Алфавит в Python – это один из инструментов, который может значительно упростить работу с текстовыми данными. В языке программирования Python существует несколько встроенных методов для манипуляции строками, основанных на алфавитных символах. Эти методы позволяют эффективно анализировать, преобразовывать и фильтровать текст, что особенно полезно при обработке данных, содержащих текстовую информацию.
Для работы с алфавитами часто используется модуль string, который предоставляет наборы символов, такие как string.ascii_letters, string.ascii_lowercase и string.ascii_uppercase. Эти строки позволяют легко фильтровать и манипулировать символами, определяя, является ли конкретный символ буквой, цифрой или другим специальным символом. Например, метод isalnum() позволяет определить, состоит ли строка только из букв и цифр, что может быть полезно для валидации ввода.
Использование алфавита особенно важно при решении задач, связанных с кодированием и шифрованием данных. В таких случаях может понадобиться построение алгоритмов, которые работают с символами алфавита. Например, для реализации шифра Цезаря достаточно сдвигать буквы алфавита на фиксированное количество позиций. Это можно легко реализовать с помощью списка или строки, содержащей все буквы в нужном регистре, что позволяет проводить дешифровку и шифровку в несколько строк кода.
Использование библиотеки string для работы с алфавитом
Библиотека string в Python предоставляет полезные инструменты для работы с текстами и алфавитами. В контексте обработки данных её возможности значительно упрощают задачи, связанные с манипуляциями с буквами и символами. В частности, она предоставляет строковые константы для латинского алфавита, включая как строчные, так и заглавные буквы.
Основная особенность string – это наличие предопределённых строк, таких как string.ascii_lowercase, string.ascii_uppercase, string.digits, которые содержат все строчные и заглавные буквы латинского алфавита, а также цифры от 0 до 9. Эти константы идеально подходят для различных операций с символами, например, проверки наличия буквы в тексте или генерации случайных строк.
Для выполнения таких операций можно использовать несколько методов. Например, чтобы проверить, является ли символ буквой, можно воспользоваться оператором in в сочетании с string.ascii_letters, который включает и строчные, и заглавные буквы:
import string
if char in string.ascii_letters:
print("Это буква.")
Вместо того чтобы вручную задавать диапазоны символов, можно легко получить алфавит с помощью string.ascii_lowercase или string.ascii_uppercase. Например, для генерации всех строчных букв алфавита:
import string
alphabet = string.ascii_lowercase
print(alphabet) # abcdefghijklmnopqrstuvwxyz
Также библиотека предоставляет функцию string.punctuation, которая содержит все знаки препинания. Это может быть полезно при фильтрации текста или удалении символов, которые не являются буквами или цифрами.
Если требуется преобразовать все буквы строки в верхний или нижний регистр, это также можно сделать без написания дополнительных функций, просто используя методы строк в комбинации с константами библиотеки string. Например, чтобы перевести строку в верхний регистр, можно воспользоваться методом str.upper(), а затем проверить, содержит ли она только заглавные буквы с помощью string.ascii_uppercase.
Ещё одной полезной функцией является string.maketrans(), которая позволяет создавать таблицы преобразования символов. Например, для замены всех строчных букв на заглавные в строке можно создать соответствующую таблицу замены:
import string
trans = str.maketrans(string.ascii_lowercase, string.ascii_uppercase)
text = "example text"
print(text.translate(trans)) # EXAMPLE TEXT
Эти и другие возможности библиотеки string значительно ускоряют решение задач, связанных с текстовыми данными, облегчая их обработку и анализ.
Поиск и замена символов с помощью алфавита в Python
В Python для работы с алфавитами и символами часто используют стандартные методы строк и встроенные модули, такие как string. Эти инструменты помогают эффективно находить и заменять символы в тексте, что полезно при обработке данных.
Для поиска символа в строке, использующей алфавит, можно применить метод find(). Он возвращает индекс первого вхождения символа. Если символ не найден, метод возвращает -1. Это удобно для быстрого поиска буквы в строке.
Пример поиска буквы в строке:
text = "Привет, мир!"
index = text.find('м')
Для замены символов используется метод replace(). Он позволяет заменить все вхождения определённого символа или подстроки на новый символ или строку.
