Для реального параллельного выполнения нескольких функций следует использовать модуль multiprocessing, который запускает процессы независимо друг от друга. Это позволяет обойти GIL и равномерно распределить нагрузку между ядрами CPU. Например, вызов multiprocessing.Pool().map() позволяет параллельно обрабатывать данные, передавая каждую задачу отдельному процессу.
В асинхронных задачах, таких как сетевые запросы или взаимодействие с файловой системой, более эффективным будет использование asyncio в сочетании с неблокирующими библиотеками. Асинхронный запуск функций экономит ресурсы и позволяет масштабировать нагрузку без создания избыточного количества потоков или процессов.
Для гибридных сценариев применимы такие решения, как concurrent.futures, предоставляющий удобные интерфейсы для управления как потоками (ThreadPoolExecutor), так и процессами (ProcessPoolExecutor). Эти инструменты обеспечивают читаемость кода и упрощают обработку результатов параллельного выполнения с помощью futures.
Использование модуля threading для параллельного выполнения функций

- Каждая функция запускается через экземпляр
Thread, который принимает аргументtargetи дополнительные аргументы черезargs. - Поток запускается методом
start(), а ожидание завершения – черезjoin().
import threading
def worker(id):
print(f"Поток {id} начал работу")
threads = []
for i in range(5):
t = threading.Thread(target=worker, args=(i,))
t.start()
threads.append(t)
for t in threads:
t.join()
Запуск сразу нескольких потоков позволяет существенно сократить время выполнения I/O-задач. Однако интерпретатор Python (CPython) использует GIL – глобальную блокировку интерпретатора, которая ограничивает параллелизм при работе с CPU-нагруженными функциями.
- Для синхронизации между потоками используйте
Lock,RLock,Semaphore. - Исключайте одновременный доступ к разделяемым переменным без блокировок.
- Избегайте создания большого количества потоков – оптимально не более 100 одновременно.
lock = threading.Lock()
def safe_print(msg):
with lock:
print(msg)
threading – инструмент, требующий осторожности. Нарушения синхронизации легко приводят к трудноуловимым ошибкам. Для более высокоуровневых сценариев рассмотрите concurrent.futures.ThreadPoolExecutor.
Когда применять multiprocessing вместо threading
multiprocessing эффективен при выполнении задач, перегруженных вычислениями и использующих CPU, так как позволяет задействовать несколько ядер процессора. В отличие от threading, где потоки работают в рамках одного процесса и ограничены GIL (Global Interpreter Lock), каждый процесс в multiprocessing запускается независимо, обходя это ограничение.
Если задача включает параллельную обработку больших массивов чисел, машинное обучение, рендеринг изображений, шифрование или другие ресурсоёмкие расчёты – предпочтительнее использовать multiprocessing. Например, умножение матриц или рекурсивные вычисления чисел Фибоначчи значительно ускоряются за счёт запуска отдельных процессов.
Также multiprocessing следует выбирать, когда требуется изоляция между задачами. В случае критических сбоев один процесс не повлияет на другие. Это важно для надёжных систем, где каждая задача должна быть защищена от ошибок соседней.
Если время выполнения одного задания превышает 1–2 секунды и при этом процессор загружен на 80% и выше, переход к multiprocessing даст прирост производительности. Особенно это заметно на многоядерных машинах.
Не стоит использовать multiprocessing для I/O-операций, сетевых запросов или управления пользовательским интерфейсом – в этих случаях threading будет экономичнее по памяти и быстрее при старте потоков.
Создание пула процессов с помощью concurrent.futures
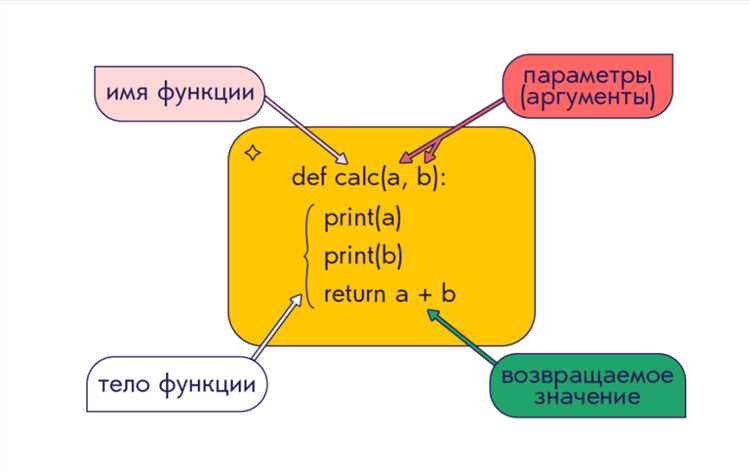
Модуль concurrent.futures предоставляет интерфейс высокого уровня для параллельного выполнения задач с использованием пула процессов. Для CPU-интенсивных операций предпочтителен ProcessPoolExecutor, так как он использует отдельные процессы, обходя GIL.
