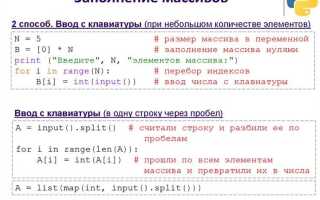
В Python для генерации всех возможных комбинаций элементов массива чаще всего используют модуль itertools. Функция itertools.combinations() возвращает комбинации без повторений, а itertools.product() – с повторениями. Оба метода работают с итераторами, что позволяет экономить память при работе с большими массивами.
Пример: чтобы получить все пары из списка [1, 2, 3], достаточно вызвать list(itertools.combinations([1, 2, 3], 2)). Результатом будет [(1, 2), (1, 3), (2, 3)]. Если нужна каждая возможная пара, включая повторы и смену порядка, используется product с параметром repeat=2.
Ручная реализация перебора возможна через вложенные циклы или рекурсию. Это может быть полезно, если необходимо наложить дополнительные условия на элементы комбинации, которые не поддерживаются стандартными функциями.
Перебор комбинаций – типичная задача при решении логических задач, оптимизационных моделей и генерации тестов. Важно учитывать, что количество комбинаций быстро растёт: для n элементов количество комбинаций длины k вычисляется по формуле C(n, k) = n! / (k! * (n — k)!). Это следует учитывать при работе с массивами длиной больше 10, особенно без использования генераторов.
Как сгенерировать все комбинации фиксированной длины с помощью itertools.combinations
Модуль itertools предоставляет функцию combinations(iterable, r), которая возвращает итератор по всем возможным комбинациям длины r, выбранным из элементов iterable без повторений и с сохранением порядка появления элементов.
Пример: пусть есть список [1, 2, 3, 4]. Чтобы получить все комбинации длиной 2:
from itertools import combinations
данные = [1, 2, 3, 4]
результат = list(combinations(данные, 2))
print(результат)
Аргумент r должен быть не больше длины входного массива. Если указать r = 0, результатом будет пустой кортеж [()]. Если r > len(iterable), результат будет пустым списком.
Если входной массив содержит одинаковые значения, комбинации будут содержать одинаковые элементы, но сами кортежи будут уникальны. Например, combinations([1, 1, 2], 2) даст: [(1, 1), (1, 2), (1, 2)].
Для перебора всех таких комбинаций можно использовать цикл:
for ком in combinations(данные, 2):
print(ком)
Функция combinations не создаёт весь список в памяти. Это генератор, поэтому подходит для обработки больших наборов данных. Для сохранения результата в список нужно обернуть вызов в list().
Перебор всех возможных подмножеств массива

Для генерации всех подмножеств массива в Python удобно использовать модуль itertools. Функция combinations позволяет получать подмножества фиксированной длины. Чтобы получить все возможные подмножества, включая пустое и полное, нужно перебрать длины от 0 до len(массив).
Пример:
from itertools import combinations
массив = [1, 2, 3]
результат = []
for r in range(len(массив) + 1):
результат.extend(combinations(массив, r))
for подмножество in результат:
print(подмножество)
Этот подход сохраняет порядок элементов и возвращает подмножества в виде кортежей. Если требуется список списков, используйте list(map(list, …)).
Генерация всех подмножеств – задача с экспоненциальной сложностью: при длине n общее количество подмножеств равно 2ⁿ. При работе с массивами длиной более 20 элементов объём данных быстро становится непрактичным для хранения и обработки. В таких случаях стоит фильтровать только нужные размеры подмножеств или использовать ленивые итераторы.
Для битового представления подмножеств можно применить побитовые операции:
массив = [1, 2, 3]
n = len(массив)
for i in range(1 << n):
подмножество = [массив[j] for j in range(n) if i & (1 << j)]
print(подмножество)
Этот способ не требует дополнительных библиотек и подходит для низкоуровневой оптимизации, например, в задачах перебора при динамическом программировании.
Чем отличается combinations от combinations_with_replacement
combinations_with_replacement допускает повторение одного и того же элемента внутри комбинации. При тех же аргументах, combinations_with_replacement([1, 2, 3], 2) выдаст: (1, 1), (1, 2), (1, 3), (2, 2), (2, 3), (3, 3). Здесь возможны пары с одинаковыми элементами, и общее число комбинаций будет больше.