Пример замены символа:
text = "Привет, мир!"
new_text = text.replace('м', 'М')
Если требуется более сложная замена (например, с учётом регистров или только на определённых позициях), можно использовать регулярные выражения с модулем re. Это позволяет искать и заменять символы по паттерну, что значительно расширяет возможности обработки текста.
Пример использования регулярных выражений для замены всех гласных букв на символ "*":
import re
text = "Привет, мир!"
new_text = re.sub('[аеёиоуыэюя]', '*', text, flags=re.IGNORECASE)
Для более гибкой работы с алфавитами можно воспользоваться модулем string, который предоставляет строку с символами стандартных латинских букв. Это удобно при выполнении задач, где требуется оперировать с алфавитами или заменить символы на соответствующие им индексы.
Пример использования алфавита для замены символов:
import string
text = "abc"
alphabet = string.ascii_lowercase
new_text = ''.join([alphabet[(alphabet.index(c) + 1) % len(alphabet)] for c in text])
Таким образом, Python предоставляет множество инструментов для поиска и замены символов в строках, от простых методов строк до мощных возможностей регулярных выражений, что позволяет решать различные задачи обработки данных с учётом алфавита.
Сортировка и фильтрация строк с учётом алфавита
Для сортировки и фильтрации строк в Python, используя алфавитный порядок, можно применить стандартные функции языка, такие как sorted() и filter(), а также воспользоваться ключевыми параметрами, которые учитывают алфавитный порядок символов.
Для сортировки строк по алфавиту используется функция sorted(), которая сортирует строки на основе символов, соблюдая их позицию в алфавите. Например:
words = ['яблоко', 'банан', 'апельсин']
sorted_words = sorted(words)
print(sorted_words) # ['апельсин', 'банан', 'яблоко']
Функция sorted() возвращает новый отсортированный список, оставляя исходный неизменным. Важно помнить, что сортировка происходит по лексикографическому порядку, где символы сравниваются в соответствии с их ASCII-кодами. Для учёта регистров можно использовать параметр key=str.lower, чтобы привести все строки к нижнему регистру перед сравнением.
sorted_words = sorted(words, key=str.lower)
print(sorted_words) # ['апельсин', 'банан', 'яблоко']
Для фильтрации строк по алфавитному признаку применяется функция filter(). Например, если требуется оставить только те строки, которые начинаются с буквы 'б', можно использовать следующий код:
words = ['яблоко', 'банан', 'апельсин', 'брокколи']
filtered_words = filter(lambda word: word.startswith('б'), words)
print(list(filtered_words)) # ['банан', 'брокколи']
Функция filter() требует функции, которая возвращает булево значение для каждого элемента. В данном случае lambda word: word.startswith('б') проверяет, начинается ли слово с буквы 'б'.
Сортировка и фильтрация строк на основе алфавита эффективны при работе с текстовыми данными, которые нужно упорядочить или выделить по определённому признаку. Для сложных сценариев, например, при фильтрации по диапазону букв или учёте акцентов, могут быть использованы более сложные методы с кастомными функциями, основанными на обработке Unicode.
Преобразование букв в верхний и нижний регистр с помощью алфавита
В Python преобразование букв в верхний и нижний регистр – задача, которая часто встречается при обработке текстовых данных. Стандартные функции, такие как upper() и lower(), позволяют быстро изменять регистр символов. Однако использование алфавита может быть полезно для более детализированных операций или в случае, когда требуется более глубокая кастомизация.
Алфавит можно представлять как строку из всех букв, что позволяет создавать собственные функции для изменения регистра, управляя, например, только определенными символами. Чтобы преобразовать символ в верхний регистр, можно найти его индекс в алфавите и использовать соответствующую букву в верхнем регистре.
Пример кода для преобразования буквы в верхний регистр с использованием алфавита:
import string
def to_upper_case(char):
alphabet = string.ascii_lowercase
if char in alphabet:
index = alphabet.index(char)
return string.ascii_uppercase[index]
return char
Этот подход позволяет гибко работать с алфавитом, заменяя только те буквы, которые присутствуют в строках. Для преобразования в нижний регистр можно применить аналогичный метод, используя строку string.ascii_uppercase для поиска индекса и возвращения соответствующей буквы в нижнем регистре.
