В Python работа с вложенными списками – распространенная задача при обработке данных. Вложенные структуры могут быть неудобными для анализа, если необходимо выполнить операции с их элементами, не затрагивая вложенность. Преобразование таких списков в одномерный массив упрощает работу, позволяя эффективно обрабатывать данные.
Существует несколько методов для решения этой задачи. Один из наиболее популярных – использование рекурсии, однако также возможны другие способы, такие как использование библиотеки itertools или метода extend() в сочетании с циклами. Важно выбрать подход, соответствующий специфике задачи, учитывая требования к производительности и читаемости кода.
В этой статье рассмотрим несколько вариантов преобразования вложенных списков в одномерные, с пошаговым объяснением каждого подхода и рекомендациями по их применению. Мы проанализируем как стандартные инструменты Python, так и сторонние библиотеки, чтобы обеспечить максимальную гибкость при решении поставленной задачи.
Использование метода extend() для объединения списков
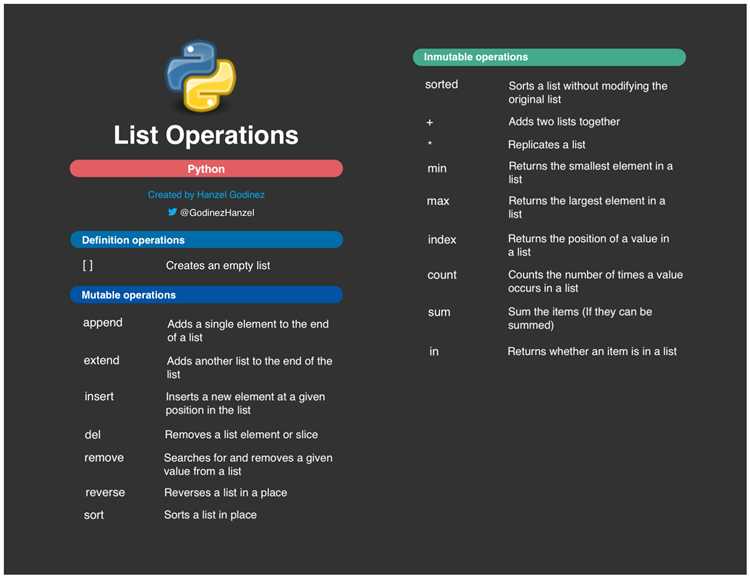
Метод extend() в Python предоставляет простой способ объединения нескольких списков в один. Он добавляет все элементы одного списка в конец другого, не создавая нового списка. В отличие от метода append(), который добавляет один элемент в конец списка, extend() работает с коллекциями, такими как списки или другие итерируемые объекты.
Пример использования:
list1 = [1, 2, 3] list2 = [4, 5, 6] list1.extend(list2)
Метод extend() изменяет исходный список и не возвращает новый, что делает его более эффективным по памяти при работе с большими объемами данных.
Использование extend() предпочтительно в ситуациях, когда необходимо объединить два или более списков в один, особенно если важна экономия памяти и производительность. В случае с большими списками, метод не создает дополнительных временных объектов, в отличие от операции конкатенации с использованием +, что важно при работе с большими объемами данных.
Если вам нужно объединить несколько списков, вы можете передать их как аргументы в метод extend() в цикле или через вложенные вызовы:
list1 = [1, 2] list2 = [3, 4] list3 = [5, 6] list1.extend(list2) list1.extend(list3)
Важный момент: extend() работает только с итерируемыми объектами. Попытка передать неитерируемый объект вызовет ошибку. Например, передача целого числа приведет к ошибке:
list1 = [1, 2] list1.extend(3) # Ошибка: 'int' object is not iterable
Для преобразования вложенного списка в один уровень с использованием extend() можно применить его в цикле, проходя по каждому вложенному списку:
nested_list = [[1, 2], [3, 4], [5, 6]] flat_list = [] for sublist in nested_list: flat_list.extend(sublist)
Использование метода extend() является одним из самых эффективных способов объединения и «распаковки» вложенных списков в Python. Этот метод полезен, когда требуется изменить существующий список, а не создавать новый, что экономит ресурсы при работе с большими объемами данных.