Если нужно получить все уникальные пары без повторов внутри комбинаций и между ними – используйте combinations. Если необходимо учитывать повторяющиеся значения, например, при моделировании с возвращением, подходит combinations_with_replacement.
Оба генератора возвращают итераторы, поэтому для сохранения результата в список используйте list(). Объёмы данных резко возрастают при увеличении длины комбинации и количества элементов, особенно при использовании combinations_with_replacement, так как количество вариантов вычисляется по формуле C(n + r - 1, r), где n – длина массива, r – длина комбинации.
Как получить все перестановки элементов с помощью itertools.permutations
Функция itertools.permutations возвращает все возможные перестановки элементов итерируемого объекта заданной длины. Если длина не указана, используются все элементы.
Пример для массива [1, 2, 3]:
from itertools import permutations
arr = [1, 2, 3]
result = list(permutations(arr))
print(result)
Результат:
[(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]Чтобы получить перестановки фиксированной длины, передайте второй аргумент:
list(permutations([1, 2, 3], 2))Результат:
[(1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2)]Возвращаемые значения – кортежи. Для преобразования в список списков:
[list(p) for p in permutations(arr)]Если в массиве есть повторяющиеся элементы, результат будет содержать дубликаты. Для исключения повторов используйте set:
list(set(permutations([1, 1, 2])))Для повышения производительности не превращайте результат в список без необходимости. Итерируйтесь по генератору напрямую:
for p in permutations(arr):
обработка(p)Генерация комбинаций без использования сторонних библиотек
Чтобы сгенерировать все возможные комбинации элементов массива без библиотек вроде itertools, можно реализовать собственную функцию с использованием рекурсии или циклов. Пример ниже показывает базовую реализацию генерации всех комбинаций заданной длины.
def combinations(arr, r):
result = []
def backtrack(start, path):
if len(path) == r:
result.append(path[:])
return
for i in range(start, len(arr)):
path.append(arr[i])
backtrack(i + 1, path)
path.pop()
backtrack(0, [])
return result
Пример использования:
data = [1, 2, 3, 4]
r = 2
print(combinations(data, r))
- Функция использует обратный ход (backtracking), избегая повторов за счёт движения по массиву только вперёд.
- Промежуточный путь
pathкопируется при добавлении вresult, чтобы избежать мутаций. - Сложность по времени – O(C(n, r)), где n – длина массива, r – длина комбинации.
Для генерации всех возможных комбинаций всех длин от 1 до n:
def all_combinations(arr):
all_result = []
for r in range(1, len(arr) + 1):
all_result.extend(combinations(arr, r))
return all_result
Такая реализация полностью автономна, не требует импорта модулей и позволяет гибко управлять логикой перебора.
Как обрабатывать повторяющиеся элементы при переборе комбинаций
Для начала, чтобы избежать дублирования комбинаций, можно воспользоваться встроенной функцией itertools.combinations или itertools.permutations, которые автоматически генерируют уникальные комбинации. Однако, если необходимо обрабатывать массив, в котором элементы могут повторяться, то важно обеспечить фильтрацию одинаковых комбинаций.
Для этого можно воспользоваться следующим подходом: при генерации комбинаций сортируйте исходный массив перед его перебором. Таким образом, одинаковые элементы будут идти подряд, и можно будет применить логику, которая исключает дублированные комбинации.
Пример кода с использованием itertools.combinations:
import itertools
data = [1, 2, 2, 3]
unique_combinations = set(itertools.combinations(sorted(data), 2))
for combination in unique_combinations:
print(combination)
В этом примере элементы массива сортируются, а затем создаётся множество, что позволяет исключить дублирующие комбинации. Такой подход гарантирует, что каждая уникальная комбинация будет представлена только один раз.
Другим способом является использование словаря для хранения всех комбинаций, где ключом будет являться сама комбинация, а значением – количество её вхождений. Это полезно, если необходимо учитывать частоту появления каждого элемента в комбинациях.
