Для решения задачи нахождения самого длинного слова в строке на Python существует несколько методов, каждый из которых имеет свои особенности. Основной подход заключается в разбиении строки на слова и дальнейшем анализе их длины. Важно учитывать, что под словом в данном контексте подразумевается последовательность символов, разделенная пробелами или другими разделителями.
Алгоритм решения задачи сводится к простому разбиению строки с помощью метода split(), который по умолчанию делит строку по пробелам. После этого следует пройтись по всем полученным словам и найти максимальное по длине. Также стоит отметить, что при работе с многословными строками необходимо учитывать различные знаки препинания, которые могут влиять на результат, поэтому полезно использовать методы обработки текста, такие как strip() или регулярные выражения.
Для повышения производительности можно использовать генераторы или встроенные функции, такие как max(), которая позволяет одновременно находить слово с максимальной длиной без явного перебора всех элементов с помощью циклов. Этот подход эффективно сокращает количество кода и делает программу более читабельной и производительной.
Пример реализации такого алгоритма может выглядеть следующим образом: после разбиения строки на слова, с помощью max() можно извлечь слово с наибольшей длиной. Для точности вычислений стоит помнить, что для игнорирования знаков препинания и пробелов следует предварительно обработать строку, что позволит избежать ошибок в подсчете длины.
Как разбить строку на отдельные слова с учётом знаков препинания
Разбиение строки на слова с учётом знаков препинания – задача, которая может потребовать учёта нюансов при работе с текстами на русском языке. Часто нужно разделить строку так, чтобы знаки препинания оставались связаны с соответствующими словами. Рассмотрим, как это сделать на Python с помощью регулярных выражений.
Для этой задачи удобно использовать модуль re, который позволяет работать с регулярными выражениями. Основной принцип заключается в том, чтобы правильно определить паттерн, который разделяет слова, но при этом оставляет знаки препинания связанными с ближайшими словами. Например, «дом!» должно быть сохранено как одно слово, а не как два – «дом» и «!».
Пример регулярного выражения для разбиения строки на слова, учитывая знаки препинания:
import re
text = "Привет, мир! Как дела?"
words = re.findall(r'\b\w+[\w\'-]*[.,!?;]*\b', text)
print(words)
Регулярное выражение \b\w+[\w\'-]*[.,!?;]*\b работает следующим образом:
\b– граница слова, чтобы гарантировать, что символы не будут ошибочно распознаны как часть слова;\w+– одно или несколько буквенно-цифровых символов (основная часть слова);[\w\'-]*– дополнительная часть слова, которая может включать апострофы или дефисы;[.,!?;]*– знак препинания, если он имеется, может быть в конце слова;\b– ещё одна граница слова.
Этот паттерн позволяет корректно выделить слова с учётом знаков препинания, таких как запятые, точки и восклицательные знаки. Результат работы программы для строки «Привет, мир! Как дела?» будет следующим:
['Привет,', 'мир!', 'Как', 'дела?']
Важным моментом является то, что регулярное выражение гарантирует, что знаки препинания останутся прикреплёнными к словам, к которым они принадлежат. Это особенно важно при дальнейшей обработке текста, например, при анализе частотности слов или поиске самых длинных слов.
Если же необходимо исключить знаки препинания, можно использовать немного более простое регулярное выражение, которое будет игнорировать их, например:
words = re.findall(r'\b\w+\b', text)
Этот подход поможет эффективно обрабатывать тексты с различными символами и знаками препинания, что крайне полезно при разработке алгоритмов для обработки естественного языка.
Каким способом определить длину каждого слова в списке
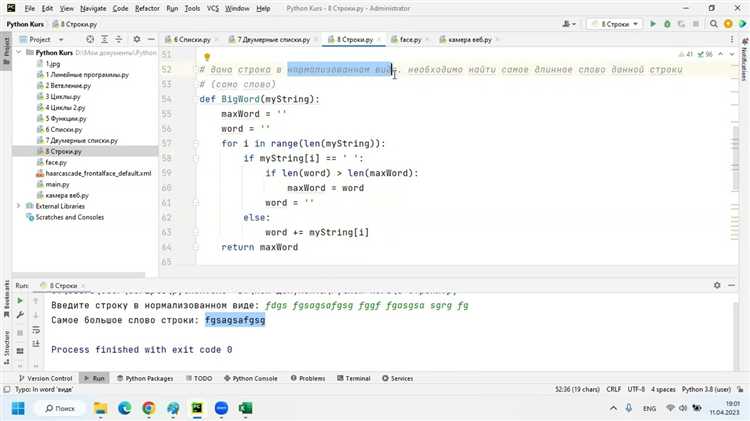
Для того чтобы узнать длину каждого слова в списке, можно воспользоваться функцией len(), которая вычисляет количество символов в строке. Для этого достаточно пройтись по списку с помощью цикла и применить функцию к каждому элементу. Рассмотрим несколько способов реализации.
Самый простой способ – использование цикла for. Пример кода:
words = ["яблоко", "банан", "вишня"] lengths = [] for word in words: lengths.append(len(word)) print(lengths)
Этот код создает новый список lengths, в котором содержатся длины слов из исходного списка.
Если необходимо получить пары «слово-длина», то можно воспользоваться list comprehension:
words = ["яблоко", "банан", "вишня"] lengths = [(word, len(word)) for word in words] print(lengths)
Результатом будет список кортежей, в котором каждое слово связано с его длиной.
Для более компактного представления можно использовать функцию map() для применения len() ко всем элементам списка:
words = ["яблоко", "банан", "вишня"] lengths = list(map(len, words)) print(lengths)
Этот метод позволяет избежать явного цикла, сокращая код, однако он требует конвертации результата в список.
Если список слов очень большой, можно использовать генератор вместо списка, чтобы сэкономить память:
words = ["яблоко", "банан", "вишня"] lengths = (len(word) for word in words) for length in lengths: print(length)
Этот метод не создает дополнительного списка, а генерирует значения по мере их запроса, что особенно полезно для работы с большими данными.
Каждый из этих способов позволяет легко и эффективно вычислить длину каждого слова в списке. Выбор подходящего метода зависит от требований к коду и объема данных, с которыми необходимо работать.
Как найти слово с максимальной длиной без использования циклов

Для нахождения самого длинного слова в строке без использования циклов можно воспользоваться встроенными возможностями Python. Важно отметить, что Python предоставляет мощные функции и методы, которые позволяют решать задачи без явных циклов.
Основным инструментом для этой задачи будет метод max(), который позволяет находить элемент с максимальным значением в последовательности. В сочетании с функцией len(), которая возвращает длину строки, можно легко определить самое длинное слово.
Пример решения задачи:
text = "Этот пример демонстрирует решение задачи"
longest_word = max(text.split(), key=len)
print(longest_word)Разберем поэтапно:
text.split()– метод разбивает строку на список слов по пробелам.max(..., key=len)– функцияmaxнаходит элемент с максимальным значением. В данном случае используется аргументkey=len, что означает, что максимальная длина будет определяться по длине каждого слова.
Такой подход исключает необходимость использования циклов и делает код более читаемым и кратким. Также стоит отметить, что данное решение эффективно для строк, разделенных пробелами, и для других разделителей можно использовать параметры в методе split().
Преимущества метода:
- Простота и лаконичность.
- Отсутствие явных циклов делает код более Pythonic и понятным.
- Использование стандартных функций и методов, не требующих внешних библиотек.
Обработка строк с несколькими пробелами и табуляцией
Когда строка содержит несколько пробелов подряд или табуляцию, важно корректно обработать такие символы для получения точных результатов при анализе текста. В Python для этого есть несколько подходов.
Использование метода split() позволяет эффективно разделить строку на слова, игнорируя лишние пробелы и табуляции. Этот метод по умолчанию разделяет строку по любому количеству пробельных символов, включая пробелы, табуляцию и новые строки, что делает его удобным для обработки текста с переменной длиной пробелов между словами. Например:
text = "Пример текста с табуляцией\tи несколькими пробелами"
words = text.split()
print(words) # ['Пример', 'текста', 'с', 'табуляцией', 'и', 'несколькими', 'пробелами']
Этот метод удаляет лишние пробелы и табуляции, возвращая список слов без учета количества пробельных символов.
Использование регулярных выражений с помощью модуля re также может быть полезным для более точного контроля. Например, для замены всех видов пробельных символов (включая табуляцию) на один пробел, можно использовать выражение:
import re
text = "Пример\tс несколькими пробелами и табуляцией"
text = re.sub(r'\s+', ' ', text)
print(text) # 'Пример с несколькими пробелами и табуляцией'
Регулярное выражение \s+ находит один или более пробельных символов и заменяет их на один пробел. Это полезно, когда нужно привести строку к стандартному виду с одним пробелом между словами.
Удаление лишних пробелов в начале и в конце строки можно выполнить с помощью метода strip(). Этот метод удаляет все пробельные символы (в том числе табуляции) с краев строки:
text = "\t Пример строки с пробелами и табуляциями \n"
text = text.strip()
print(text) # 'Пример строки с пробелами и табуляциями'
Метод strip() полезен при очистке строк от лишних пробелов перед началом обработки данных, что предотвращает возможные ошибки при анализе или сравнении строк.
Таким образом, эффективная обработка строк с несколькими пробелами и табуляцией требует правильного выбора методов для разделения, замены и очистки данных. Использование split(), re.sub() и strip() позволяет корректно работать с текстами, содержащими различное количество пробельных символов, и минимизирует вероятность ошибок в последующем анализе строк.
Работа с текстом на разных языках и поддержка Unicode

При работе с текстом на Python необходимо учитывать поддержку различных языков и символов, особенно когда речь идет о многозначных или редких символах, используемых в других алфавитах. Для этого в Python используется стандарт Unicode, который позволяет представлять символы из практически всех существующих языков мира.
Чтобы корректно работать с текстом на разных языках, важно понимать, как Python обрабатывает строки и как это связано с кодировками. В Python 3 строки по умолчанию являются объектами типа str, которые используют Unicode для хранения символов. Это позволяет работать с текстом на разных языках без необходимости менять кодировку вручную.
Для правильной работы с Unicode важно следить за кодировкой при чтении и записи данных. Например, при чтении файла с текстом на другом языке нужно явно указать кодировку. Это можно сделать через аргумент encoding в функциях чтения и записи файлов:
with open('file.txt', 'r', encoding='utf-8') as f:
text = f.read()
Также важно знать, что операции над строками в Python, такие как поиск подстроки, замена или нахождение длины строки, будут работать корректно, независимо от языка, поскольку строки на основе Unicode представляют символы, а не байты. Однако стоит помнить, что операция с символами в различных языках может иметь разные особенности. Например, в языках с диакритическими знаками, как в арабском или французском, один символ может занимать несколько байтов, что стоит учитывать при манипуляциях с такими строками.
Использование Unicode позволяет избежать проблем с различными кодировками, однако иногда необходимо работать с конкретными кодировками, например, в ситуациях, когда данные поступают в устаревших кодировках, таких как Windows-1251 для кириллицы. В таких случаях Python предоставляет инструменты для преобразования кодировок через метод encode() и decode():
text = 'Привет, мир!'
encoded_text = text.encode('utf-8')
decoded_text = encoded_text.decode('utf-8')
Для корректной работы с текстом в разных языках важно также тестировать программы на разных языковых данных, чтобы исключить ошибочные символы, возникающие при неправильном декодировании текста. Правильное использование Unicode в Python позволяет легко работать с текстами любых языков и символов, обеспечивая универсальность и совместимость приложений.
Как вернуть не только слово, но и его позицию в исходной строке

Чтобы не просто найти самое длинное слово в строке, но и узнать его позицию, можно воспользоваться встроенными средствами Python, такими как методы строк и регулярные выражения. Рассмотрим несколько подходов.
1. Использование метода split() для разделения строки: Сначала разделим строку на слова, а затем будем отслеживать длину каждого слова и его индекс в исходной строке.
def find_longest_word_with_position(text):
words = text.split()
longest_word = ''
position = -1
for i, word in enumerate(words):
if len(word) > len(longest_word):
longest_word = word
position = text.find(word)
return longest_word, position
В данном коде используется метод find() для поиска позиции первого символа слова в исходной строке. Это решение эффективно для случаев, когда важно точно узнать местоположение слова в строке.
2. Применение регулярных выражений: Когда нужно учитывать дополнительные условия (например, пропуск знаков препинания или пробелов), можно использовать модуль re.
import re
def find_longest_word_with_position_regex(text):
words = re.findall(r'\w+', text)
longest_word = ''
position = -1
for word in words:
start_pos = text.find(word)
if len(word) > len(longest_word):
longest_word = word
position = start_pos
return longest_word, position
Здесь findall() находит все слова, состоящие из букв и цифр, игнорируя другие символы. Мы снова используем find() для нахождения позиции каждого слова, но теперь регулярные выражения позволяют нам более гибко обрабатывать строку.
3. Учет нескольких одинаковых по длине слов: Важно помнить, что если строка содержит несколько слов одинаковой длины, функция вернёт первое из них. Если требуется найти все такие слова, необходимо немного изменить алгоритм, добавив список всех позиций.
def find_longest_words_with_positions(text):
words = text.split()
longest_word_length = 0
positions = []
for i, word in enumerate(words):
if len(word) > longest_word_length:
longest_word_length = len(word)
positions = [text.find(word)]
elif len(word) == longest_word_length:
positions.append(text.find(word))
return words[positions[0]], positions
В этом примере мы отслеживаем все позиции, где встречаются слова максимальной длины.
Итог: Для поиска самого длинного слова и его позиции можно использовать разные методы, в зависимости от условий задачи. Регулярные выражения дают гибкость в обработке сложных строк, в то время как метод split() с find() идеально подходит для простых случаев.
Вопрос-ответ:
Что означает «самое длинное слово» в контексте задачи на Python?
Самое длинное слово в строке — это слово, которое содержит наибольшее количество символов среди всех слов строки. В контексте задачи на Python необходимо найти такое слово, пройти по строке и сравнить длину каждого слова, чтобы определить, какое из них самое длинное.