Процессоры с графическими вычислительными единицами (GPU) давно зарекомендовали себя как мощный инструмент для ускорения вычислений в различных областях. В сочетании с библиотеками, поддерживающими параллельные вычисления, такие как CUDA (Compute Unified Device Architecture) от NVIDIA, Python позволяет значительно повысить производительность алгоритмов, особенно в задачах обработки данных и машинного обучения.
CUDA позволяет эффективно использовать вычислительные ресурсы GPU, ускоряя выполнение задач, которые могут быть распараллелены. Это особенно важно в таких областях, как обработка изображений, численные симуляции и обучение нейронных сетей. В Python доступ к функционалу CUDA реализуется через несколько популярных библиотек, таких как CuPy и PyCUDA, которые интегрируются с существующим кодом и значительно ускоряют вычисления.
Для работы с CUDA в Python необходимо учитывать несколько важных аспектов. В первую очередь, необходимо правильно установить драйверы и инструменты разработки NVIDIA, а также убедиться, что используемая версия Python совместима с выбранной библиотекой. Один из ключевых моментов – это правильная настройка памяти GPU, что позволяет избежать ошибок переполнения и потерь производительности при работе с большими массивами данных.
Использование CUDA в Python открывает возможности для разработки высокопроизводительных приложений, но требует тщательной настройки и тестирования для достижения максимальной эффективности.
Настройка среды для работы с CUDA в Python

Для работы с CUDA в Python необходимы несколько компонентов: драйвер NVIDIA, CUDA Toolkit, библиотеки Python и инструменты для управления зависимостями. Начать нужно с установки драйвера видеокарты и CUDA Toolkit.
1. Установите драйвер NVIDIA, соответствующий вашей видеокарте. Для этого перейдите на официальный сайт NVIDIA и загрузите последнюю версию драйвера для вашей операционной системы. Драйвер должен быть совместим с версией CUDA, которую вы планируете использовать. Проверить установленную версию можно с помощью команды nvidia-smi.
2. Загрузите и установите CUDA Toolkit. На сайте NVIDIA доступна последняя версия CUDA, которая включает в себя компилятор, библиотеки и инструменты для разработки. Убедитесь, что выбранная версия совместима с вашей видеокартой и операционной системой. В процессе установки важно следовать инструкциям по настройке переменных среды, чтобы CUDA могла быть правильно интегрирована в систему.
3. Установите Python-библиотеки, работающие с CUDA. Среди самых популярных: pycuda и cupy. Для установки используйте команду pip install pycuda или pip install cupy. Эти библиотеки обеспечивают интерфейс между Python и CUDA, позволяя использовать вычисления на GPU в коде Python. Перед установкой убедитесь, что у вас установлена совместимая версия Python и необходимый инструмент для управления зависимостями, например, pip или conda.
4. Для тестирования работоспособности настроенной среды можно использовать примеры из документации к установленным библиотекам. В случае с cupy достаточно выполнить команду для создания массива на GPU и проверки его работы: import cupy as cp, a = cp.array([1, 2, 3]). Для pycuda можно запустить пример с использованием потока CUDA и базовых операций на GPU.
5. Важно также учитывать совместимость версий библиотек, CUDA и драйверов. Каждая версия CUDA требует определённой версии драйвера, а Python-библиотеки могут иметь свои ограничения по поддерживаемым версиям CUDA. Рекомендуется использовать документацию для точной настройки.
После настройки среды можно перейти к оптимизации вычислений, создавая и выполняя задачи, используя мощность GPU через Python.
Интеграция библиотеки CuPy для работы с массивами данных на GPU
CuPy представляет собой высокопроизводительную библиотеку для работы с массивами данных на GPU, полностью совместимую с NumPy. Это решение значительно ускоряет операции с массивами за счёт использования вычислительных мощностей графических процессоров (GPU), поддерживающих CUDA.
Для начала работы с CuPy необходимо установить её с помощью менеджера пакетов pip:
pip install cupyCuPy предлагает интерфейс, схожий с NumPy, что делает переход с одной библиотеки на другую простым. Основное отличие – использование GPU для хранения и обработки данных, что обеспечивает резкое увеличение производительности при работе с большими массивами. В CuPy операции над массивами выполняются аналогично NumPy, но с использованием ресурсов CUDA.
