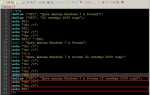
Для поиска повторяющихся слов в строке на Python можно использовать несколько подходов. Основной задачей является правильная обработка строки и эффективный поиск всех встречающихся слов. В данной статье рассмотрим, как быстро и просто найти такие слова с помощью встроенных возможностей Python.
Один из самых простых методов – это использование коллекции Counter из модуля collections. Это позволяет подсчитать количество каждого слова в строке и найти те, которые встречаются более одного раза. Пример кода для этого подхода:
from collections import Counter
text = "apple banana apple orange banana apple"
words = text.split()
word_counts = Counter(words)
repeated_words = [word for word, count in word_counts.items() if count > 1]
print(repeated_words)Если требуется работать с большим объемом данных, можно улучшить производительность, используя регулярные выражения и функции библиотеки re. Это особенно полезно, если слова могут быть разделены не только пробелами, но и различными знаками препинания.
Также стоит обратить внимание на использование множества (set) для хранения уникальных слов при поиске повторов. Это позволяет значительно ускорить процесс, избегая ненужных повторов в исходных данных.
Как разбить строку на слова с помощью Python

Для того чтобы разбить строку на отдельные слова в Python, используется метод split(). Этот метод делит строку на подстроки, основываясь на пробелах или другом разделителе. По умолчанию, метод разбивает строку по пробелам, но при необходимости можно задать свой разделитель.
Простой пример:
text = "Python - мощный язык программирования"
words = text.split()
print(words)Этот код выведет:
['Python', '-', 'мощный', 'язык', 'программирования']Если необходимо разделить строку по определённому символу, например, по запятой, то в split() можно передать символ-разделитель. Например:
text = "яблоки,бананы,груши"
words = text.split(',')
print(words)Этот код вернёт:
['яблоки', 'бананы', 'груши']Метод split() полезен при обработке текста, где необходимо извлечь отдельные элементы из строки. Важно помнить, что метод автоматически удаляет лишние пробелы между словами, что помогает избежать ненужных пустых элементов в результате разбиения.
Если нужно избавиться от пустых строк, можно использовать метод split() с аргументом, который указывает на символ, по которому будет происходить разбиение, или использовать регулярные выражения для более сложных случаев.
Использование словаря для подсчета повторений
Для нахождения повторяющихся слов в строке можно эффективно использовать словарь. Этот тип данных позволяет хранить уникальные элементы и подсчитывать количество их появлений. В Python для этого подойдёт структура данных dict, где ключами будут слова, а значениями – количество их повторений.
Пример кода для подсчета слов в строке:
text = "это пример строки с повторяющимися словами это пример"
words = text.split()
word_count = {}
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
print(word_count)В данном примере строка разделяется на слова с помощью метода split(). Далее, каждое слово проверяется на наличие в словаре. Если слово уже есть, увеличивается его счетчик, если нет – оно добавляется в словарь с начальным значением 1.
Для нахождения только повторяющихся слов можно фильтровать словарь, выбирая те, чье количество больше 1:
repeated_words = {word: count for word, count in word_count.items() if count > 1}
print(repeated_words)Этот подход позволяет быстро и эффективно определить слова, которые встречаются более одного раза, без необходимости в дополнительных циклах или сложных алгоритмах. Словарь в данном случае выступает не только для хранения данных, но и для их быстрого подсчета и фильтрации.
Как найти первое повторяющееся слово в строке
Для этого можно воспользоваться множеством (set), которое обеспечивает быструю проверку на наличие элемента. При обработке строки каждое слово добавляется в множество. Если слово уже присутствует в множестве, это значит, что оно повторяется.
Пример кода:
def find_first_duplicate(sentence):
words = sentence.split()
seen = set()
for word in words:
if word in seen:
return word
seen.add(word)
return None
sentence = "это пример строки с повторяющимся словом пример"
result = find_first_duplicate(sentence)
print(result)
Этот код разбивает строку на слова, проходится по ним и проверяет, встречалось ли уже слово. Как только повторяющееся слово найдено, оно возвращается. Если же строка не содержит повторов, возвращается None.
