Произведение элементов массива в Python можно вычислить несколькими способами. Это полезная операция, которая часто встречается при решении задач на анализ числовых данных. В стандартной библиотеке Python нет специальной функции для вычисления произведения, но задача решается достаточно просто с использованием циклов или встроенных функций.
Один из самых простых способов – использование цикла. Пройдя по каждому элементу массива, можно последовательно умножать его на накопленную переменную. Однако, если ваша цель – улучшить читаемость кода, то лучше воспользоваться функцией reduce из модуля functools или встроенной функцией math.prod(), доступной с Python 3.8.
Для решения задачи с использованием reduce достаточно передать в эту функцию операцию умножения и массив. Рассмотрим пример:
from functools import reduce
arr = [1, 2, 3, 4]
result = reduce(lambda x, y: x * y, arr)
print(result) # Выведет 24
Для более простого и современного решения можно использовать функцию math.prod(), которая специально предназначена для вычисления произведения чисел в последовательности:
import math
arr = [1, 2, 3, 4]
result = math.prod(arr)
print(result) # Выведет 24
Этот метод гораздо быстрее и проще в реализации, чем использование циклов или reduce, особенно в случае работы с большими массивами.
Использование цикла for для вычисления произведения элементов

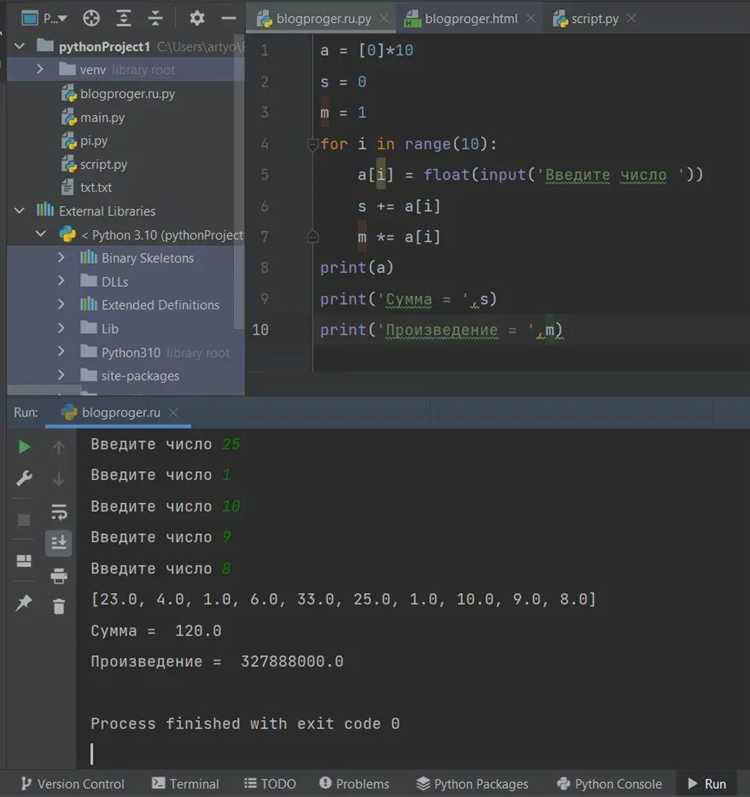
Для вычисления произведения элементов массива в Python часто используется цикл for. Это простое решение, которое позволяет последовательно умножать все элементы массива и получить итоговый результат.
Основной принцип работы заключается в инициализации переменной, которая будет хранить промежуточный результат, и последовательном умножении ее на каждый элемент массива. Важно помнить, что начальное значение этой переменной должно быть равно 1, чтобы не повлиять на итоговое произведение.
Пример кода:
arr = [2, 3, 4, 5]
result = 1
for num in arr:
result *= num
print(result)
В этом примере создается список arr, содержащий элементы, которые нужно перемножить. Переменная result инициализируется значением 1. Каждый элемент массива поочередно умножается на result, и в конце мы получаем произведение всех элементов.
Такой подход эффективно работает с любыми списками чисел, включая отрицательные значения и нули. Если в массиве встречается ноль, произведение сразу станет равно нулю. Однако стоит учесть, что этот метод не будет работать с пустыми массивами, для которых следует предусмотреть отдельную проверку.
Пример с проверкой на пустой список:
arr = []
if arr:
result = 1
for num in arr:
result *= num
print(result)
else:
print("Массив пустой.")
Использование цикла for позволяет легко управлять процессом умножения и гарантирует, что все элементы массива будут учтены. Это решение удобно и понятно, особенно для начинающих разработчиков, так как не требует дополнительных библиотек или сложных конструкций.