Основной объект в CuPy – это массивы, хранящиеся в памяти GPU. Создать такой массив можно с помощью функции cupy.array, которая аналогична numpy.array. Например:
import cupy as cp
array_gpu = cp.array([1, 2, 3, 4, 5])Все стандартные операции с массивами, такие как сложение, умножение, транспонирование, могут быть выполнены с использованием CuPy. Например, элемент-wise операция сложения:
array_gpu_2 = cp.array([5, 4, 3, 2, 1])
result = array_gpu + array_gpu_2 # Операция сложения на GPUCuPy позволяет эффективно перемещать данные между CPU и GPU с помощью функций cp.asarray и cp.asnumpy. Для получения массива NumPy с данных GPU используется функция cp.asnumpy, а для отправки данных обратно на GPU – cp.asarray. Это позволяет seamlessly интегрировать CuPy в существующие проекты, использующие NumPy:
import numpy as np
array_cpu = np.array([1, 2, 3, 4, 5])
array_gpu = cp.asarray(array_cpu)
result_cpu = cp.asnumpy(result) # Перевод результата в формат NumPyДля работы с многомерными массивами в CuPy также поддерживаются такие операции, как индексирование, срезы, а также различные математические функции. Например, создание двумерного массива и его умножение на скаляр:
matrix_gpu = cp.array([[1, 2], [3, 4]])
result = matrix_gpu * 2 # Умножение на скалярCuPy также поддерживает более сложные операции, такие как свёртка, транспонирование, и преобразования с использованием FFT, LAPACK и других математических библиотек, доступных через CUDA. Это делает CuPy отличным инструментом для научных вычислений и машинного обучения, где требуется высокая производительность и обработка больших объёмов данных.
Для эффективной работы с большими данными на GPU важно правильно управлять памятью. CuPy предоставляет возможность очищать память с помощью cp.ElementwiseKernel, что помогает избежать утечек памяти. Для очистки памяти можно использовать метод cp.get_default_memory_pool().free_all_blocks(), который освобождает неиспользуемую память на GPU.
Оптимизация численных вычислений с использованием Numba и CUDA

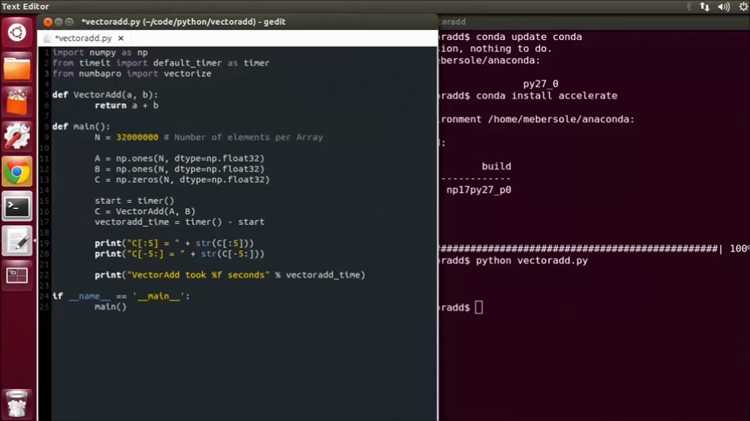
Использование Numba в связке с CUDA позволяет значительно ускорить численные вычисления на GPU. Эта комбинация инструментов дает возможность писать высокоэффективный код для обработки больших объемов данных и решения сложных математических задач. Важно понимать, как правильно оптимизировать алгоритмы, чтобы извлечь максимум из возможностей GPU.
Numba – это Python-библиотека для компиляции кода на лету, которая поддерживает CUDA. Она позволяет легко использовать GPU для выполнения параллельных вычислений без необходимости писать код на C или Fortran. Чтобы эффективно использовать CUDA с Numba, нужно учитывать несколько факторов.
