В списках Python дубликаты возникают чаще, чем может показаться. Особенно при обработке пользовательского ввода, работе с логами или анализе больших массивов данных. Чтобы выявить повторяющиеся элементы, важно учитывать не только производительность, но и читаемость кода. Решения могут различаться в зависимости от требований к скорости, памяти и порядку следования элементов.
Один из быстрых и наглядных способов – использовать модуль collections. Метод Counter позволяет определить частоту появления каждого элемента. Для извлечения только повторяющихся значений достаточно фильтрации словаря: [x for x, count in Counter(lst).items() if count > 1]. Такой подход сохраняет уникальные повторяющиеся элементы и работает за линейное время.
Если важен порядок первого появления дубликатов, подойдет использование множества и генератора: seen = set(); duplicates = set(x for x in lst if x in seen or seen.add(x)). Этот способ не считает количество повторений, но быстро находит все дубликаты без дополнительных библиотек.
При работе с вложенными структурами или объектами, где стандартное сравнение неприменимо, требуется кастомная логика сравнения. В таких случаях эффективнее использовать хеш-функции или сериализацию элементов перед добавлением в структуру учета. Это особенно важно при работе со списками словарей или экземплярами пользовательских классов.
Поиск повторов с использованием цикла и словаря
Использование словаря позволяет эффективно выявлять повторяющиеся элементы без необходимости многократных проходов по списку. Это особенно полезно при работе с большими объемами данных.
Алгоритм:
- Создать пустой словарь для хранения количества вхождений каждого элемента.
- Пройти по списку циклом и увеличивать счётчик для каждого элемента.
- После обхода отфильтровать те элементы, у которых количество больше одного.
Пример:
список = [3, 5, 3, 2, 8, 5, 6, 8, 8]
частоты = {}
for элемент in список:
if элемент in частоты:
частоты[элемент] += 1
else:
частоты[элемент] = 1
повторы = [элемент for элемент, количество in частоты.items() if количество > 1]
print(повторы) # [3, 5, 8]Рекомендации:
- Словарь подходит для любых хешируемых типов данных: числа, строки, кортежи.
- Если важен порядок появления, используйте
collections.OrderedDict(в Python 3.7+ обычныйdictуже сохраняет порядок). - Для подсчёта можно использовать
collections.Counter, но цикл сdictпозволяет тонко управлять логикой подсчёта.
Использование collections.Counter для подсчёта повторяющихся значений
Модуль collections предоставляет структуру Counter, которая эффективно подсчитывает количество вхождений каждого элемента в итерируемом объекте. Это особенно удобно для анализа повторяющихся значений в списках.
Для начала импортируется класс Counter: from collections import Counter. Далее достаточно передать список в конструктор: counter = Counter(список). Результат – объект, в котором ключами являются элементы списка, а значениями – количество их вхождений.
Для получения только повторяющихся значений можно использовать генератор словаря: {элемент: count for элемент, count in counter.items() if count > 1}. Это позволяет исключить уникальные элементы и сосредоточиться на дубликатах.
Если требуется отсортировать повторы по убыванию частоты, используется метод most_common(). Например, counter.most_common() вернёт список кортежей (элемент, количество), отсортированных по количеству вхождений.
Counter автоматически обрабатывает все типы, поддерживающие хеширование, включая строки, числа и кортежи. Это делает его универсальным инструментом для анализа дубликатов в сложных структурах данных.
Нахождение дубликатов с помощью множеств
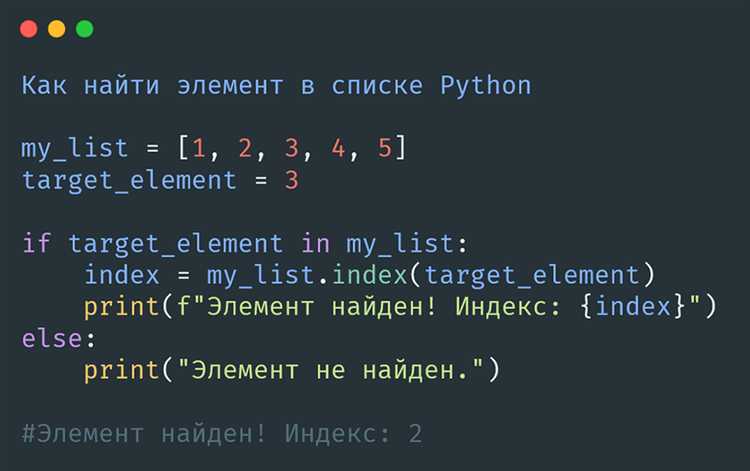
Множества в Python автоматически удаляют повторяющиеся элементы, что делает их эффективным инструментом для поиска дубликатов в списке. Для этого не требуется сторонних библиотек и операций сортировки.