Пример запуска пула процессов:
from concurrent.futures import ProcessPoolExecutor, as_completed
def compute(x):
return x * x
with ProcessPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(compute, i) for i in range(10)]
for future in as_completed(futures):
print(future.result())
max_workers: выбирается в зависимости от количества ядер. Для большинства задач эффективно значение, равноеos.cpu_count().submit(): отправляет задачу на выполнение, возвращает объектFuture.as_completed(): итерирует завершённые задачи в порядке их окончания, не запуска.
Если необходимо получить результаты в порядке исходных данных, используйте:
results = list(executor.map(compute, range(10)))
map()блокирует до завершения всех задач, возвращает результаты по порядку аргументов.
Рекомендации по использованию:
- Избегайте передачи несериализуемых объектов (например, открытых файлов или сокетов).
- Оборачивайте код запуска в
if __name__ == "__main__"для совместимости с Windows и предотвращения рекурсии при создании процессов. - Контролируйте количество одновременно выполняемых задач через
max_workersво избежание чрезмерной загрузки системы.
Обработка результатов параллельных функций
Результаты параллельных вычислений зависят от способа организации выполнения. При использовании модуля concurrent.futures с ThreadPoolExecutor или ProcessPoolExecutor, объект Future предоставляет метод result() для получения результата выполнения задачи. Однако прямой вызов future.result() блокирует поток до завершения задачи. Чтобы избежать потери производительности, используйте as_completed() для последовательной обработки завершённых задач.
Пример эффективной обработки:
from concurrent.futures import ThreadPoolExecutor, as_completed
def compute(x):
return x * x
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(compute, i) for i in range(10)]
for future in as_completed(futures):
print(future.result())
Если важен порядок результатов, используйте map() вместо submit(). Она блокирует до завершения всех задач, но сохраняет порядок входных данных:
with ThreadPoolExecutor() as executor:
results = list(executor.map(compute, range(10)))
При работе с multiprocessing и Pool можно использовать apply_async() с колбэками для немедленной обработки результата без ожидания завершения всех задач:
from multiprocessing import Pool
def compute(x):
return x * x
def handle_result(res):
print(res)
with Pool(processes=4) as pool:
for i in range(10):
pool.apply_async(compute, args=(i,), callback=handle_result)
pool.close()
pool.join()
Для сбора всех результатов без блокировки используйте Manager().list() или очередь:
from multiprocessing import Pool, Manager
def compute(x):
return x * x
with Manager() as manager:
results = manager.list()
def collect(r): results.append(r)
with Pool(4) as pool:
for i in range(10):
pool.apply_async(compute, args=(i,), callback=collect)
pool.close()
pool.join()
print(list(results))
Исключения необходимо обрабатывать явно: у объекта Future метод exception() возвращает исключение, если оно произошло. Это предотвращает незаметные ошибки:
for future in as_completed(futures):
if future.exception():
print(f"Ошибка: {future.exception()}")
else:
print(f"Результат: {future.result()}")
Передача аргументов в функции при параллельном запуске
При использовании модуля concurrent.futures, аргументы передаются в функции через параметр args при помощи метода executor.submit(). Например, вызов executor.submit(func, arg1, arg2) корректно передаёт два позиционных аргумента в func.
Для передачи нескольких наборов аргументов удобно использовать executor.map(), но он принимает только один итерируемый объект. Чтобы передать несколько параметров, нужно использовать zip. Пример: executor.map(func, zip(list1, list2)) при условии, что func принимает один кортеж и внутри выполняется распаковка.
Если используется multiprocessing.Pool, передача аргументов осуществляется аналогично: pool.apply_async(func, args=(arg1, arg2)). Все аргументы передаются в виде одного кортежа. При использовании starmap каждый элемент входного списка должен быть кортежем с позиционными аргументами: pool.starmap(func, [(a1, b1), (a2, b2)]).
Для передачи именованных аргументов необходимо использовать обёртку, например, через functools.partial или лямбда-функцию: executor.submit(lambda: func(arg1=value1, arg2=value2)). Это позволяет явно указать, какие параметры будут использоваться, и избежать конфликтов при изменении сигнатуры функции.
Нельзя передавать нестабильные объекты, например, соединения с базами данных или сокеты, между процессами. Для потоков (через ThreadPoolExecutor) это допустимо, но требует синхронизации, если объекты изменяемые.
