Работа с массивами в Python выходит за рамки простого использования списков. При необходимости числовых операций с высокой производительностью, используется модуль NumPy, предоставляющий структуру ndarray – массив фиксированной размерности, оптимизированный под векторные вычисления.
Преобразование обычного списка в массив осуществляется с помощью функции numpy.array(). Например, numpy.array([1, 2, 3]) создаёт одномерный массив из списка целых чисел. При передаче вложенных списков формируется многомерный массив: numpy.array([[1, 2], [3, 4]]) создаёт двумерную матрицу.
Если необходима конвертация с последующей обработкой в рамках численных методов (например, линейной алгебры), использование массивов предпочтительнее. Векторизация операций в NumPy позволяет обойтись без циклов: выражение array * 2 масштабирует весь массив за один шаг, чего не добиться обычными списками без явной итерации.
Как преобразовать список в массив с помощью модуля array
Модуль array предоставляет тип данных array.array, оптимизированный для хранения элементов одного типа. Для преобразования списка в массив используется конструктор array(), которому передаётся код типа и исходный список.
Пример: чтобы создать массив целых чисел из списка [1, 2, 3], необходимо указать код типа 'i' (signed int):
import array
lst = [1, 2, 3]
arr = array.array('i', lst)
Коды типов строго соответствуют форматам языка C. Например, 'f' – для чисел с плавающей точкой, 'u' – для символов Unicode (только в Python до версии 3.3). Использование неправильного кода приведёт к TypeError.
Перед созданием массива необходимо убедиться, что все элементы списка соответствуют выбранному типу. Например, при попытке передать строку в массив с кодом 'i' произойдёт ошибка:
array.array('i', [1, '2', 3]) # вызовет TypeErrorМассивы из модуля array экономичнее списков по памяти, особенно при больших объёмах однотипных данных. Их можно использовать в бинарных операциях и записи в файл через методы tofile() и fromfile(), что делает их удобными для низкоуровневой обработки данных.
Преобразование списка в массив NumPy для числовых вычислений

NumPy предоставляет структуру массива ndarray, оптимизированную для высокопроизводительных числовых операций. Преобразование обычного списка Python в массив NumPy позволяет ускорить вычисления и использовать специализированные функции библиотеки.
Чтобы преобразовать список, импортируйте NumPy и передайте список в функцию numpy.array():
import numpy as np
lst = [1, 2, 3, 4]
arr = np.array(lst)Ключевые особенности массивов NumPy:
- Хранят данные одного типа, что упрощает векторизацию операций.
- Поддерживают широкие возможности по работе с многомерными структурами.
- Обеспечивают доступ к функциям линейной алгебры, статистики и трансформаций.
Рекомендации по использованию:
- Для работы с числовыми данными всегда указывайте
dtypeпри создании массива, чтобы избежать неявных преобразований:arr = np.array([1, 2, 3], dtype=np.float64) - Если требуется многомерная структура, передавайте вложенные списки:
matrix = np.array([[1, 2], [3, 4]]) - Используйте
np.asarray(), если нужно избежать копирования объекта при преобразовании:arr = np.asarray(lst) - Для массивов фиксированного размера предпочтительнее использовать
np.array()вместо списков внутри циклов.
Работа с массивами NumPy в численных задачах значительно ускоряет обработку данных и уменьшает объем кода по сравнению со стандартными структурами Python.
Преобразование списка строк в массив байтов
Для преобразования списка строк в массив байтов используют метод encode() и модуль array или numpy. Важно определить нужную кодировку, чаще всего ‘utf-8’.
Если необходимо получить плоский массив байтов из строк:
strings = ['abc', 'def']
byte_array = bytearray()
for s in strings:
byte_array.extend(s.encode('utf-8'))
Результат: byte_array содержит b’abcdef’.
Чтобы сохранить границы строк, используют список байтовых представлений:
byte_sequences = [s.encode('utf-8') for s in strings]
Каждый элемент – отдельный объект типа bytes: [b’abc’, b’def’].
С модулем numpy массив байтов создаётся так:
import numpy as np
flat_bytes = np.frombuffer(''.join(strings).encode('utf-8'), dtype=np.uint8)
Для массивов фиксированной длины строк используют:
np_array = np.array(strings, dtype='S3') # длина строки – 3 байта
Это создаёт двумерный массив байтов фиксированной ширины. Нельзя указывать длину меньше, чем самая длинная строка – данные будут усечены.
При работе с различными кодировками учитывайте, что символы могут занимать разное количество байтов. Например, символы кириллицы в UTF-8 – по 2 байта.
Как изменить тип данных элементов при преобразовании

При преобразовании списка в массив с помощью NumPy важно сразу указать нужный тип данных, чтобы избежать неявных преобразований и потери точности. Используйте параметр dtype:
Пример:
import numpy as np
список = ['1', '2', '3']
массив = np.array(список, dtype=int)
В результате создаётся массив целых чисел int32 или int64 в зависимости от платформы.
Для вещественных чисел:
список = ['1.5', '2.7', '3.0']
массив = np.array(список, dtype=float)
Если элементы имеют нестандартный формат (например, с разделителем-запятой), сначала приведите их к нужному виду с помощью map() или list comprehension:
список = ['1,5', '2,7', '3,0']
массив = np.array([float(x.replace(',', '.')) for x in список])
Для преобразования в логический тип используйте:
список = [0, 1, 0, 1]
массив = np.array(список, dtype=bool)
Если список содержит значения разных типов, NumPy преобразует всё к общему типу с наименьшими потерями. Чтобы сохранить контроль, сначала явно преобразуйте элементы:
список = ['10', 20, '30']
массив = np.array([int(x) for x in список])
Избегайте автоматического выбора типа NumPy. Всегда задавайте dtype или предварительно обрабатывайте данные.
Что произойдет при попытке преобразовать вложенные списки

