

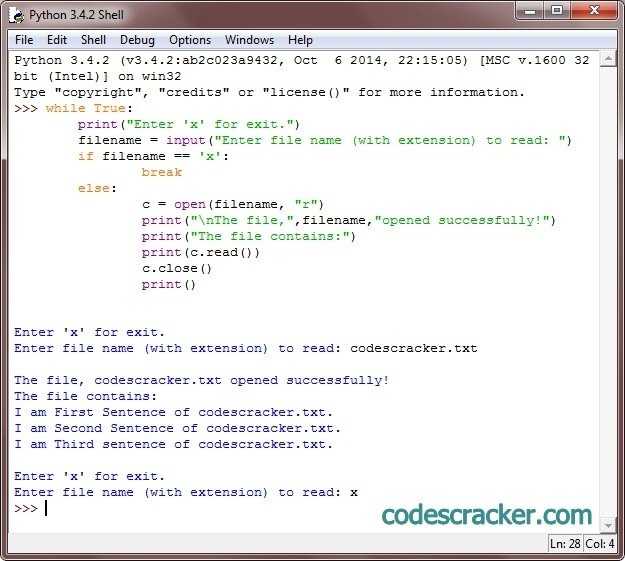
Для работы с текстовыми файлами в Python используется встроенная функция open(), которая позволяет открыть файл в различных режимах. Открытие файла происходит с указанием пути к файлу и режима доступа. Например, чтобы открыть файл для чтения, нужно использовать режим ‘r’, для записи – ‘w’, а для добавления данных в конец файла – ‘a’.
После открытия файла, для получения данных, можно воспользоваться методом read(), который возвращает весь содержимое файла в виде строки. Для построчного чтения чаще используется метод readlines(), который возвращает список строк, где каждая строка – это отдельный элемент списка.
Не забывайте о важности закрытия файла после работы с ним, что можно сделать с помощью метода close(). Однако рекомендуется использовать конструкцию with open() as file:, которая автоматически закрывает файл после завершения работы, предотвращая утечки ресурсов.
Работа с кодировками также имеет значение при импорте текстовых файлов. Для правильной обработки символов из различных языков или при работе с файлами, содержащими нестандартные символы, следует явно указать кодировку при открытии файла, например, open(‘file.txt’, ‘r’, encoding=’utf-8′).
При работе с большими файлами стоит помнить о производительности. Вместо чтения всего содержимого в память с помощью read(), рекомендуется использовать методы, позволяющие работать с файлом по частям, например, readline() или итерацию по файлу в цикле. Это поможет избежать переполнения памяти при обработке крупных файлов.
Чтение текстового файла с использованием функции open()
Функция open() в Python используется для открытия файлов, что позволяет работать с их содержимым. Для чтения текстового файла достаточно передать путь к файлу и режим «r» (чтение) при вызове этой функции.
Простейший способ открыть файл для чтения:
file = open('example.txt', 'r')Этот код откроет файл example.txt в текущей директории в режиме только для чтения. Если файл не существует, будет вызвана ошибка FileNotFoundError.
Для чтения содержимого файла можно использовать несколько методов. Например, метод read() считывает весь текст в одном вызове:
content = file.read()Метод readline() позволяет считывать файл построчно. Каждое вызванное readline() возвращает следующую строку до символа новой строки:
line = file.readline()Если нужно считать все строки, можно воспользоваться методом readlines(), который вернет список строк:
lines = file.readlines()Важно закрыть файл после работы с ним, чтобы освободить ресурсы. Для этого используется метод close():
file.close()Для предотвращения забывания закрытия файла, можно использовать конструкцию with, которая автоматически закрывает файл после завершения работы с ним:
with open('example.txt', 'r') as file:
content = file.read()Этот способ делает код более безопасным и читабельным, а также исключает возможные утечки памяти.
Использование метода read() для извлечения содержимого файла
Метод read() в Python позволяет считывать содержимое текстового файла за один вызов, возвращая данные в виде строки. Этот метод применяется, когда нужно извлечь весь текст файла целиком, без необходимости построчного анализа.
Пример использования:
with open('example.txt', 'r') as file:
content = file.read()
Здесь используется контекстный менеджер with, что гарантирует автоматическое закрытие файла после завершения работы. Метод read() без параметров извлекает все содержимое файла, начиная с первого символа и до конца.
Если файл слишком большой, и вы хотите избежать излишнего потребления памяти, можно использовать параметр size в методе read(size). Этот параметр позволяет задать количество символов для чтения за один вызов, что полезно при работе с большими файлами.
with open('large_file.txt', 'r') as file:
chunk = file.read(1024) # Чтение 1024 символов
Также стоит помнить, что метод read() возвращает строку, и для работы с бинарными файлами следует открыть файл в режиме rb (read binary).
Если необходимо считывать данные по частям, можно использовать цикл:
with open('large_file.txt', 'r') as file:
while chunk := file.read(1024):
print(chunk)
Этот подход позволяет обрабатывать большие файлы без значительных затрат памяти, извлекая их по частям, что особенно полезно при работе с логами или данными, которые требуют постепенной обработки.
Чтение файла построчно с помощью метода readline()
Метод readline() в Python используется для чтения файла построчно. Он возвращает одну строку файла за раз, что удобно при обработке больших файлов, поскольку позволяет не загружать в память весь файл сразу. Это важно для работы с большими текстовыми данными, где объем памяти может быть ограничен.
Для чтения файла с помощью readline(), необходимо сначала открыть файл с помощью функции open(). После этого можно вызвать метод readline() в цикле, чтобы читать файл построчно.
Пример использования:
with open('example.txt', 'r') as file:
line = file.readline()
while line:
print(line.strip())
line = file.readline()
В данном примере файл открывается в режиме чтения 'r'. Метод readline() считывает одну строку, и цикл продолжается до тех пор, пока не будут прочитаны все строки файла. Важно заметить, что строка возвращается с символом новой строки в конце, который часто удаляют с помощью метода strip().
Метод readline() также позволяет задавать размер буфера, указывая параметр size. Например, можно прочитать строку не всю целиком, а ограниченную по длине:
line = file.readline(50) # Чтение только первых 50 символов строки
Этот способ полезен, если необходимо контролировать размер загружаемых данных и не допустить переполнения памяти при работе с очень большими строками.
Если файл содержит пустые строки, метод readline() вернет пустую строку, что следует учитывать при написании кода для обработки таких случаев.
Чтение всех строк файла в список с использованием readlines()