Применение функции reduce из модуля functools
Функция reduce из модуля functools позволяет выполнить накопление значений в процессе обхода массива. Она применяет указанную функцию к элементам последовательности, начиная с первого, и передает результат в качестве аргумента для следующей итерации. Это особенно удобно для вычислений, таких как нахождение произведения всех элементов массива.
Чтобы найти произведение всех элементов массива с помощью reduce, необходимо использовать функцию, которая будет принимать два аргумента (аккумулятор и текущий элемент массива), умножать их и возвращать результат. В конце работы reduce возвращает итоговое значение, которое будет являться произведением всех элементов последовательности.
Пример кода для нахождения произведения элементов списка:
from functools import reduce numbers = [1, 2, 3, 4, 5] result = reduce(lambda x, y: x * y, numbers)
В этом примере функция lambda служит для выполнения умножения двух чисел. На каждой итерации результат предыдущей операции передается в следующий шаг, и так продолжается до конца списка.
Важно помнить, что reduce не имеет начального значения по умолчанию. Если список пуст, это вызовет ошибку. Чтобы избежать таких случаев, можно указать начальное значение с помощью аргумента initial. Например:
result = reduce(lambda x, y: x * y, numbers, 1)
Этот вариант гарантирует, что если список пуст, результат будет равен 1.
Использование reduce делает код компактным и функциональным, но следует помнить, что его использование не всегда оправдано, если для решения задачи есть более простые и понятные способы, такие как использование цикла for или встроенных функций, например, math.prod.
Как найти произведение с помощью библиотеки NumPy

Основной синтаксис функции следующий:
numpy.prod(a, axis=None, dtype=None, out=None, keepdims=False)Здесь a – это входной массив, а axis определяет ось, по которой будет вычисляться произведение (по умолчанию None, что означает, что произведение считается для всех элементов массива). Параметр dtype позволяет указать тип данных для результата, а keepdims контролирует сохранение размерности результата.
Пример вычисления произведения всех элементов одномерного массива:
import numpy as np
arr = np.array([2, 3, 4])
result = np.prod(arr)
print(result) # Выведет 24Для многомерных массивов можно использовать параметр axis, чтобы вычислить произведение по конкретной оси. Например, для двумерного массива:
arr2d = np.array([[1, 2, 3], [4, 5, 6]])
result_axis0 = np.prod(arr2d, axis=0) # По столбцам
result_axis1 = np.prod(arr2d, axis=1) # По строкам
print(result_axis0) # Выведет [ 4 10 18]
print(result_axis1) # Выведет [ 6 120]Если необходимо учитывать только элементы с определёнными условиями, можно использовать маски, например, с булевыми выражениями:
arr = np.array([1, 2, 3, 4, 5])
mask = arr > 2
result = np.prod(arr[mask])
print(result) # Выведет 60 (3 * 4 * 5)Библиотека NumPy значительно ускоряет операции с большими массивами и является предпочтительным выбором для вычислений в области численных данных.
Поиск произведения с использованием генераторов

Для вычисления произведения элементов массива с помощью генераторов можно использовать встроенную функцию reduce из модуля functools. Генераторы создают последовательности данных на лету, а не хранят их в памяти, что делает код более быстрым и экономичным по ресурсам.
Пример вычисления произведения элементов массива с использованием генератора:
from functools import reduce
arr = [2, 3, 4, 5]
result = reduce(lambda x, y: x * y, (i for i in arr))
print(result)
Здесь используется генератор (i for i in arr), который последовательно передает элементы массива в функцию reduce, умножая их на каждом шаге. Такой подход минимизирует память, так как элементы массива обрабатываются по одному.
Вместо явного использования генератора можно использовать генераторные выражения внутри reduce, что сокращает код, не теряя в эффективности:
result = reduce(lambda x, y: x * y, (i for i in arr if i != 0))
- Генераторные выражения полезны для фильтрации элементов до выполнения операций, таких как умножение.
- Если в массиве есть нули, использование фильтрации (например,
if i != 0) позволяет избежать обнуления результата произведения.
Когда массив данных очень большой, использование генераторов становится еще более важным, так как это позволяет не загружать все элементы в память одновременно, а обрабатывать их по мере необходимости. Это также предотвращает создание промежуточных копий данных, что может существенно ускорить выполнение программы.