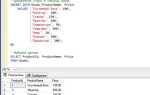
При использовании функции numpy.array() для преобразования вложенных списков результатом становится многомерный массив, если все вложенные списки имеют одинаковую длину. Например:
import numpy as np
a = [[1, 2], [3, 4]]
arr = np.array(a)В данном случае будет создан двумерный массив размерности (2, 2) с типом данных, определённым по наибольшей точности среди элементов.
Однако, если вложенные списки имеют различную длину, NumPy не сможет создать регулярную многомерную структуру. Пример:
a = [[1, 2], [3, 4, 5]]
arr = np.array(a)Результатом будет одномерный массив объектов (dtype=object), где каждый элемент – это отдельный список. Это поведение может привести к неожиданным ошибкам при дальнейших операциях над массивом, таких как арифметические действия, трансформации и агрегатные функции.
Чтобы избежать подобных ситуаций, рекомендуется предварительно проверять длину всех вложенных списков с помощью выражения:
all(len(sublist) == len(a[0]) for sublist in a)Если условие не выполняется, стоит либо привести данные к единой форме, либо использовать более гибкие структуры данных, такие как списки списков без преобразования в массив.
Обратное преобразование: из массива обратно в список

В Python преобразование массива обратно в список может быть полезным, если требуется использовать возможности, предоставляемые списками, такие как динамическое изменение размера или работа с элементами через индексы. Для выполнения этой задачи достаточно воспользоваться встроенной функцией list().
Основное преимущество этого подхода в том, что он прост и эффективен. Рассмотрим основные способы выполнения обратного преобразования:
- Использование функции
list(): Самый прямой способ преобразования массива в список – это передача массива в функциюlist().
Пример:
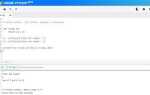
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
lst = list(arr)
print(lst)Этот способ быстро и безошибочно создаст новый список, состоящий из элементов массива. Однако стоит помнить, что исходный массив должен быть однотипным (состоящим из элементов одинакового типа), что характерно для массивов NumPy.
- Использование метода
tolist()для массивов NumPy: Если работа идет с массивами библиотеки NumPy, существует удобный методtolist(), который выполняет аналогичное преобразование.
Пример:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
lst = arr.tolist()
print(lst)Метод tolist() является более предпочтительным в контексте работы с NumPy, так как он учитывает специфические особенности этой библиотеки.
- Применение метода
list()к многомерным массивам: Для многомерных массивов методlist()будет работать рекурсивно, преобразуя массивы в списки на каждом уровне вложенности.
Пример для двумерного массива:
import numpy as np
arr = np.array([[1, 2], [3, 4], [5, 6]])
lst = list(arr)
print(lst)Этот код создаст список из вложенных списков, каждый из которых будет представлять строку двумерного массива. Для более сложных многомерных структур лучше использовать метод tolist(), который сохранит структуру массива в виде вложенных списков.
Важно помнить, что при преобразовании массива в список теряется информация о типах данных, оптимизированных в массиве, таких как типы NumPy. В списках Python все элементы будут иметь тип object, что может повлиять на производительность в случае работы с большими объемами данных.
Вопрос-ответ:
Зачем преобразовывать список в массив в Python?
Преобразование списка в массив необходимо, когда требуется работать с большими объемами данных или проводить сложные математические операции. Массивы, особенно в библиотеке NumPy, поддерживают векторные операции, что позволяет быстрее выполнять расчеты, чем со списками. Например, можно выполнять операции сложения, вычитания и умножения сразу с каждым элементом массива, что значительно упрощает код.
Чем массив отличается от списка в Python?
Список в Python представляет собой коллекцию элементов, которые могут быть разных типов, и поддерживает динамическое изменение размера. Массивы, в свою очередь, обычно используют для хранения элементов одного типа и имеют фиксированный размер после создания. В Python массивы чаще всего ассоциируются с библиотекой NumPy, где они позволяют проводить математические операции над элементами массива. Это делает их более эффективными в обработке числовых данных, чем списки.
Какие типы данных могут быть в массиве в Python?
В массивах, созданных с помощью NumPy, элементы должны быть одного типа. Этот тип можно указать при создании массива, либо NumPy автоматически определит его из типов элементов. Наиболее распространенными типами данных для массивов являются целые числа (`int`), числа с плавающей запятой (`float`), булевы значения (`bool`) и строки (`str`). Если вы создаете массив, состоящий, например, из целых чисел, все элементы массива будут этого типа, что ускоряет операции над ними.
Какие преимущества дает использование массива вместо списка в Python?
Массивы (например, через NumPy) предоставляют ряд преимуществ перед списками в Python. Во-первых, они работают быстрее при обработке больших объемов данных, так как NumPy использует оптимизированный C-код под капотом. Во-вторых, массивы поддерживают векторные операции, позволяя выполнять вычисления с каждым элементом без необходимости писать циклы. В-третьих, массивы имеют дополнительные методы для обработки данных, такие как изменение формы, транспонирование, срезы и другие операции, которые облегчают работу с многомерными данными.