Использование встроенных функций upper() и lower() значительно упрощает процесс, однако знание работы с алфавитом может быть полезным в ситуациях, когда требуется тонкая настройка обработки строк или работа с ограниченным набором символов.
Работа с буквенными диапазонами: от 'a' до 'z'
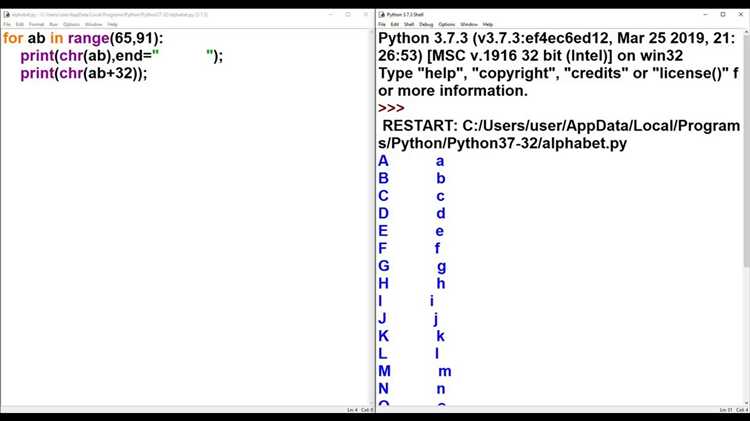
В Python для работы с буквенными диапазонами часто используется функция chr() и ord(), которые позволяют преобразовывать символы в их числовые значения и наоборот. Для работы с диапазонами символов от 'a' до 'z' эти инструменты предоставляют гибкость и простоту.
Для создания диапазона букв от 'a' до 'z' можно воспользоваться встроенной функцией range(), но с учетом того, что символы имеют числовое представление, мы можем эффективно использовать ord() и chr() для создания нужного диапазона.
- Чтобы создать список букв от 'a' до 'z', используйте следующий код:
letters = [chr(i) for i in range(ord('a'), ord('z') + 1)]
Этот код генерирует список символов от 'a' до 'z'.
При необходимости изменить диапазон, например, от 'm' до 's', можно использовать следующее:
letters = [chr(i) for i in range(ord('m'), ord('s') + 1)]
Еще один способ работы с диапазонами – использование генераторов:
letters = (chr(i) for i in range(ord('a'), ord('z') + 1))
Этот метод полезен, если необходимо экономить память, так как генератор не создает весь список сразу.
Если нужно выполнить действия с буквами в диапазоне, такие как фильтрация или сортировка, можно воспользоваться стандартными функциями Python:
filter() – для выборки букв по определенному условию;sorted() – для сортировки символов;map() – для применения функции к каждому символу.
Например, чтобы отфильтровать только те буквы, которые идут после 'm', используйте:
filtered_letters = filter(lambda x: x > 'm', letters)
При необходимости преобразовать буквы в их заглавную форму, можно воспользоваться функцией upper():
uppercase_letters = [letter.upper() for letter in letters]
Важно помнить, что операции с буквенными диапазонами могут быть полезны для создания алгоритмов, которые требуют обработки отдельных символов или их последовательностей. Также эти методы применимы при решении задач на шифрование, анализ текста или создание паролей, где важно учитывать каждую букву в диапазоне.
Алгоритмы шифрования с использованием алфавита в Python

Одним из самых известных методов является шифр Цезаря. Этот алгоритм выполняет сдвиг каждого символа на фиксированное количество позиций в алфавите. Реализация на Python выглядит следующим образом:
def caesar_cipher(text, shift):
result = ""
for char in text:
if char.isalpha():
start = ord('a') if char.islower() else ord('A')
result += chr((ord(char) - start + shift) % 26 + start)
else:
result += char
return result
Функция caesar_cipher принимает два аргумента: текст и величину сдвига. Для каждой буквы вычисляется её новое положение в алфавите с учетом указанного сдвига. Символы, не относящиеся к алфавиту, остаются неизменными.