Пример с использованием словаря:
from collections import defaultdict
data = [1, 2, 2, 3]
combinations_count = defaultdict(int)
for combination in itertools.combinations(sorted(data), 2):
combinations_count[combination] += 1
for combination, count in combinations_count.items():
print(f"Комбинация: {combination}, Количество: {count}")
Этот подход позволяет не только исключить дубли, но и учесть, сколько раз каждая комбинация появляется в процессе перебора. Это будет полезно, если задачи требуют учета повторений в различных комбинациях.
Таким образом, для эффективной обработки повторяющихся элементов при переборе комбинаций важно выбирать правильный инструмент и подход в зависимости от требований задачи. В большинстве случаев использование сортировки и множества или словаря помогает гарантировать уникальность и учёт повторений без лишних усилий.
Примеры применения перебора комбинаций в задачах на поиск подмножеств с заданной суммой
Задачи на поиск подмножеств с заданной суммой часто встречаются в области оптимизации, криптографии, теории чисел и в программировании. Основная цель – найти все возможные комбинации элементов массива, сумма которых равна заданному числу. Для эффективного решения таких задач используется перебор всех возможных подмножеств массива.
Одним из распространенных методов решения является использование библиотеки itertools в Python, которая предоставляет функционал для генерации комбинаций и перестановок элементов. Рассмотрим пример задачи: необходимо найти все подмножества массива, сумма которых равна заданному числу.
Пример задачи: дан массив чисел [1, 2, 3, 4, 5], нужно найти все подмножества, сумма которых равна 5.
Для решения этой задачи можно воспользоваться комбинациями:
from itertools import combinations def find_subsets_with_sum(arr, target_sum): result = [] for r in range(1, len(arr) + 1): for combo in combinations(arr, r): if sum(combo) == target_sum: result.append(combo) return result arr = [1, 2, 3, 4, 5] target_sum = 5 subsets = find_subsets_with_sum(arr, target_sum) print(subsets)
В результате выполнения программы, подмножества с суммой 5 будут следующими: [(1, 4), (2, 3), (5)].
Это решение перебирает все возможные комбинации элементов массива, начиная с одиночных и заканчивая всеми элементами массива. Хотя такой подход достаточно прост, для более больших массивов он может быть неэффективен из-за экспоненциального роста числа подмножеств. Поэтому для задач с большими массивами целесообразно использовать динамическое программирование или другие оптимизации.
Другим методом, который позволяет ускорить поиск, является использование хеширования для сохранения уже проверенных сумм подмножеств. Вместо того чтобы пересчитывать суммы для всех комбинаций, можно использовать структуру данных, которая будет хранить промежуточные результаты, ускоряя процесс поиска.
Как перебрать все бинарные маски для генерации подмножеств
Для перебора всех подмножеств множества часто применяют бинарные маски. Каждая маска представляет собой число, где каждый бит определяет, включен ли элемент множества в подмножество. Рассмотрим, как это работает и как эффективно реализовать такой подход в Python.
Предположим, что у нас есть массив с элементами:
arr = [1, 2, 3]
Число всех подмножеств этого массива равно 2n, где n – количество элементов. Мы можем воспользоваться бинарными масками от 0 до 2n — 1 для генерации всех возможных подмножеств.
Каждому числу в диапазоне от 0 до 2n — 1 соответствует одна бинарная маска. Например:
0 -> 000 1 -> 001 2 -> 010 3 -> 011 4 -> 100 5 -> 101 6 -> 110 7 -> 111
В бинарной маске бит, равный 1, означает, что соответствующий элемент множества включен в подмножество. Бит, равный 0, указывает на его отсутствие.
Как это реализовать в Python:
arr = [1, 2, 3] n = len(arr) for i in range(1 << n): subset = [arr[j] for j in range(n) if (i & (1 << j)) > 0] print(subset)
Здесь используется побитовая операция & для проверки, включен ли элемент в подмножество, и сдвиг влево для генерации всех масок от 0 до 2n — 1.
Как работает этот код:
- Переменная
iпробегает все числа от 0 до 2n — 1. - Для каждого числа
iмы проверяем каждый бит: если он равен 1, то добавляем соответствующий элемент в подмножество.
[] [1] [2] [1, 2] [3] [1, 3] [2, 3] [1, 2, 3]
Этот метод позволяет эффективно генерировать все подмножества множества, используя бинарные маски. Использование побитовых операций позволяет сократить количество итераций, делая алгоритм быстрым даже для больших наборов данных.