Работа с бинарными файлами на Python требует знания особенностей их открытия и обработки. В отличие от текстовых файлов, бинарные файлы содержат данные в сжатом или неизменённом виде, что требует использования особых режимов открытия и специфических методов чтения. Чтобы работать с такими файлами, важно учитывать как их структуру, так и кодировку данных, если она присутствует.
Для открытия бинарного файла в Python используется встроенная функция open() с режимом ‘rb’ (чтение в бинарном формате). Этот режим позволяет не изменять данные при их считывании. Пример кода:
file = open('example.bin', 'rb')
data = file.read()
file.close()После открытия файла можно работать с его содержимым, применяя методы для манипуляции с бинарными данными, например, считывать определённые блоки данных или записывать их в другой файл. Для обработки больших файлов удобно использовать методы чтения по частям, что позволяет избежать чрезмерной загрузки памяти.
Для записи бинарных данных используется режим ‘wb’, который открывает файл для записи в бинарном формате. Важно помнить, что при записи данных важно точно знать структуру данных, чтобы избежать потери информации.
Одной из важных особенностей работы с бинарными файлами является необходимость преобразования данных в соответствующий формат перед записью или чтением. Например, при работе с числами или строками нужно использовать методы struct или array для преобразования в байтовые представления.
Чтение бинарного файла с использованием built-in функции open()

В Python для работы с бинарными файлами используется функция open(), которая позволяет открыть файл в различных режимах. Для чтения бинарного файла необходимо использовать режим 'rb', который открывает файл в режиме только для чтения в бинарном формате. Это важно, так как текстовые файлы открываются в другом режиме, что приводит к неверной интерпретации данных.
Пример открытия бинарного файла:
with open('example.bin', 'rb') as file:
data = file.read()В приведенном примере файл example.bin открывается для чтения, и данные считываются в переменную data. Важно помнить, что метод read() считывает весь файл целиком. Для работы с большими файлами лучше считывать данные порциями с помощью параметра size, чтобы избежать переполнения памяти.
Пример чтения файла порциями:
with open('example.bin', 'rb') as file:
chunk = file.read(1024) # читаем 1024 байта
while chunk:
# обработка данных
chunk = file.read(1024)Когда необходимо работать с определенными байтами, можно использовать метод seek(), который позволяет перемещать указатель чтения в файл. Это полезно, если нужно вернуться к определенному участку файла или начать чтение с конкретной позиции.
Пример использования seek():
with open('example.bin', 'rb') as file:
file.seek(10) # перемещаем указатель на 10-й байт
data = file.read(5) # считываем 5 байтВажно учитывать, что open() возвращает объект типа file, который необходимо закрывать после завершения работы. Однако с помощью конструкции with файл автоматически закрывается после выхода из блока, что упрощает управление ресурсами.
При чтении бинарных данных важно понимать, что результат работы функции read() всегда будет представлять собой объект типа bytes. Этот объект можно обрабатывать с помощью различных встроенных функций, например, использовать срезы для выделения определенных частей данных.
Работа с байтами: использование метода read() для извлечения данных
Метод read() позволяет извлекать данные из бинарного файла в виде байтов. Этот метод полезен при работе с большими объемами информации, когда нужно эффективно обрабатывать двоичные файлы. Для корректной работы с методом важно учитывать несколько факторов.
Основной синтаксис метода:
file.read(size=-1)size– количество байт, которые необходимо прочитать. Если аргумент не передан или равен -1, метод извлечет все данные до конца файла.
Часто используется чтение файлов по частям, что позволяет экономить память, особенно если файл слишком велик. В этом случае указываем размер блока для чтения:
with open('file.bin', 'rb') as file:
chunk = file.read(1024) # Чтение 1024 байтов
while chunk:
process_chunk(chunk) # Обработка данных
chunk = file.read(1024)
Для извлечения всей информации из бинарного файла можно использовать метод read() без указания размера:
with open('file.bin', 'rb') as file:
data = file.read()
Однако такой подход не всегда эффективен при работе с большими файлами, так как метод пытается загрузить весь файл в память, что может привести к переполнению. Для таких случаев предпочтительнее читать файл по частям.