1. Параллельная обработка данных
Основной принцип ускорения вычислений с CUDA – это параллельная обработка данных. В отличие от CPU, где операции выполняются поочередно, GPU может одновременно обрабатывать тысячи потоков. Для этого в коде должны быть использованы параллельные алгоритмы, что достигается через использование декоратора @cuda.jit.
Для эффективной работы с CUDA через Numba важно:
- Определить правильный размер блоков и сеток: количество потоков в блоке и количество блоков в сетке должно быть адаптировано к характеристикам GPU.
- Использовать глобальную память GPU эффективно, избегая избыточных обращений к памяти, так как это может привести к замедлению.
- Массивы данных должны быть размещены в памяти GPU для ускоренного доступа, это делается через использование
numba.cuda.to_deviceдля передачи данных с CPU на GPU.
2. Использование потоков и блоков
Важно учитывать, как распараллеливаются вычисления на GPU. Каждый поток выполняет свою часть работы, и Numba позволяет управлять количеством потоков и блоков с помощью параметров grid и block.
blockDim: задает количество потоков в одном блоке. Рекомендуется использовать оптимальные размеры, такие как 32 или 64, в зависимости от структуры задачи.gridDim: определяет количество блоков в сетке. Число блоков должно быть достаточно большим, чтобы эффективно использовать все доступные ресурсы GPU.
Оптимизация этих параметров зависит от конкретной задачи и архитектуры GPU. Например, для операций с матрицами и векторными вычислениями часто выбирают блоки размером 16×16 или 32×32 для матриц размером 512×512 и более.
3. Использование совместимой памяти
GPU имеет несколько типов памяти, и правильный выбор между ними может существенно повлиять на производительность:
- Глобальная память: основной тип памяти, доступный всем потокам, но имеет высокую латентность. Использование совместимой памяти может уменьшить количество обращений.
- Специальная память (shared memory): быстрая память, доступная только для потоков одного блока. Она используется для обмена данными между потоками, что снижает нагрузку на глобальную память и повышает скорость выполнения.
- Константная и текстурная память: эти типы памяти полезны при работе с неизменными данными и могут использоваться для оптимизации доступа к данным в задачах с повторяющимися вычислениями.
Чтобы максимизировать производительность, важно минимизировать время доступа к медленной глобальной памяти и по возможности использовать shared memory для блоков данных, которые часто обрабатываются совместно.
4. Профилирование и отладка
Для достижения максимальной производительности необходимо профилировать и оптимизировать код. Инструменты, такие как nvprof и Nsight Compute, предоставляют информацию о том, как эффективно используется GPU. Это позволяет выявить узкие места и провести оптимизацию, например, уменьшив количество обращений к глобальной памяти или улучшив балансировку нагрузки между потоками.
Кроме того, использование numba.cuda.profile и других встроенных инструментов помогает отслеживать время выполнения и ресурсы, которые использует каждый поток, блок и сетка. Эти данные позволяют выявить, где происходит затраты времени и как можно улучшить алгоритм.
5. Пример реализации

Пример простой реализации с использованием Numba и CUDA для вычисления суммы элементов в массиве:
from numba import cuda
import numpy as np
@cuda.jit
def sum_array(arr, out):
i = cuda.grid(1)
if i < arr.size:
cuda.atomic.add(out, 0, arr[i])
# Пример данных
arr = np.random.random(1000000).astype(np.float32)
out = np.zeros(1, dtype=np.float32)
# Перемещение данных на GPU
d_arr = cuda.to_device(arr)
d_out = cuda.to_device(out)
# Запуск на GPU
threads_per_block = 256
blocks_per_grid = (arr.size + (threads_per_block - 1)) // threads_per_block
sum_array[blocks_per_grid, threads_per_block](d_arr, d_out)
# Получение результата
d_out.copy_to_host(out)
print(out[0])
Этот пример демонстрирует, как с помощью Numba и CUDA можно эффективно использовать GPU для вычисления суммы элементов в большом массиве. Важно правильно подобрать количество потоков и блоков, чтобы обеспечить наилучшую производительность.