- Создайте два множества: одно для хранения уникальных элементов, другое – для дубликатов.
- Итерируйтесь по списку, добавляя элементы в первое множество. Если элемент уже присутствует, добавьте его во второе множество.
def find_duplicates(lst):
seen = set()
duplicates = set()
for item in lst:
if item in seen:
duplicates.add(item)
else:
seen.add(item)
return list(duplicates)
- Функция работает за O(n), где n – длина списка.
- Порядок элементов не сохраняется, так как множества неупорядочены.
- Выход – список дубликатов без повторений.
Этот способ оптимален для больших списков, где важна производительность и не требуется сохранять порядок повторов.
Фильтрация списка для получения только повторяющихся элементов

Для получения только повторяющихся значений из списка используйте collections.Counter. Этот метод позволяет быстро определить частоту каждого элемента.
Пример:
from collections import Counter
список = [1, 2, 2, 3, 4, 4, 4, 5]
счетчик = Counter(список)
повторы = [элемент for элемент, количество in счетчик.items() if количество > 1]
print(повторы) # [2, 4]
Если необходимо получить полный список повторяющихся значений, включая дубликаты, используйте следующий подход:
повторяющиеся = [x for x in список if счетчик[x] > 1]
print(повторяющиеся) # [2, 2, 4, 4, 4]
Чтобы исключить лишние вызовы, создавайте Counter один раз и применяйте его к фильтрации. Не используйте list.count() в цикле – это приводит к квадратичной сложности и снижает производительность на больших данных.
Поиск индексов всех вхождений повторяющихся значений

Чтобы определить индексы всех повторяющихся элементов в списке, необходимо сначала выявить элементы, встречающиеся более одного раза, а затем собрать их позиции. Эффективный способ – использовать модуль collections и проход по списку с помощью enumerate.
from collections import Counter
lst = ['a', 'b', 'a', 'c', 'b', 'd', 'a']
# Определяем повторяющиеся элементы
counts = Counter(lst)
duplicates = {item for item, count in counts.items() if count > 1}
# Сохраняем индексы для каждого повторяющегося элемента
index_map = {}
for index, value in enumerate(lst):
if value in duplicates:
index_map.setdefault(value, []).append(index)
print(index_map)
Результатом будет словарь, где ключи – повторяющиеся значения, а значения – списки всех индексов их вхождений.
{'a': [0, 2, 6], 'b': [1, 4]}Если необходим список всех индексов без группировки по значению, можно использовать генератор:
all_duplicate_indices = [i for i, v in enumerate(lst) if counts[v] > 1]
print(all_duplicate_indices)
[0, 1, 2, 4, 6]Такой подход позволяет точно определить позиции всех повторов и использовать их для последующей фильтрации, анализа или визуализации данных.
Сравнение подходов по читаемости и удобству реализации
1. Использование collections.Counter – самый читаемый способ для определения повторяющихся элементов. Подходит для списков с хешируемыми элементами. Код из двух строк, результат – словарь с подсчётом. Недостаток – необходимость импорта и невозможность применения к спискам с изменяемыми объектами.
Пример: from collections import Counter; [x for x, c in Counter(lst).items() if c > 1]
2. Множества (set) обеспечивают лаконичную реализацию с минимальной зависимостью. Хорошо читается, но теряет счётчик вхождений. Требует ручного ведения двух множеств – seen и duplicates. Подходит, когда интересует только факт повторения.
Пример: seen = set(); dupes = set(x for x in lst if x in seen or seen.add(x))
3. Списковое включение с count() – визуально просто, но неприемлемо для больших списков. Каждый вызов count() проходит по всему списку, что делает подход непрактичным при размере от нескольких тысяч элементов.
Пример: [x for x in lst if lst.count(x) > 1]
4. Цикл с индексами и словарём позволяет реализовать контроль и модификацию логики. Оптимально при нестандартных условиях фильтрации. Читаемость страдает из-за увеличения объёма кода. Используется, когда необходима гибкость.
Пример: counts = {}; duplicates = []; for x in lst: counts[x] = counts.get(x, 0) + 1; if counts[x] == 2: duplicates.append(x)