При чтении важно также учитывать позицию указателя файла. Каждый вызов read() перемещает указатель на соответствующее количество байт. Чтобы узнать текущую позицию, можно использовать метод tell():
with open('file.bin', 'rb') as file:
file.read(10) # Чтение первых 10 байт
print(file.tell()) # Текущая позиция в файле
Для того чтобы вернуться к начальной позиции, используется метод seek():
with open('file.bin', 'rb') as file:
file.read(10)
file.seek(0) # Возврат к начальной позиции
data = file.read()
Важно помнить, что метод read() не делает предположений о содержимом файла. Если требуется интерпретировать данные (например, в качестве текста), нужно конвертировать байты в соответствующий формат. Для работы с текстом лучше использовать кодировку, передавая параметр encoding в метод open().
Обработка больших бинарных файлов с использованием поблочного чтения
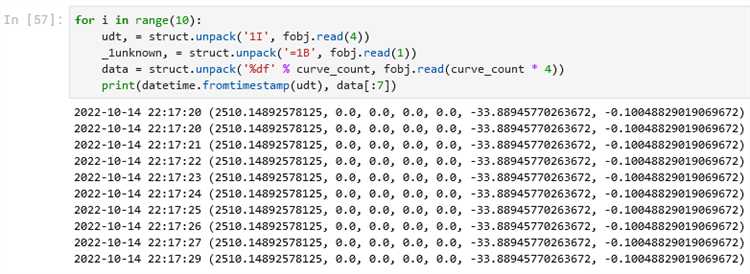
Для реализации поблочного чтения в Python используется встроенная функция open() с режимом открытия файла ‘rb’ (чтение в бинарном формате). Основная идея заключается в том, чтобы читать файл маленькими частями, используя метод read(size), где size – это количество байт, которое необходимо извлечь за один раз.
Пример кода для чтения файла поблочными данными:
with open('bigfile.bin', 'rb') as file:
block_size = 1024 # Размер блока в байтах
while True:
block = file.read(block_size)
if not block:
break
# Обработка блока данных
В приведенном примере файл читается блоками по 1024 байта. После чтения каждого блока его можно обработать, например, выполнить анализ данных или преобразования, не загружая весь файл в память.
Для более сложных задач можно комбинировать поблочное чтение с параллельной обработкой блоков, используя многозадачность или многопоточность. Это позволяет значительно ускорить обработку, особенно если файл сильно большой, а операции с данными могут быть распараллелены.
Таким образом, поблочное чтение – это эффективный метод работы с большими бинарными файлами в Python, который помогает экономить память и ускорять обработку данных.
Конвертация данных из бинарного формата в текстовый с помощью кодировок
Для конвертации бинарных данных в текстовый формат в Python используется метод декодирования с указанием соответствующей кодировки. Основные кодировки, такие как UTF-8, ASCII и ISO-8859-1, позволяют преобразовать байты в строку. Метод decode() применяется к байтовым данным, чтобы получить строковое представление в выбранной кодировке.
Пример кода для преобразования бинарных данных в строку с использованием UTF-8:
binary_data = b'\xe2\x9c\x94'
text = binary_data.decode('utf-8')
print(text)В результате выполнения кода будет выведен символ ✓. Этот подход работает, если бинарные данные были закодированы в соответствующей кодировке. Важно учитывать, что ошибка декодирования может возникнуть, если данные не соответствуют ожидаемой кодировке.
Для работы с кодировкой ASCII важно помнить, что она поддерживает только 128 символов, и попытка декодировать данные, содержащие символы за пределами этого набора, вызовет ошибку. Для таких случаев следует использовать кодировки, поддерживающие расширенные символы, например UTF-8 или ISO-8859-1.
Иногда данные могут быть закодированы в нестандартных кодировках или в пользовательских форматах, например, при работе с бинарными файлами. В таких случаях для правильного декодирования данных может понадобиться предварительная обработка или использование специфических библиотек для работы с такими кодировками.
Также стоит учитывать, что при конвертации больших объемов данных кодировки могут существенно повлиять на производительность программы. Важно выбирать подходящую кодировку в зависимости от типа данных и специфики задачи.
Использование библиотеки struct для парсинга бинарных данных
Библиотека struct в Python предоставляет мощные инструменты для работы с бинарными данными, которые часто встречаются в различных форматах файлов. Она позволяет эффективно читать и записывать данные в бинарном виде, а также интерпретировать их в соответствии с заданными форматами.