Для более сложных шифровок, можно использовать шифр Виженера. В отличие от шифра Цезаря, в нем используется ключ, который повторяется по длине исходного текста. Алгоритм позволяет избежать предсказуемости, которая присуща методу с фиксированным сдвигом.
def vigenere_cipher(text, key):
result = ""
key = key.lower()
key_index = 0
for char in text:
if char.isalpha():
shift = ord(key[key_index % len(key)]) - ord('a')
start = ord('a') if char.islower() else ord('A')
result += chr((ord(char) - start + shift) % 26 + start)
key_index += 1
else:
result += char
return result
Здесь ключ передается в виде строки, которая используется для сдвига букв в алфавите. Каждый символ текста шифруется сдвигом, соответствующим символу ключа, что значительно повышает безопасность по сравнению с шифром Цезаря.
Еще одним методом шифрования является использование алфавита в рамках шифра RSA, где вместо букв применяются числа, соответствующие символам. Однако для реализации RSA потребуется сторонняя библиотека, например, PyCryptodome, так как сам алгоритм значительно сложнее и включает операции с большими числами.
Для более безопасного обмена данными в Python стоит рассматривать использование встроенных библиотек, таких как cryptography, которая предоставляет высокоуровневые функции для работы с симметричным и асимметричным шифрованием. Пример с использованием шифрования AES:
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
def aes_encrypt(data, key):
cipher = Cipher(algorithms.AES(key), modes.ECB(), backend=default_backend())
encryptor = cipher.encryptor()
return encryptor.update(data.encode()) + encryptor.finalize()
В этом примере используется стандарт AES для симметричного шифрования, где key должен быть длиной 16, 24 или 32 байта, в зависимости от выбранного уровня безопасности. Такой подход требует дополнительной обработки данных (например, добавления паддинга), что улучшает защиту данных при передаче.
Алгоритмы шифрования с использованием алфавита в Python позволяют легко адаптировать и модифицировать криптографические методы в зависимости от требований безопасности. Применение различных техник, от простых шифров до более сложных библиотечных решений, расширяет возможности работы с конфиденциальной информацией, обеспечивая ее защиту на различных уровнях.
Проверка наличия символов алфавита в строках
Для эффективной обработки строк в Python часто требуется проверка, содержат ли они определённые символы алфавита. Это может быть полезно при анализе текста, фильтрации данных или извлечении информации.
Для таких целей Python предоставляет несколько подходов, которые можно адаптировать в зависимости от задачи.
Использование метода in
Метод in позволяет легко проверять наличие символов в строках. Это базовый и быстрый способ, который идеально подходит для поиска одного или нескольких символов.
text = "Пример текста"
if "е" in text:
print("Символ найден")
Поиск всех букв алфавита в строке
Для поиска всех букв, относящихся к алфавиту, можно использовать цикл и метод in, проверяя каждый символ по отдельности. Также можно работать с множествами для более эффективного поиска.
import string
text = "Пример текста"
alphabet = set(string.ascii_lowercase + string.ascii_uppercase)
found_letters = [char for char in text if char in alphabet]
print(found_letters)
В этом примере создаётся набор символов английского алфавита, и мы ищем все символы, входящие в этот набор. Это полезно, когда нужно узнать, какие именно буквы алфавита присутствуют в строке.
Использование регулярных выражений
Если задача требует проверки наличия букв алфавита с учётом различных критериев, например, нечувствительных к регистру, можно воспользоваться регулярными выражениями.
import re
text = "Пример текста"
if re.search(r'[a-zA-Z]', text):
print("Символы алфавита присутствуют")
В данном примере регулярное выражение [a-zA-Z] ищет любую букву как в нижнем, так и в верхнем регистре. Это позволяет гибко настроить поиск.
Проверка на отсутствие символов алфавита
Если требуется удостовериться в отсутствии символов алфавита, можно использовать логические операторы или методы Python, такие как all или any.
text = "123456"
if not any(char.isalpha() for char in text):
print("Символы алфавита отсутствуют")
Оптимизация поиска
При работе с большими объемами данных важно учитывать производительность. Использование множества для проверки наличия символов является более быстрым решением по сравнению с линейным поиском в строках, особенно если набор символов велик. Множество позволяет выполнять поиск за время O(1), что значительно ускоряет обработку.