Обработка пустых массивов и ошибок при вычислениях
Если массив пуст, умножение всех его элементов на Python может быть интерпретировано как ошибка. Стандартный подход к обработке пустых массивов – это проверка длины массива перед выполнением вычислений. Например, можно использовать условие:
if len(arr) == 0: result = 1 # Инициализация результата как нейтрального элемента для умножения else: result = 1 for num in arr: result *= num
Если массив пуст, то результатом будет 1, поскольку нейтральный элемент для операции умножения – это 1. Это позволяет избежать ошибок и корректно обработать ситуацию, когда нет элементов для умножения.
Другой вариант – использование встроенных функций, таких как functools.reduce, которая также требует проверки на пустой массив, чтобы избежать исключений, таких как ValueError.
Кроме того, при вычислениях может возникать ряд других ошибок: деление на ноль или переполнение при обработке очень больших чисел. Для таких случаев стоит предусмотреть дополнительные проверки или обрабатывать исключения через конструкцию try-except:
try:
result = 1
for num in arr:
result *= num
except ZeroDivisionError:
print("Ошибка: деление на ноль.")
except OverflowError:
print("Ошибка: переполнение при вычислениях.")
Эти меры позволят эффективно обрабатывать возможные ошибки и обеспечат корректность вычислений, независимо от содержимого массива.
Оптимизация вычислений для больших массивов
Для работы с большими массивами важно учитывать не только правильность алгоритма, но и его эффективность. Когда массивы достигают значительных размеров, стандартные методы могут привести к излишним затратам времени и памяти. Рассмотрим несколько ключевых методов оптимизации вычислений в Python.
Одним из способов ускорить вычисления является использование библиотеки numpy, которая реализует операции над массивами на C, что позволяет значительно уменьшить время выполнения. В отличие от стандартных списков Python, numpy использует массивы с фиксированным типом данных, что минимизирует накладные расходы и повышает производительность.
Еще одной важной практикой является использование параллельных вычислений. Например, для больших массивов, которые не помещаются в память, можно применить многозадачность с использованием библиотеки multiprocessing или библиотеки concurrent.futures. Разбиение массива на части и параллельная обработка этих частей позволяет эффективно распределять нагрузку между процессами.
Для экономии памяти следует избегать создания лишних копий массива. Вместо этого используйте ссылки на существующие данные или методы, которые модифицируют массивы на месте. Например, вместо создания нового массива для хранения произведений, можно использовать метод reduce() из модуля functools, который позволяет вычислять произведение элементов без создания промежуточных списков.
Также стоит обратить внимание на использование алгоритмов, которые уменьшают количество операций. Например, для произведения всех элементов массива можно использовать логическое сокращение. Если один из элементов массива равен нулю, дальнейшие вычисления можно прекратить, так как результат уже будет равен нулю.
Использование специализированных структур данных, таких как deque из модуля collections, помогает ускорить обработку больших объемов данных за счет более эффективного доступа к элементам на разных концах массива. Это особенно полезно при многократном добавлении или удалении элементов в процессе вычислений.
Соблюдение этих рекомендаций поможет существенно ускорить работу с большими массивами, снизить использование памяти и улучшить общую производительность программы.
Как использовать рекурсию для нахождения произведения

Рекурсия позволяет решить задачу нахождения произведения элементов массива, последовательно умножая элементы и вызывая функцию для оставшихся элементов. Этот подход подходит для маленьких массивов, но его также можно использовать для больших данных при корректной оптимизации.
Рассмотрим пример реализации функции для нахождения произведения с использованием рекурсии:
def multiply_recursive(arr): if len(arr) == 1: # базовый случай: массив состоит из одного элемента return arr[0] else: return arr[0] * multiply_recursive(arr[1:])
Здесь:
- Функция
multiply_recursiveпринимает массивarrв качестве аргумента. - Если массив состоит из одного элемента, то возвращается этот элемент, это базовый случай рекурсии.
- Если элементов больше, функция возвращает произведение первого элемента массива и рекурсивного вызова для оставшейся части массива.
Пример использования функции:
arr = [2, 3, 4, 5] result = multiply_recursive(arr) print(result) # Выведет 120
Такой способ подходит для небольших массивов, но рекурсия может стать неэффективной для больших данных из-за возможного переполнения стека вызовов. Чтобы избежать этого, можно использовать итеративный подход или преобразовать рекурсию в хвостовую рекурсию, что поддерживает оптимизация в некоторых языках программирования, но Python такой оптимизации не поддерживает.
Рекурсия может быть полезной, когда необходимо решить задачу с минимальными изменениями в коде и когда размер массива предсказуем. Тем не менее, для больших массивов рекомендуется использовать более эффективные итеративные алгоритмы.