Параллельные вычисления на GPU с использованием PyCUDA
Для работы с PyCUDA важно установить драйвера NVIDIA, CUDA Toolkit и саму библиотеку PyCUDA. После установки можно использовать PyCUDA для создания и выполнения параллельных вычислений, что позволяет значительно ускорить процессы по сравнению с использованием только CPU.
Первым шагом является создание устройства GPU, которое будет использоваться для вычислений. Для этого используется класс pycuda.driver.Device. Далее можно выделить память на GPU с помощью метода pycuda.driver.mem_alloc. Например:
import pycuda.driver as cuda
import numpy as np
cuda.init()
device = cuda.Device(0) # Выбор первого доступного устройства GPU
context = device.make_context()
# Создание массива NumPy
a = np.random.rand(10000).astype(np.float32)
# Выделение памяти на GPU
a_gpu = cuda.mem_alloc(a.nbytes)
cuda.memcpy_htod(a_gpu, a) # Копирование данных с CPU на GPU
Следующим шагом является создание CUDA-ядра. PyCUDA использует C-like синтаксис для написания кода ядер. Код ядра должен быть передан в функцию pycuda.compiler.SourceModule, которая компилирует его для выполнения на GPU. Пример простого ядра, которое умножает каждый элемент массива на 2:
kernel_code = """
__global__ void multiply_by_two(float *a)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
a[idx] *= 2;
}
"""
mod = cuda.SourceModule(kernel_code)
multiply_by_two = mod.get_function("multiply_by_two")
После компиляции ядра его можно вызвать на GPU. Для этого важно правильно настроить блоки и сетки потоков. В CUDA каждый поток выполняет свою часть работы. Размер блока и сетки задается через параметры в методе get_function. В примере ниже выполняется запуск ядра, умножающего элементы массива на два:
# Параметры блока и сетки
block_size = 256
grid_size = int(np.ceil(len(a) / block_size))
# Запуск ядра на GPU
multiply_by_two(a_gpu, block=(block_size, 1, 1), grid=(grid_size, 1))
После выполнения вычислений необходимо перенести результат обратно на CPU. Для этого используется функция cuda.memcpy_dtoh, которая копирует данные с GPU на CPU:
# Копирование результата на CPU
cuda.memcpy_dtoh(a, a_gpu)
PyCUDA также предоставляет удобные функции для работы с массивами и вычислениями на GPU. Например, можно использовать pycuda.gpuarray для создания массивов, которые могут хранить данные на GPU и автоматически управлять памятью. Это облегчает работу с большими массивами данных и устраняет необходимость вручную управлять памятью.
Для эффективной работы с PyCUDA необходимо учитывать несколько факторов. Во-первых, важно правильно выбрать размер блоков и сетки для ядра. Меньшие блоки могут приводить к низкой производительности из-за большего накладного времени на управление потоками. Во-вторых, стоит избегать излишнего копирования данных между CPU и GPU, так как это может значительно замедлить выполнение программы. Вместо этого лучше использовать подходы, при которых данные обрабатываются на GPU без лишних пересылок.
Использование PyCUDA позволяет значительно ускорить вычисления и сделать программу более масштабируемой за счет параллельных вычислений на GPU. Важно также помнить о балансе между параллельностью и загрузкой памяти, чтобы избежать излишней конкуренции за ресурсы GPU.
Использование TensorFlow и PyTorch для работы с CUDA в задачах машинного обучения

TensorFlow использует CUDA для выполнения операций на графических процессорах (GPU), что ускоряет вычисления в таких задачах, как обучение нейронных сетей и обработка данных. Для работы с CUDA в TensorFlow необходимо установить соответствующие версии драйверов NVIDIA, CUDA Toolkit и cuDNN. После этого TensorFlow автоматически будет использовать доступный GPU для ускорения вычислений, если это возможно.
Для явного указания TensorFlow на использование GPU можно использовать команду:
import tensorflow as tf device_name = "/GPU:0" # или /GPU:1 для второго GPU with tf.device(device_name): # Ваш код для обучения модели
PyTorch также имеет встроенную поддержку CUDA, что позволяет эффективно использовать GPU для выполнения операций. В отличие от TensorFlow, в PyTorch пользователь может вручную управлять перемещением данных и моделей между CPU и GPU. Для этого используется метод .to(), который позволяет указать, на каком устройстве будет выполняться конкретная операция.