Для начала работы с struct нужно понять, как представляются различные типы данных в бинарном виде. Каждый тип данных имеет свой формат, который указывается с помощью строкового формата. Например, для целого числа можно использовать символ ‘i’, для 4-байтового вещественного числа – ‘f’.
Основные методы библиотеки struct – pack() и unpack(). Метод pack() используется для упаковки данных в бинарный формат, а метод unpack() – для их извлечения. Важным моментом является правильное указание формата данных, чтобы они корректно интерпретировались. Например:
import struct
# Упаковка данных
data = struct.pack('i f', 42, 3.14)
# Извлечение данных
unpacked_data = struct.unpack('i f', data)
print(unpacked_data) # (42, 3.14)
Формат строки передается как первый аргумент, и он определяет структуру данных, которые будут упакованы или извлечены. В примере выше ‘i’ указывает на целое число, а ‘f’ – на число с плавающей запятой.
Кроме стандартных форматов, библиотека поддерживает множество других типов данных, включая строковые, двоичные и даже фиксированные размеры данных, что делает её полезной для работы с нестандартными бинарными файлами, такими как форматы аудио, видео и сжатых данных.
Важно помнить, что для работы с бинарными файлами нужно точно знать структуру данных, чтобы корректно их распарсить. Если структура данных неизвестна, можно использовать инструмент struct.calcsize(), чтобы вычислить размер строки формата:
size = struct.calcsize('i f')
print(size) # 8
Библиотека struct – это простой, но мощный инструмент для работы с бинарными данными, который позволяет точно контролировать процесс упаковки и извлечения данных, минимизируя ошибки при работе с бинарными файлами.
Ошибки при открытии бинарных файлов и способы их устранения

При работе с бинарными файлами в Python могут возникать различные ошибки, связанные с неправильным использованием методов открытия или с некорректным содержимым файлов. Рассмотрим основные из них и способы их устранения.
1. Ошибка при неверном режиме открытия файла
- Ошибка: попытка открытия файла с режимом, который не поддерживает чтение или запись бинарных данных (например, текстовый режим ‘r’ вместо бинарного ‘rb’).
- Решение: всегда используйте режим ‘rb’ для чтения бинарных файлов и ‘wb’ для записи. Например:
open('file.bin', 'rb').
2. Файл не найден
- Ошибка: указанный файл не существует в заданном пути, или путь указан неверно.
- Решение: убедитесь, что путь к файлу корректен и файл действительно существует в указанной директории. Используйте полный путь, если это необходимо.
3. Невозможность открытия файла из-за прав доступа
- Ошибка: недостаточно прав для чтения или записи файла.
- Решение: проверьте права доступа к файлу и директории. На Unix-подобных системах можно использовать команду
ls -lдля проверки прав. Если необходимо, измените права с помощью командыchmod.
4. Попытка чтения некорректного бинарного формата
- Ошибка: чтение данных, которые не соответствуют ожидаемому бинарному формату, может привести к сбоям в работе программы или неожиданным результатам.
- Решение: перед чтением данных из файла убедитесь, что формат файла соответствует ожидаемому. Это можно сделать, проверив начало файла на наличие магического числа или сигнатуры, если они предусмотрены форматом.
5. Ошибка при декодировании бинарных данных
- Ошибка: попытка интерпретировать бинарные данные как текстовые или наоборот.
- Решение: убедитесь, что вы правильно интерпретируете данные. Для текстовых данных используйте методы, поддерживающие кодировки, например,
decode('utf-8'). Для бинарных данных используйте методы, не пытающиеся их декодировать в строку.
6. Ошибки, связанные с буферизацией
- Ошибка: программа пытается обработать файл в режиме, не подходящем для работы с большими объемами данных, что может привести к недостаточному объему памяти или сбоям.
- Решение: используйте методы, которые позволяют работать с файлами поблочно, например, с помощью
read(size), чтобы читать файл порциями.
7. Ошибки записи в бинарный файл
- Ошибка: попытка записи данных, которые не могут быть представлены в бинарном формате, или запись в файл, открытый для чтения.
- Решение: откройте файл в правильном режиме (‘wb’ для записи бинарных данных). Также убедитесь, что данные, которые вы пытаетесь записать, корректно преобразованы в байты.