Применение рекурсии для работы с вложенными структурами
Рекурсия – мощный инструмент для обработки сложных, вложенных структур данных, таких как списки, содержащие другие списки. В Python, когда перед нами стоит задача работы с вложенными структурами, рекурсия может значительно упростить решение проблемы. Рассмотрим, как можно эффективно использовать рекурсию для работы с такими структурами.
Основной принцип рекурсии заключается в том, что функция вызывает саму себя для обработки каждого уровня вложенности. Это позволяет обходить все элементы, не беспокоясь о глубине вложенности. Рассмотрим пример, когда нужно преобразовать вложенный список в один плоский:
def flatten(nested_list): flat_list = [] for element in nested_list: if isinstance(element, list): flat_list.extend(flatten(element)) # рекурсивный вызов else: flat_list.append(element) return flat_list
Здесь функция flatten проверяет каждый элемент. Если элемент – это список, функция снова вызывает себя для обработки этого списка. Если элемент не является списком, он добавляется в конечный список. Это позволяет эффективно обработать любые уровни вложенности.
Рекурсия также полезна для обработки более сложных структур, таких как деревья или графы. При обходе таких структур важно, чтобы рекурсивная функция делала шаг к следующему уровню, пока не достигнет конечного элемента. Важно помнить, что при глубоком вложении или большом количестве данных рекурсия может привести к переполнению стека, если глубина вызова слишком велика.
Кроме того, рекурсия может быть использована для поиска элементов в сложных структурах. Например, для поиска всех чисел в вложенных списках можно создать рекурсивную функцию, которая проверяет элементы на каждом уровне и добавляет числа в результат.
Однако стоит учитывать, что для работы с большими объемами данных может быть полезно использовать итеративные методы или оптимизировать рекурсию с помощью хвостовой рекурсии, чтобы избежать переполнения стека.
Таким образом, рекурсия является важным инструментом при работе с вложенными структурами в Python, позволяя решать задачи обхода и трансформации данных без необходимости вручную управлять состоянием каждой вложенности.
Как распаковать вложенные списки с помощью оператора *
Оператор распаковки * в Python позволяет легко извлекать элементы из вложенных структур данных, таких как списки, и объединять их в один уровень. Это особенно полезно при работе с многослойными списками, когда необходимо извлечь элементы из внутренних списков, не прибегая к явному циклу или рекурсии.
Для распаковки вложенных списков можно использовать * непосредственно в момент передачи аргументов функции или при объединении списков. Например, если у вас есть список, содержащий другие списки, вы можете использовать * для извлечения элементов этих списков в одном выражении.
Пример использования * для распаковки:
nested_list = [[1, 2], [3, 4], [5, 6]] flat_list = [*nested_list[0], *nested_list[1], *nested_list[2]]
В этом примере каждый вложенный список распаковывается и добавляется в общий список flat_list. Оператор * используется для извлечения элементов из внутренних списков и добавления их в один плоский список.
Также оператор * можно применять с функциями, которые принимают несколько аргументов. Например, передача распакованных элементов как аргументов функции позволяет сделать код более компактным и читаемым:
def process_elements(*args): return sum(args) nested_list = [[1, 2], [3, 4], [5, 6]] result = process_elements(*nested_list[0], *nested_list[1], *nested_list[2])
В случае, если список имеет произвольное количество вложенных уровней, можно использовать рекурсию совместно с оператором * для распаковки всех элементов. Важно учитывать, что такой подход может потребовать дополнительных проверок, чтобы избежать ошибок при распаковке неитерабельных объектов.
Для более элегантного решения можно воспользоваться функцией itertools.chain, которая позволяет объединить несколько списков или итераторов в один, не требуя явной распаковки:
import itertools nested_list = [[1, 2], [3, 4], [5, 6]] flat_list = list(itertools.chain(*nested_list))
Использование * при распаковке вложенных списков значительно упрощает код и повышает его гибкость, но важно учитывать контекст и правильно выбирать методы в зависимости от структуры данных.
Использование библиотеки itertools для сглаживания списков
Для преобразования вложенных списков в один можно использовать функцию chain из библиотеки itertools, которая позволяет объединять несколько итерируемых объектов в один без необходимости использования вложенных циклов.
Функция chain принимает произвольное количество итерируемых объектов и возвращает их элементы в одном потоке. Пример использования:
import itertools
nested_list = [[1, 2, 3], [4, 5], [6]]
flattened = list(itertools.chain(*nested_list))
print(flattened)Этот код развернет вложенный список в плоский, объединяя все элементы воедино. Важно отметить, что для правильной работы chain необходимо использовать оператор распаковки *, который передает каждый вложенный список как отдельный аргумент.
Кроме того, для сложных случаев, когда список может быть многоуровневым или комбинированным, можно использовать рекурсивный подход с chain, но он требует дополнительной обработки каждого вложенного списка. В таких случаях полезно будет комбинировать chain с функцией isinstance для проверки, является ли элемент списком или нет.
Использование itertools.chain значительно упрощает процесс сглаживания списков и позволяет избежать избыточных циклов и сложных конструкций. Это решение будет особенно полезно при работе с большими объемами данных, так как chain работает с итераторами и не требует предварительного создания промежуточных списков.
Использование list comprehension для преобразования вложенных списков

List comprehension в Python – мощный инструмент для работы с коллекциями данных, который позволяет эффективно преобразовывать вложенные списки в один плоский список. Это позволяет значительно упростить и ускорить код, исключая необходимость использования циклов и дополнительных промежуточных переменных.
Простой пример преобразования вложенного списка с использованием list comprehension:
nested_list = [[1, 2], [3, 4], [5, 6]]
flat_list = [item for sublist in nested_list for item in sublist]
В этом примере вложенные списки изначально содержат пары чисел. List comprehension позволяет пройтись по каждому подсписку и «развернуть» его элементы в один итоговый список.
Суть операции заключается в том, что после первого выражения for sublist in nested_list выполняется вложенный цикл for item in sublist, который перебирает каждый элемент вложенного списка. Результатом является один список, содержащий все элементы исходных подсписков.
Кроме того, можно использовать условие для фильтрации элементов, например, если нужно собрать только четные числа из вложенного списка:
nested_list = [[1, 2], [3, 4], [5, 6]]
flat_list = [item for sublist in nested_list for item in sublist if item % 2 == 0]
Этот подход позволяет легко комбинировать фильтрацию и преобразование данных в одном выражении. Однако важно помнить, что использование сложных выражений с несколькими уровнями вложенности может затруднить восприятие кода. Поэтому рекомендуется разбивать такие выражения на несколько шагов, если это необходимо для ясности.
Если в списке могут встречаться другие вложенные структуры (например, списки переменной глубины), можно использовать рекурсию для обработки вложенности любого уровня. Однако такой подход требует аккуратности и может быть менее эффективным, чем итерации по заранее известной структуре данных.
В результате, list comprehension – это не только способ преобразования вложенных списков, но и мощное средство для создания краткого, читаемого и эффективного кода в Python.
Метод reduce() для итеративного объединения элементов
Метод reduce() из модуля functools позволяет итеративно объединять элементы последовательности, что делает его полезным для преобразования вложенных списков в плоские. Он применяет заданную функцию к элементам коллекции, сводя их к одному результату. Это особенно эффективно при работе с вложенными структурами данных, где требуется последовательное слияние элементов.
Для преобразования вложенного списка с использованием reduce(), первым шагом является его распаковка с помощью рекурсии или другой техники, чтобы каждый элемент стал доступен для обработки. Например, слияние списков можно реализовать с помощью reduce(), передав в качестве функции конкатенацию.
Пример кода:
from functools import reduce
def flatten(lst):
return reduce(lambda x, y: x + y if isinstance(y, list) else x + [y], lst, [])Здесь lambda x, y: x + y отвечает за объединение списков, а условие isinstance(y, list) проверяет, является ли элемент списком. Начальное значение [] устанавливает пустой список, в который будут добавляться элементы.
Важно отметить, что reduce() требует внимательного подхода при выборе функции для слияния элементов. Некорректная функция может привести к ошибкам, особенно при работе с глубоко вложенными структурами. Если вложенность значительна, можно использовать рекурсию внутри функции для правильной обработки каждого уровня вложенности.
Использование reduce() позволяет минимизировать количество промежуточных списков, что может быть полезно с точки зрения производительности. Однако, если задача предполагает сложные операции над элементами, важно протестировать производительность, чтобы убедиться в эффективности выбранного подхода.