Пример использования CUDA в PyTorch:
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = YourModel().to(device)
input_data = input_data.to(device)
Обучение модели
output = model(input_data)
Использование CUDA с PyTorch требует наличия совместимого оборудования и правильно настроенных драйверов NVIDIA. Преимущество PyTorch в том, что его динамическая природа позволяет легче отлаживать код и тестировать изменения, что особенно полезно при исследовательской работе с моделями.
Оба фреймворка обеспечивают высокую производительность на GPU, но выбор между ними зависит от конкретных требований проекта. TensorFlow может быть предпочтителен для масштабных решений с глубоким интегрированным экосистемой, в то время как PyTorch часто используется для исследований и прототипирования благодаря своей гибкости и более простому синтаксису.
Вопрос-ответ:
Что такое CUDA и как она может ускорить вычисления в Python?
CUDA (Compute Unified Device Architecture) — это платформа и модель программирования от NVIDIA, которая позволяет использовать графические процессоры (GPU) для выполнения вычислений. В Python можно использовать библиотеки, такие как PyCUDA или Numba, для обращения к вычислительным ресурсам GPU. Использование CUDA позволяет значительно ускорить выполнение алгоритмов, особенно тех, которые требуют больших вычислительных мощностей, например, в области обработки данных, машинного обучения и научных вычислений.
Как я могу начать использовать CUDA в Python?
Для начала работы с CUDA в Python нужно установить необходимые библиотеки, такие как PyCUDA или Numba. Затем необходимо настроить соответствующую среду разработки, убедившись, что на компьютере установлен драйвер GPU от NVIDIA и CUDA toolkit. После этого можно начать писать код, который будет использовать возможности GPU для выполнения вычислений, например, перенести ресурсоёмкие операции, такие как матричные умножения, на GPU для ускорения их выполнения.
Какие библиотеки можно использовать для работы с CUDA в Python?
Для работы с CUDA в Python существует несколько популярных библиотек. Одной из них является PyCUDA, которая предоставляет интерфейс для работы с CUDA API. Еще одна библиотека — Numba, позволяет компилировать Python-код в машинный код, использующий GPU. Также есть CuPy, которая поддерживает работу с многими функциями, схожими с NumPy, но выполняемыми на GPU. Все эти библиотеки позволяют максимально эффективно использовать ресурсы GPU для ускорения вычислений.
Какие задачи можно ускорить с помощью CUDA в Python?
С помощью CUDA можно ускорить множество задач, связанных с интенсивными вычислениями. Это могут быть операции с большими массивами данных, такие как линейная алгебра, многомерная оптимизация, работа с изображениями, обработка видео, анализ данных, машинное обучение и глубокое обучение. Например, обучение нейронных сетей на GPU может в десятки раз ускорить процесс по сравнению с использованием только центрального процессора (CPU).
Какие проблемы могут возникнуть при использовании CUDA в Python?
При использовании CUDA в Python могут возникать различные проблемы, связанные с совместимостью оборудования и программного обеспечения. Например, не все GPU поддерживают CUDA, и необходимо иметь соответствующую версию драйвера и CUDA toolkit. Также код, написанный с использованием CUDA, может быть сложным в отладке, так как ошибки могут возникать как на уровне GPU, так и в работе с библиотеками. Еще одной проблемой является необходимость грамотного распределения вычислительных задач между CPU и GPU, чтобы избежать излишней загрузки процессора или недоиспользования GPU.
Что такое CUDA и как она используется в Python для ускорения вычислений?
CUDA (Compute Unified Device Architecture) – это технология от компании NVIDIA, которая позволяет использовать графические процессоры (GPU) для выполнения параллельных вычислений. В Python для работы с CUDA можно использовать различные библиотеки, такие как CuPy, Numba или PyCUDA. Эти библиотеки позволяют ускорить выполнение задач, которые требуют большого объема вычислений, например, в области машинного обучения, обработки изображений и научных вычислений, путем использования вычислительных мощностей графического процессора.