Избегайте передачи больших структур данных, так как при межпроцессном взаимодействии они сериализуются через pickle, что создаёт нагрузку на CPU и увеличивает задержку запуска. Оптимальный подход – передавать только минимально необходимую информацию.
Ограничение количества одновременно работающих потоков или процессов

При параллельном выполнении задач на Python часто возникает необходимость ограничить количество одновременно работающих потоков или процессов. Это связано с тем, что слишком большое количество параллельных задач может привести к перегрузке системы, снижению производительности или даже сбоям из-за нехватки ресурсов.
В стандартной библиотеке Python для многозадачности используются модули threading и multiprocessing, каждый из которых имеет свои особенности. Для эффективного управления числом одновременно работающих объектов можно использовать пул потоков или процессов.
Для управления количеством потоков в модуле threading можно использовать класс ThreadPoolExecutor из библиотеки concurrent.futures. С помощью этого класса можно задать максимальное количество одновременно работающих потоков, что позволяет контролировать использование CPU и избегать излишней загрузки системы.
Пример использования:
from concurrent.futures import ThreadPoolExecutor
def task(n):
print(f"Задача {n} выполняется")
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(task, range(10))
В этом примере максимальное количество параллельных потоков ограничено пятью. Это значит, что одновременно будет выполняться не более пяти задач, несмотря на то, что их всего десять.
Для работы с процессами используется модуль multiprocessing, который предоставляет аналогичные возможности. Класс Pool позволяет ограничить число параллельно работающих процессов через параметр processes. Это особенно важно для задач, требующих интенсивных вычислений, где многозадачность может быть ограничена возможностями процессора.
Пример с использованием multiprocessing.Pool:
from multiprocessing import Pool
def task(n):
print(f"Процесс {n} выполняется")
with Pool(processes=4) as pool:
pool.map(task, range(10))
В этом примере одновременно могут работать не более четырех процессов. Такой подход помогает эффективно использовать ресурсы, избегая излишней нагрузки на систему.
Обработка исключений внутри параллельно выполняемых функций
Один из эффективных способов управления исключениями – это использование механизма `try-except` внутри самой параллельной функции. Таким образом, каждое исключение будет перехвачено и обработано локально, не влияя на выполнение других потоков или процессов. Однако важно, чтобы в блоке `except` выполнялись действия, которые могут гарантировать безопасность работы программы, такие как логирование ошибок или отправка уведомлений.
Для многозадачности в Python можно использовать `concurrent.futures.ThreadPoolExecutor` или `ProcessPoolExecutor`. В этих случаях важно помнить, что исключения внутри параллельных задач не передаются в главный поток, если не настроить их обработку должным образом. Один из подходов – это возвращать результат выполнения функции в виде объекта, который может содержать как нормальный результат, так и информацию о возникшей ошибке.
Пример с использованием `ThreadPoolExecutor`:
«`python
from concurrent.futures import ThreadPoolExecutor, as_completed
def task(n):
if n == 3:
raise ValueError(«Ошибка в задаче»)
return n * 2
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(task, i) for i in range(5)]
for future in as_completed(futures):
try:
result = future.result()
print(result)
except Exception as e:
print(f»Произошла ошибка: {e}»)
cssEditВ этом примере, если в одной из задач возникнет исключение, оно будет перехвачено внутри блока `try-except`, и программа продолжит выполнение.
При использовании `ProcessPoolExecutor` можно столкнуться с аналогичной ситуацией. Однако исключения в процессе могут быть не так легко обработаны, поскольку процессы работают в отдельных адресных пространствах. Для корректной обработки исключений следует использовать механизм возврата ошибок через специальные объекты, такие как `concurrent.futures.Future` или использовать очередь `multiprocessing.Queue` для передачи данных и ошибок между процессами.
В случае с многозадачностью важно помнить, что исключения, возникающие в параллельных задачах, могут оставаться неучтенными, если они не обрабатываются или не передаются обратно в главный процесс. Рекомендуется всегда учитывать возможность возникновения ошибок и заранее продумывать механизм обработки, чтобы избежать несанкционированных сбоев в работе программы.
Диагностика и отладка проблем при параллельном выполнении

Параллельное выполнение функций в Python может привести к проблемам, связанным с синхронизацией, блокировками и состоянием разделяемых ресурсов. Чтобы эффективно диагностировать и устранять эти ошибки, важно понимать ключевые механизмы параллелизма и правильно организовывать тестирование кода.
Первым шагом в диагностике является использование логирования. В отличие от обычных ошибок, которые можно отследить через исключения, проблемы с параллельным выполнением часто не вызывают явных сбоев, а проявляются через неожиданные результаты. Вставка логов в критичные участки кода, особенно в моменты начала и завершения задач, поможет отслеживать поведение функций и выявить несоответствия. Рекомендуется использовать модуль logging, который позволяет более гибко управлять уровнем логирования и записывать данные в файл.