Метод с использованием множества работает быстро благодаря его свойствам. Операции добавления и проверки на присутствие выполняются за время O(1), что делает решение эффективным для строк с большим количеством слов.
Как вывести все повторяющиеся слова
Чтобы найти все повторяющиеся слова в строке на Python, можно использовать несколько методов. Один из наиболее эффективных способов – использовать словарь или коллекцию, чтобы отслеживать частоту каждого слова в строке.
Вот шаги, которые помогут найти все повторяющиеся слова:
- Приведите строку к единому формату (например, преобразуйте все символы в нижний регистр, чтобы избежать различий между большими и маленькими буквами).
- Разделите строку на слова с помощью метода
split()или регулярных выражений. - Используйте словарь для подсчёта количества каждого слова.
- Выведите только те слова, которые встречаются больше одного раза.
Пример кода:
text = "Python is great and Python is fun"
words = text.lower().split()
word_count = {}
for word in words:
word_count[word] = word_count.get(word, 0) + 1
repeated_words = [word for word, count in word_count.items() if count > 1]
print(repeated_words)
Этот код создаёт список повторяющихся слов из строки, игнорируя регистр символов. Полученный список будет содержать все слова, которые повторяются в строке.
Для более сложных случаев можно использовать регулярные выражения для более точного разделения строки на слова. Вот пример:
import re
text = "Python is great, Python is fun."
words = re.findall(r'\b\w+\b', text.lower())
word_count = {}
for word in words:
word_count[word] = word_count.get(word, 0) + 1
repeated_words = [word for word, count in word_count.items() if count > 1]
print(repeated_words)
Регулярное выражение \b\w+\b позволяет извлечь только слова, исключая знаки препинания.
Эти методы можно комбинировать и адаптировать под различные задачи, например, для поиска повторений без учёта символов пунктуации или с учётом различных вариантов написания слов.
Реализация поиска повторяющихся слов с использованием коллекций

Для нахождения повторяющихся слов в строке на Python можно эффективно использовать коллекцию Counter из модуля collections. Этот класс позволяет легко подсчитывать частоту появления каждого элемента в iterable объекте. Рассмотрим, как можно реализовать задачу поиска повторяющихся слов.
Основной подход заключается в следующем:
from collections import Counter
def find_repeated_words(text):
words = text.lower().split() # Преобразуем строку в список слов, игнорируя регистр
word_count = Counter(words) # Подсчитываем частоту каждого слова
return {word: count for word, count in word_count.items() if count > 1} # Возвращаем только повторяющиеся словаРассмотрим этот код на примере:
text = "Python is great and Python is easy"
print(find_repeated_words(text)) # Выведет: {'python': 2}В данном примере функция find_repeated_words сначала преобразует строку в нижний регистр и разбивает ее на отдельные слова. Затем с помощью Counter создается словарь, где ключами являются слова, а значениями – количество их повторений. Мы фильтруем этот словарь, оставляя только те слова, которые встречаются более одного раза.
Преимущество использования Counter заключается в высокой производительности при обработке больших объемов данных. В отличие от ручного подсчета через циклы, этот подход значительно ускоряет решение задачи, благодаря внутренней оптимизации коллекции.
Также стоит отметить, что использование split() в этом примере не учитывает знаки препинания. Если в строках могут присутствовать такие символы, можно предварительно очистить текст с помощью регулярных выражений или библиотеки re.
Как игнорировать регистр при поиске повторений
Для поиска повторяющихся слов в строке, игнорируя регистр, необходимо привести все символы к единому виду. Это поможет избежать ошибок, связанных с различиями между заглавными и строчными буквами. В Python для этого достаточно использовать методы строк, такие как lower() или casefold().
- Метод
lower(): преобразует все символы строки в нижний регистр. - Метод
casefold(): более гибкий, используется для игнорирования регистра в разных языках (например, для обработки букв с диакритическими знаками).
