликатов с использованием итератора и генераторов
Для поиска дубликатов в списке Python можно использовать итераторы и генераторы, что позволяет эффективно обрабатывать большие данные, минимизируя затраты памяти. Суть подхода заключается в использовании возможности итераторов обрабатывать элементы по одному, не загружая все данные в память сразу.
Один из эффективных способов – создание генератора, который будет отслеживать элементы, встречавшиеся ранее, и сразу возвращать те, которые появляются повторно. Такой подход особенно полезен для работы с большими списками, где хранение всего набора данных в памяти может быть нецелесообразным.
Пример кода для поиска дубликатов с использованием генератора:
def find_duplicates(iterable): seen = set() for item in iterable: if item in seen: yield item else: seen.add(item)
В этом примере генератор find_duplicates последовательно обрабатывает элементы списка, проверяя, встречались ли они уже. Если элемент повторяется, он возвращается через yield, что позволяет не хранить все найденные дубликаты в памяти сразу.
Этот метод имеет несколько ключевых преимуществ. Во-первых, генератор возвращает дубликаты по мере их нахождения, а не после завершения обработки всего списка. Во-вторых, он использует структуру данных set, которая гарантирует быстрый поиск элементов, что делает решение эффективным по времени.
Если требуется модификация, чтобы собрать все дубликаты в список, можно обернуть вызов генератора в list(), например:
duplicates = list(find_duplicates(my_list))
Этот подход полезен, когда необходимо получить все дубликаты, но он будет менее эффективен, если вам достаточно только первого найденного дубликата или обработки элементов по мере их появления. В случае больших объемов данных использование генераторов позволяет избежать излишней загрузки памяти.
Кроме того, данный метод легко комбинируется с другими структурами данных, например, для более сложных случаев можно использовать словари или даже многозадачность, если необходимо параллельно обрабатывать несколько потоков данных.
Использование библиотеки pandas для нахождения повторяющихся элементов

Библиотека pandas предоставляет эффективные инструменты для работы с данными, включая поиск повторяющихся элементов в списках и таблицах. Для нахождения дубликатов в pandas используется метод duplicated(), который можно применить к Series или DataFrame.
Метод duplicated() возвращает булев массив, в котором для каждого элемента указано, является ли он повтором. По умолчанию метод считает дубликатом все элементы, начиная с первого, но можно настроить поведение с помощью параметров.
Пример использования:
import pandas as pd
data = [1, 2, 3, 2, 4, 5, 3]
series = pd.Series(data)
duplicates = series[series.duplicated()]
print(duplicates)
Для поиска дубликатов в DataFrame можно применить метод аналогично, но с учетом столбцов. Например:
df = pd.DataFrame({'A': [1, 2, 3, 2, 4, 5, 3], 'B': [10, 20, 30, 20, 40, 50, 30]})
duplicates = df[df.duplicated(subset=['A'])]
print(duplicates)
Здесь параметр subset указывает на столбцы, по которым нужно искать повторяющиеся значения. Если этот параметр не указан, проверяются все столбцы.
Для более точного контроля над поведением поиска можно использовать параметр keep, который позволяет выбрать, считать ли дубликатом только последующие или первые появления:
duplicates = series.duplicated(keep='last') # Дубликаты, начиная с последнего появления
Таким образом, pandas предоставляет мощные и гибкие методы для поиска повторяющихся элементов, что облегчает обработку данных в различных проектах.
Как удалить дубликаты в списке и сохранить порядок элементов
Первый шаг – создать новый пустой список для хранения уникальных элементов. Затем, проходя по каждому элементу исходного списка, проверяем, встречался ли этот элемент ранее. Если не встречался, добавляем его в новый список и в set, чтобы отслеживать уже добавленные элементы.
Пример кода:
unique_list = [] seen = set() for item in original_list: if item not in seen: unique_list.append(item) seen.add(item)
Этот метод позволяет эффективно удалять дубликаты, при этом сохраняется порядок появления элементов. Время выполнения алгоритма – O(n), где n – это количество элементов в исходном списке, поскольку проверка наличия элемента в set выполняется за O(1).
Второй способ – использовать конструкцию списка с условием и встроенную функцию not in, которая будет работать аналогично, но менее эффективно в плане читаемости при работе с большими данными.
Если задачи не требуют жесткой оптимизации, то существует также вариант с использованием dict.fromkeys(), который удаляет дубликаты и сохраняет порядок элементов, так как с Python 3.7 dict гарантирует порядок добавления ключей.
unique_list = list(dict.fromkeys(original_list))
Однако этот метод не всегда удобен, если нужно работать с не хешируемыми объектами, такими как списки или другие изменяемые типы данных.
Таким образом, комбинированный подход с использованием set и списка является самым универсальным и эффективным для удаления дубликатов с сохранением порядка элементов.
Реализация поиска дубликатов с помощью цикла for
Для поиска дубликатов в списке можно использовать цикл for в Python. Этот способ позволяет пройтись по каждому элементу списка и сравнить его с остальными, выявляя повторяющиеся значения.
Пример реализации:
def find_duplicates(lst):
duplicates = []
for i in range(len(lst)):
for j in range(i+1, len(lst)):
if lst[i] == lst[j] and lst[i] not in duplicates:
duplicates.append(lst[i])
return duplicates
В этом примере цикл for используется дважды: первый цикл перебирает элементы списка, а второй – сравнивает текущий элемент с последующими. Если два элемента равны, и этот элемент ещё не добавлен в список дубликатов, он добавляется в результат.
- Сложность алгоритма – O(n²), где n – количество элементов в списке. Это означает, что для больших списков такой подход может быть неэффективным.
- Алгоритм подходит для небольших коллекций, где важна простота реализации, а не производительность.
Для улучшения производительности можно использовать вспомогательные структуры данных, такие как множества, чтобы ускорить поиск. Но в контексте цикла for данный метод работает корректно, особенно в случае с небольшими данными.
Поиск дубликатов в списке с учетом регистра и пробелов
Когда необходимо найти дубликаты в списке с учетом регистра символов и пробелов, важным моментом становится правильная обработка строк, поскольку простое сравнение может привести к ошибкам, игнорируя эти аспекты.
Для поиска дубликатов в списке можно воспользоваться несколькими подходами, принимая во внимание, что строковые данные могут содержать различия в пробелах или в регистре букв. Рассмотрим несколько вариантов.
- Использование стандартной библиотеки Python. Например, можно создать множество, чтобы отслеживать встречающиеся элементы, при этом сохраняется точная форма строк. Использование множества обеспечивает быстрый поиск и исключение повторений.
Пример кода для поиска дубликатов, учитывающих пробелы и регистр:
data = ["Python", "python ", " Java", "java", "python", " Java "]
duplicates = []
seen = set()
for item in data:
if item in seen:
duplicates.append(item)
else:
seen.add(item)
print("Дубликаты:", duplicates)
Этот код находит дубликаты, но не игнорирует пробелы и различия в регистре, что делает его удобным для точных сравнений.
- Если требуется игнорировать пробелы и регистр, можно предварительно нормализовать строки. Один из способов – удалить лишние пробелы и привести строку к одному регистру.
Пример кода для нормализации строк перед сравнением:
data = ["Python", " python ", " Java", "java", "python", " Java "]
duplicates = []
seen = set()
for item in data:
normalized_item = item.strip().lower() # Убираем пробелы и приводим к нижнему регистру
if normalized_item in seen:
duplicates.append(item)
else:
seen.add(normalized_item)
print("Дубликаты (с учетом нормализации):", duplicates)
- Когда важна точность в определении дубликатов с учетом пробелов, рекомендуется использовать подход, при котором строки обрабатываются без нормализации. Это помогает избежать потери информации.
Однако, если задачей является определение дубликатов с учетом только текста без учета пробелов или регистра, использование нормализации всегда будет более эффективным методом.