При отладке многозадачных приложений полезно использовать отладчики, такие как pdb, однако отладка параллельных процессов или потоков может быть затруднена. Программы с параллельным выполнением могут вызывать гонки данных или другие трудные для воспроизведения ошибки, особенно если они касаются состояний, изменяемых в разных потоках. Для таких случаев стоит использовать инструменты, такие как faulthandler или встроенную поддержку отслеживания состояния с помощью модулей multiprocessing и threading.
Одной из самых распространённых проблем является гонка потоков. Это происходит, когда несколько потоков пытаются одновременно получить доступ к одному и тому же ресурсу, что приводит к некорректным или неожиданным результатам. Для диагностики гонок можно использовать такие инструменты, как race condition detectors, или добавлять явную синхронизацию через объекты блокировки, например, Lock из модуля threading.
Ошибки, связанные с блокировками, также часто возникают при параллельной работе с ресурсами. Это может проявляться в виде зависания программы или долгого ожидания доступа к данным. Чтобы минимизировать такие проблемы, рекомендуется следить за использованием блокировок и их порядком. Блокировки, захваченные в неправильной последовательности, могут вызвать дедлоки, которые приводят к полной остановке приложения. Анализ последовательности захвата блокировок и использование таймаутов для выхода из ситуации могут помочь в предотвращении таких проблем.
Иногда параллельное выполнение может привести к проблемам с памятью, особенно при использовании процессов (а не потоков), когда каждый процесс использует собственную память. Для диагностики утечек памяти стоит использовать инструменты, такие как objgraph или memory_profiler, которые помогут отслеживать объекты, не освобожденные после завершения работы процессов.
Вопрос-ответ:
Какие способы параллельного запуска функций существуют в Python?
В Python можно использовать несколько методов для параллельного выполнения функций. Один из самых популярных — это использование модуля `threading` для многозадачности с потоками, который позволяет запускать функции параллельно в отдельных потоках. Также можно использовать модуль `multiprocessing`, который создает отдельные процессы для каждой функции, что помогает эффективно использовать многоядерные процессоры. Для выполнения задач, требующих асинхронности, подойдет библиотека `asyncio`, позволяющая работать с асинхронными функциями и выполнять их параллельно в одном потоке.
В чем отличие между многозадачностью с потоками и многозадачностью с процессами?
Основное различие заключается в том, как работают потоки и процессы. Потоки (использующие модуль `threading`) разделяют один и тот же адрес памяти, что позволяет экономить ресурсы и обмениваться данными быстрее. Однако потоки могут столкнуться с проблемой «GIL» (Global Interpreter Lock), которая ограничивает возможность одновременного выполнения операций. В отличие от потоков, процессы (модуль `multiprocessing`) используют отдельные пространства памяти, что позволяет более эффективно использовать многозадачные системы, но обмен данными между процессами требует больше затрат. Таким образом, потоки хороши для ввода-вывода, а процессы — для вычислений, где необходимо использовать всю мощность процессора.
Как можно использовать библиотеку `asyncio` для параллельного запуска нескольких функций?
Библиотека `asyncio` в Python позволяет выполнять асинхронные функции параллельно в одном потоке. Для этого нужно использовать ключевое слово `async` перед определением функции, а для ее вызова — `await`. Для запуска нескольких асинхронных функций параллельно можно использовать `asyncio.gather()`, которая позволяет передать несколько задач в одном вызове. Пример кода:
Когда стоит использовать многозадачность с потоками, а когда с процессами?
Многозадачность с потоками полезна, когда задачи в основном выполняют операции ввода-вывода, такие как ожидание данных от сети или взаимодействие с диском. Потоки хорошо справляются с параллельным выполнением таких задач, поскольку они используют общий адрес памяти и позволяют эффективно обмениваться данными. Однако если задача требует интенсивных вычислений (например, обработка больших объемов данных или выполнение математических операций), лучше использовать многозадачность с процессами, так как процессы не сталкиваются с ограничениями GIL и могут использовать все ядра процессора для вычислений.
Как синхронизировать работу нескольких потоков в Python?
Для синхронизации работы нескольких потоков в Python можно использовать объекты из модуля `threading`, такие как `Lock`, `Event` или `Semaphore`. Например, `Lock` позволяет блокировать доступ к ресурсу, чтобы избежать одновременной записи в общую переменную из нескольких потоков. Когда поток захватывает `Lock`, другие потоки вынуждены ждать, пока он не освободит ресурс. Пример использования `Lock`: