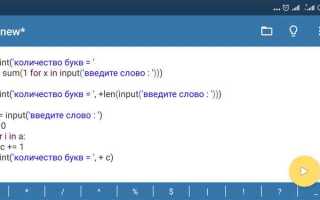
При работе с текстовыми строками в Python нередко возникает необходимость извлечь отдельные символы. В этой статье мы рассмотрим, как найти среднюю букву в слове, что может быть полезно в различных задачах, например, при анализе текста или в играх с текстом.
Для поиска средней буквы строки достаточно использовать индексацию. Однако важно учитывать, что в зависимости от длины строки метод получения может немного различаться. Если длина строки нечётная, средняя буква будет единственной. В случае чётной длины строки можно выделить две центральные буквы, но для простоты возьмём только одну, как обычно в задачах программирования.
Для начала определим, как именно получить индекс средней буквы. Если длина строки нечётная, то индекс будет находиться по формуле len(word) // 2, где word – это сама строка. Для строк чётной длины можно выбрать либо первую, либо вторую из двух центральных букв, в зависимости от задачи. Ниже приведён простой пример для строки нечётной длины:
Как проверить длину строки для поиска средней буквы
Чтобы корректно найти среднюю букву в строке, важно сначала определить её длину. Это необходимо для того, чтобы понять, на чём базировать расчёт индекса. Для этого используется встроенная функция len(), которая возвращает количество символов в строке.
Если длина строки нечётная, средняя буква будет находиться на индексе, равном половине длины строки. Например, для строки с длиной 5 (индексы 0, 1, 2, 3, 4), средний символ будет находиться на индексе 2.
Если длина строки чётная, «средних» букв несколько, и можно принять решение, какую из них выбрать. Одна из возможных стратегий – возвращать символ, стоящий на позиции, равной len(строка) // 2 - 1, чтобы получить первый символ из двух средних. В любом случае, нужно учитывать, что с чётной длиной строки нет единственного центра, и выбор средней буквы зависит от контекста задачи.
Пример: для строки «example» длина строки равна 7, средняя буква будет на индексе 3. Для строки «python» длина строки равна 6, средние буквы будут на индексах 2 и 3.
Понимание длины строки и её чётности – важный шаг для реализации алгоритма нахождения средней буквы, и это основа, на которой строится весь дальнейший код.
Как получить центральный символ в строке с нечётной длиной

Для того чтобы извлечь центральный символ из строки с нечётной длиной, нужно понять принцип работы индексов в Python. В строках индексы начинаются с нуля, а длина строки определяется функцией len().
Когда строка имеет нечётную длину, её центральный символ находится в середине. Например, для строки из 5 символов, центральный элемент будет на позиции 2 (поскольку индексация начинается с нуля). Это можно выразить через индекс: len(s) // 2.
Пример кода для получения центрального символа:
s = "example"
central_char = s[len(s) // 2]
print(central_char)Здесь s[len(s) // 2] извлекает символ на средней позиции строки. В случае строки с нечётной длиной это всегда будет единственный центральный символ.
Если строка имеет чётную длину, то выделение единственного центрального символа невозможно, так как центральных символов два. В таких случаях код будет работать, но индекс вернёт один из символов, а не два одновременно.
Важно: данная техника работает только для строк нечётной длины, так как для чётных строк «центральный символ» не существует в привычном смысле. Для строк нечётной длины метод s[len(s) // 2] всегда будет возвращать один символ, который находится в центре.
Что делать, если длина строки чётная, чтобы найти среднюю букву
Когда длина строки чётная, понятие «средняя буква» теряет свой стандартный смысл, так как средняя буква теоретически отсутствует. В таких случаях можно использовать один из двух подходов:
- Вернуть две центральные буквы. Это наиболее логичный подход для строк с чётной длиной. Например, для строки «программирование» (16 символов) можно вернуть буквы, расположенные на позициях 8 и 9. В Python это можно реализовать следующим образом:
word = "программирование" middle_letters = word[len(word)//2 - 1:len(word)//2 + 1] print(middle_letters)
Этот код извлечёт центральные буквы строки и вернёт «мм».
- Использовать один из символов как представление средней буквы. Это может быть удобным решением, если нужно вернуть только один символ, несмотря на чётную длину. В таком случае можно выбрать, например, букву с меньшим индексом (по умолчанию это левая из двух центральных букв). Пример:
word = "программирование" middle_letter = word[len(word)//2 - 1] print(middle_letter)
Этот код вернёт букву «м», которая находится слева от центральных символов.
В любом случае важно понимать, что для чётной длины строки нет однозначной «средней» буквы. Выбор зависит от того, какой результат требуется в конкретной задаче.
Как работать с индексами в строках для поиска центральной буквы
Рассмотрим следующие моменты при работе с индексами:
- Индексация строк: индексы начинаются с нуля. Первый символ строки находится на позиции 0, второй – на 1 и так далее.
- Отрицательные индексы: они используются для обращения к символам с конца строки. Индекс -1 указывает на последний символ, -2 – на предпоследний и так далее.
- Длина строки: функция
len()возвращает количество символов в строке. Для строки с нечётным количеством символов центральный символ будет располагаться на индексеlen(строки) // 2. Для строки с чётным количеством символов центральной буквы нет, но можно выбрать две центральные.
Пример 1. Поиск центральной буквы в строке с нечётным числом символов:
word = "программирование"
central_index = len(word) // 2
central_letter = word[central_index]
print(central_letter) # Выведет 'р'
В этом примере строка «программирование» имеет 16 символов, и центральная буква расположена на позиции 8.
Пример 2. Работа с чётным числом символов:
word = "машина"
first_central_index = len(word) // 2 - 1
second_central_index = len(word) // 2
first_central_letter = word[first_central_index]
second_central_letter = word[second_central_index]
print(first_central_letter, second_central_letter) # Выведет 'ш и'
В строке «машина» два центральных символа – ‘ш’ и ‘и’. Мы находим их с помощью индексов, разделив длину строки на два.
Примечание: при поиске центральной буквы важно учитывать, что индексация в Python начинается с 0. При использовании целочисленного деления (оператор //) мы получаем правильный индекс для поиска центрального символа.
- Для нечётных строк: центральная буква находится на индексе
len(строки) // 2. - Для чётных строк: центральные буквы находятся на индексах
len(строки) // 2 - 1иlen(строки) // 2.
Работа с индексами в строках – это мощный инструмент для решения задач, связанных с анализом текста. Знание принципов индексации позволит легко находить центральные буквы и эффективно работать с текстовыми данными в Python.
Как обрабатывать пустые строки при поиске средней буквы

Для проверки пустой строки в Python можно использовать условие:
if not word:Если строка пустая, программа должна обработать этот случай отдельно. Например, вернуть специальное сообщение, информирующее пользователя о недопустимости пустой строки:
if not word:
return "Ошибка: строка пуста"Таким образом, исключается возможность ошибок, связанных с отсутствием символов в строке. Важно помнить, что пустая строка не имеет длины, а значит, нельзя вычислить индекс средней буквы. Применение такого подхода позволяет гарантировать стабильную работу программы, предотвращая сбои при некорректных входных данных.
Кроме того, можно использовать дополнительные проверки на строку, которая состоит только из пробелов. В таких случаях также следует учитывать её как пустую и возвращать соответствующее сообщение об ошибке.
if not word.strip():
return "Ошибка: строка пуста или состоит из пробелов"Этот метод поможет избежать неочевидных ошибок, когда строка визуально не пустая, но на самом деле не содержит значимой информации.
Использование срезов для извлечения средней буквы

Если длина слова нечётная, среднюю букву можно извлечь, используя индекс середины. Например, для строки длиной 5 символов индекс средней буквы будет равен 2, так как индексация начинается с нуля. Чтобы получить её, достаточно воспользоваться срезом с шагом 1 и нужным индексом.
Пример для нечётного числа символов:
word = "программ"
middle_char = word[len(word) // 2]
print(middle_char)
Когда длина строки чётная, можно использовать два индекса, чтобы извлечь два центральных символа. Например, для строки длиной 6 символов средними будут символы с индексами 2 и 3. В этом случае срез с шагом 1 обеспечит нужный результат.
Пример для чётного числа символов:
word = "питание"
middle_chars = word[len(word) // 2 - 1 : len(word) // 2 + 1]
print(middle_chars)
Таким образом, срезы в Python позволяют просто и быстро извлечь среднюю букву или пару символов из строки, в зависимости от её длины. Важно учитывать, что индексация начинается с нуля, а операции среза включают начальный индекс, но не конечный.
Как написать функцию для нахождения средней буквы в слове

Для того чтобы найти среднюю букву в слове, необходимо учесть несколько важных моментов. Во-первых, слово может быть как четной, так и нечетной длины. В случае нечетной длины задача решается просто, так как середина будет однозначно определена. Если длина слова четная, то для нахождения «средней» буквы можно взять либо одну из двух центральных букв, либо выбрать подходящее соглашение для обработки этого случая.
Рассмотрим решение задачи для нечетной длины. В таком случае индекс средней буквы можно вычислить с помощью формулы: len(word) // 2, где len(word) – длина строки, а оператор // позволяет выполнить целочисленное деление. Этот индекс указывает на позицию центрального символа.
Для четной длины можно выбрать, например, символы, расположенные в индексах len(word) // 2 - 1 и len(word) // 2, или же установить одно значение, принимая в расчет обе буквы. Чаще всего в таких случаях берется первая из двух центральных букв.
Пример реализации функции для поиска средней буквы:
def find_middle_letter(word):
length = len(word)
if length % 2 == 1: # Если длина слова нечетная
return word[length // 2]
else: # Если длина слова четная
return word[length // 2 - 1]
Этот код определяет среднюю букву для нечетных слов и одну из центральных букв для четных слов. Функция возвращает корректный результат в обоих случаях.
Если необходимо работать с несколькими словами одновременно, например, найти среднюю букву в каждом слове из списка, можно добавить цикл, который будет обходить все слова.
def find_middle_letters(words):
return [find_middle_letter(word) for word in words]
Этот подход позволяет обрабатывать сразу несколько слов, применяя к каждому из них функцию поиска средней буквы.
Вопрос-ответ:
Как найти среднюю букву в слове с помощью Python?
Для того чтобы найти среднюю букву в слове, нужно сначала понять, что это за буква. Если длина слова нечётная, то средняя буква будет находиться в середине. Если длина слова чётная, то можно взять две центральные буквы или выбрать одну по своему усмотрению. В Python можно использовать индексы строк для нахождения средней буквы. Например, если строка имеет нечётную длину, можно найти её как элемент с индексом, равным длине строки, делённой на два. Если длина чётная, можно получить два центральных символа.
Как в Python определить, есть ли в слове центральная буква?
Чтобы понять, есть ли центральная буква в слове, можно проверить, чётная ли его длина. Если длина нечётная, то центральная буква существует, её индекс будет равен длине строки, делённой на два (с использованием целочисленного деления). Если же длина чётная, то центральных букв будет две. Таким образом, проверка длины строки поможет определить, есть ли в слове одна центральная буква или две.
Можно ли использовать срезы для поиска средней буквы в слове на Python?
Да, для поиска средней буквы можно использовать срезы. Например, если длина слова нечётная, то для нахождения центральной буквы можно использовать выражение слово[len(слово)//2], где len(слово)//2 даёт индекс середины. В случае чётной длины строки, для извлечения двух центральных букв можно использовать срез: слово[len(слово)//2 — 1 : len(слово)//2 + 1].
Что делать, если слово состоит из нескольких символов и длина его чётная?
Если длина слова чётная, то центральных букв будет две. В этом случае можно решить, как именно поступить в зависимости от задачи. Например, можно вывести обе центральные буквы или выбрать одну. В Python это можно сделать с помощью среза строки. Например, для извлечения двух центральных символов можно использовать слово[len(слово)//2 — 1 : len(слово)//2 + 1].
Как найти центральную букву в слове, если его длина чётная или нечётная?
Если длина слова нечётная, то центральная буква будет единственной, и её индекс можно вычислить с помощью формулы len(слово)//2. Если длина слова чётная, то центральных букв будет две, и их можно извлечь с помощью среза. Например, для получения двух центральных символов можно использовать слово[len(слово)//2 — 1 : len(слово)//2 + 1]. Это поможет корректно обработать оба случая.