Применение библиотеки numpy для работы с многомерными массивами

Библиотека numpy предоставляет мощные инструменты для работы с многомерными массивами, которые позволяют эффективно манипулировать данными, проводить математические операции и оптимизировать вычисления. В отличие от стандартных списков Python, массивы numpy (или ndarray) имеют несколько ключевых преимуществ, включая высокую производительность и удобные методы для манипуляции размерностями.
Многомерные массивы в numpy можно создать, передав вложенные списки в функцию np.array(). Это позволяет работать с матрицами, тензорами и другими структурами данных.
- Создание многомерных массивов: Для создания массива с несколькими измерениями, достаточно использовать вложенные списки. Например, для создания двумерного массива можно использовать следующий код:
import numpy as np array_2d = np.array([[1, 2, 3], [4, 5, 6]])Это создаст матрицу размером 2×3.
- Изменение размерности: Для изменения формы массива используется метод
reshape(). Например, для преобразования двумерного массива в одномерный:array_1d = array_2d.reshape(-1)Здесь
-1позволяет автоматически вычислить нужную размерность в зависимости от исходных данных. - Индексация и срезы: В
numpyможно использовать сложные операции индексации. Для доступа к элементам массива используется сочетание индексов, а также срезов. Например, для выбора строки из матрицы:row = array_2d[1]Это извлечет вторую строку массива.
- Математические операции: Библиотека предоставляет большое количество встроенных математических функций, которые можно применять непосредственно к массивам. Например:
result = np.add(array_2d, 10)Это добавит число 10 ко всем элементам массива. Операции производятся быстро и эффективно благодаря векторизации.
- Многомерные вычисления:
numpyподдерживает выполнение операций с массивами произвольной размерности, включая элемент-wise операции и матричные умножения. Для произведения двух матриц используется функцияnp.dot():matrix_product = np.dot(array_2d, array_2d.T)Это умножит матрицу на её транспонированную версию.
- Трансформация массивов: Многомерные массивы можно трансформировать с помощью функций
np.transpose()илиnp.swapaxes(). Например, для транспонирования матрицы:transposed = np.transpose(array_2d)Это изменит строки на столбцы и наоборот.
- Создание массивов с заданной размерностью: Для создания массивов с определенной размерностью, заполненных нулями, единицами или случайными числами,
numpyпредоставляет функцииnp.zeros(),np.ones()иnp.random.rand(). Пример:zeros_array = np.zeros((3, 3))Это создаст матрицу размером 3×3, заполненную нулями.
Использование numpy для работы с многомерными массивами значительно повышает производительность, особенно при обработке больших объемов данных, благодаря оптимизации операций на уровне библиотеки. Это особенно важно при решении научных задач, обработки изображений, машинного обучения и анализа данных.
Использование библиотеки pandas для преобразования вложенных списков в DataFrame
Для преобразования вложенного списка в DataFrame используется функция pd.DataFrame(). Рассмотрим пример:
import pandas as pd
nested_list = [[1, 'A', 10], [2, 'B', 20], [3, 'C', 30]]
df = pd.DataFrame(nested_list, columns=['ID', 'Name', 'Value'])
print(df)В данном примере nested_list содержит три подсписка, каждый из которых представляет собой одну строку данных. Аргумент columns используется для указания имен столбцов в создаваемом DataFrame. Этот подход позволяет легко преобразовывать структуру данных в таблицу, где каждый подсписок будет строкой, а элементы подсписков – значениями в соответствующих столбцах.
Если вложенные списки имеют разные длины, pandas дополнит недостающие значения NaN, что является стандартным поведением для DataFrame:
nested_list = [[1, 'A'], [2, 'B', 20], [3, 'C', 30]]
df = pd.DataFrame(nested_list, columns=['ID', 'Name', 'Value'])
print(df)Для более сложных структур данных можно использовать дополнительные параметры, такие как index для задания индексов строк или dtype для указания типа данных в столбцах. Это позволяет контролировать процесс создания DataFrame и адаптировать его под специфические задачи анализа.
Этот метод преобразования является удобным инструментом для работы с данными в Python, поскольку pandas предоставляет мощные возможности для манипуляций с данными, включая фильтрацию, агрегацию и визуализацию. Использование DataFrame позволяет организовать данные в легко обрабатываемом и масштабируемом формате, что важно при работе с большими объемами информации.