Пример использования метода lower():
text = "Python Python python"
words = text.lower().split()
repeat_count = {word: words.count(word) for word in set(words)}
print(repeat_count)
В данном примере все слова будут приведены к нижнему регистру перед поиском повторений.
Если необходимо учитывать не только точные совпадения, но и различные вариации слов с диакритическими знаками, стоит использовать casefold(), особенно если ваш текст включает в себя символы, которые могут быть представлены в разных формах в зависимости от регистра.
Пример с casefold():
text = "café Café cafe"
words = text.casefold().split()
repeat_count = {word: words.count(word) for word in set(words)}
print(repeat_count)
При таком подходе игнорируются все отличия в регистре и даже в диакритических символах, что дает более точный результат при поиске повторяющихся слов.
Для сложных случаев, когда важно учитывать особенности языка, casefold() будет лучшим выбором. Однако для простых случаев lower() тоже вполне подходит.
Как обрабатывать строки с несколькими пробелами между словами

В строках, содержащих несколько пробелов подряд, важно правильно управлять пробелами, чтобы избежать ошибок при анализе данных. В Python это можно легко решить с помощью метода split(), который разделяет строку по пробелам. При этом все лишние пробелы автоматически удаляются.
Пример:
text = "Это пример строки с несколькими пробелами."
words = text.split()
print(words) # ['Это', 'пример', 'строки', 'с', 'несколькими', 'пробелами.']
Метод split() по умолчанию удаляет все лишние пробелы, превращая несколько подряд идущих пробелов в один. Это гарантирует, что каждый элемент в списке будет отдельным словом.
Если нужно сохранить оригинальные пробелы, можно использовать регулярные выражения. Модуль re в Python позволяет точно указать, как обрабатывать пробелы в строках. Например, регулярное выражение \s+ найдет все последовательности пробелов и заменит их на один пробел.
Пример:
import re
text = "Это пример строки с несколькими пробелами."
cleaned_text = re.sub(r'\s+', ' ', text)
print(cleaned_text) # 'Это пример строки с несколькими пробелами.'
Это решение полезно, если нужно привести строку к единому виду перед дальнейшей обработкой или анализом.
Оптимизация поиска повторяющихся слов в больших строках
Для поиска повторяющихся слов в больших строках важно использовать методы, минимизирующие время обработки. Один из самых эффективных подходов – использование структуры данных, которая позволяет быстро проверять наличие элемента. Сет (set) или словарь (dictionary) в Python идеально подходят для этих целей. Они обеспечивают среднее время доступа O(1), что значительно ускоряет процесс по сравнению с обычным перебором всех элементов.
Пример с использованием множества (set) для поиска повторяющихся слов:
def find_repeated_words(text): words = text.split() seen = set() duplicates = set() for word in words: if word in seen: duplicates.add(word) seen.add(word) return duplicates
В данном примере слова разбиваются на список с помощью метода split(). Для каждого слова проверяется, встречалось ли оно ранее, и если да – оно добавляется в множество повторяющихся слов. Это решение работает за время O(n), где n – количество слов в строке.
Если строка содержит большое количество слов, можно улучшить производительность за счет параллельной обработки. Для этого можно разбить строку на несколько частей и обработать их в отдельных потоках, однако, стоит помнить о накладных расходах на создание и управление потоками. Для более масштабируемых решений стоит рассматривать использование библиотеки multiprocessing.
При работе с очень большими строками (например, многомегабайтными текстами) можно также воспользоваться подходом потоковой обработки данных, когда строка не загружается полностью в память, а обрабатывается по частям. Это позволяет значительно сократить потребление памяти и ускорить работу.
Для улучшения точности можно добавить нормализацию слов (удаление знаков препинания, приведение к нижнему регистру) перед их анализом, что повысит вероятность нахождения повторяющихся слов, несмотря на различия в форматировании текста.
Следует учитывать, что использование сложных алгоритмов, таких как хеширование или деревья поиска, может быть избыточным, если задача ограничивается поиском только повторяющихся слов в строках средней длины. В таких случаях более простые методы, основанные на множествах и списках, дают хорошее соотношение скорости и простоты реализации.