Заключение
Проверка наличия символов алфавита в строках является важной частью работы с текстовыми данными в Python. В зависимости от задачи можно выбрать различные методы – от простого использования in до сложных регулярных выражений. Важно всегда учитывать производительность и требования задачи для оптимального выбора подхода.
Генерация случайных строк из букв алфавита в Python

Для генерации случайных строк из букв алфавита в Python можно использовать встроенные модули, такие как random и string. Модуль string предоставляет строки с символами, включая заглавные и строчные буквы, что упрощает работу с алфавитом.
Первый шаг – импортировать нужные модули:
import random
import string
Для создания строки фиксированной длины можно использовать функцию random.choice(), которая выбирает случайный элемент из переданного списка символов. Например, чтобы создать строку из 10 случайных букв:
length = 10
random_string = ''.join(random.choice(string.ascii_letters) for _ in range(length))
print(random_string)
В этом примере string.ascii_letters представляет собой строку, содержащую все латинские буквы (как строчные, так и заглавные). С помощью генератора создается строка длиной length, состоящая из случайных символов.
Можно ограничиться только строчными или только заглавными буквами, используя string.ascii_lowercase или string.ascii_uppercase соответственно:
random_lowercase = ''.join(random.choice(string.ascii_lowercase) for _ in range(length))
random_uppercase = ''.join(random.choice(string.ascii_uppercase) for _ in range(length))
Если необходимо включить в строку не только буквы, но и цифры или другие символы, можно использовать string.ascii_letters + string.digits:
random_alphanumeric = ''.join(random.choice(string.ascii_letters + string.digits) for _ in range(length))
Если нужно создать строку с буквами, исключая конкретные символы (например, без гласных), можно модифицировать выбор символов:
consonants = ''.join(random.choice('bcdfghjklmnpqrtvwxz') for _ in range(length))
Для улучшенной случайности можно использовать secrets, который специально разработан для криптографически безопасной генерации случайных данных. Используя secrets.choice(), можно генерировать строки с более высокой степенью случайности:
import secrets
secure_string = ''.join(secrets.choice(string.ascii_letters) for _ in range(length))
print(secure_string)
Это может быть полезно для создания паролей или других чувствительных данных, где требуется высокая степень случайности.
Вопрос-ответ:
Что такое алфавит в Python и как его можно использовать для обработки данных?
Алфавит в Python обычно ассоциируется с набором символов, который можно использовать для различных задач обработки данных, например, для работы с текстовыми данными. В Python есть встроенные средства для работы с символами и строками, такие как модуль `string`, который предоставляет набор символов для алфавита (буквы латинского алфавита в верхнем и нижнем регистрах). Эти символы можно использовать для различных операций, таких как поиск, замена, фильтрация или сортировка строк, а также для работы с кодировками.
Как использовать алфавит для проверки, состоит ли строка только из букв?
Чтобы проверить, состоит ли строка только из букв, можно использовать метод `isalpha()`. Этот метод проверяет, содержит ли строка только буквы из алфавита (включая как заглавные, так и строчные). Пример использования: `str.isalpha()` вернет `True`, если все символы в строке являются буквами, и `False`, если хотя бы один символ не является буквой. Пример кода: `text = "Hello"; print(text.isalpha())` — результат будет `True`, так как все символы в строке являются буквами.
Как можно использовать алфавит в Python для обработки строк?
Алфавит в Python можно использовать для работы со строками, например, для фильтрации символов, проверки принадлежности символа к определенному набору или кодирования данных. Алфавит, как правило, представлен с помощью строк, списков или других коллекций, и позволяет эффективно взаимодействовать с текстовыми данными. В Python есть стандартные методы, которые позволяют определить, является ли символ буквой, цифрой или другим типом знака. Это важно при обработке текстов для анализа, очистки данных или создания собственных функций для работы с текстами. К примеру, метод str.isalpha() позволяет проверить, является ли символ буквой, а метод str.lower() — привести символы к нижнему регистру, что также связано с алфавитом.