Метод `readlines()` в Python позволяет прочитать все строки из файла и вернуть их в виде списка. Каждая строка становится элементом этого списка, включая символы новой строки в конце каждой строки (если они присутствуют в файле). Этот метод удобно использовать, когда нужно обрабатывать файл построчно, сохраняя все строки для дальнейшей работы.
Пример использования:
with open('файл.txt', 'r') as file:
строки = file.readlines()
В этом примере файл ‘файл.txt’ открывается в режиме чтения, и его содержимое построчно считывается в список переменной `строки`. Каждая строка будет содержать символ новой строки в конце (например, «\n»), если в файле он присутствует.
Для удаления символов новой строки, можно использовать метод `strip()` для каждого элемента списка:
with open('файл.txt', 'r') as file:
строки = [line.strip() for line in file.readlines()]
Это удалит лишние символы новой строки, оставив только сам текст.
Метод `readlines()` полезен при обработке больших файлов, где необходимо работать с каждой строкой отдельно. Однако, для очень больших файлов, использование `readlines()` может привести к значительному потреблению памяти, так как весь файл загружается в память. В таких случаях лучше обрабатывать файл построчно, не загружая его целиком:
with open('файл.txt', 'r') as file:
for line in file:
# Обработка строки
Такой подход позволяет работать с большими файлами, избегая переполнения памяти.
Обработка ошибок при работе с текстовыми файлами в Python

При работе с текстовыми файлами в Python важно учитывать возможные ошибки, которые могут возникнуть на разных этапах: от открытия файла до его чтения и записи. Использование обработки ошибок позволяет сделать программу более стабильной и предотвращает её аварийное завершение. Рассмотрим ключевые моменты, которые следует учитывать при обработке ошибок.
Один из наиболее часто встречающихся типов ошибок – это ошибка открытия файла. При попытке открыть файл с использованием функции open() может возникнуть исключение FileNotFoundError, если файл не существует. В таком случае важно информировать пользователя о причине ошибки. Также стоит предусмотреть обработку ошибки доступа, например, если файл защищён от записи, или если программа не имеет прав для его открытия.
Для корректной обработки таких ошибок, рекомендуется использовать конструкцию try-except. В блоке except можно указать тип исключения, чтобы точно реагировать на конкретную проблему. Пример:
try:
file = open('data.txt', 'r')
except FileNotFoundError:
print("Файл не найден")
except PermissionError:
print("Нет прав на чтение файла")
Также следует учитывать ошибки, возникающие при чтении данных. Например, при попытке прочитать данные в неправильном формате может возникнуть исключение ValueError. Для защиты от подобных ситуаций полезно использовать дополнительные проверки перед чтением или записью данных.
Если работа с файлом завершена, важно правильно его закрывать, чтобы избежать утечек ресурсов. Для этого рекомендуется использовать конструкцию with, которая автоматически закрывает файл после завершения работы с ним, даже если возникло исключение. Например:
with open('data.txt', 'r') as file:
data = file.read()
Если необходимо записать данные в файл, важно обработать исключение IOError, которое может возникнуть, например, при попытке записи в файл, если он занят другим процессом. Также следует предусмотреть проверку доступности места на диске, чтобы избежать ошибок записи.
Важным аспектом является логирование ошибок. Для отладки и мониторинга работы программы можно использовать модуль logging, который позволяет записывать подробную информацию о возникших ошибках в отдельный файл журнала.
Таким образом, обработка ошибок при работе с текстовыми файлами в Python включает в себя правильное управление открытием файлов, проверку типов ошибок, использование контекстных менеджеров для автоматического закрытия файлов и логирование исключений для улучшения поддержки и диагностики ошибок в программе.
Чтение текстового файла с учётом кодировки
При чтении текстового файла в Python важно учитывать его кодировку, чтобы избежать ошибок в интерпретации символов. Файл может быть записан в различных кодировках, таких как UTF-8, Windows-1251, ISO-8859-1 и другие. Без правильного указания кодировки текст может быть искажен.
Для корректного чтения файла необходимо использовать параметр encoding в функции open(). Если кодировка не указана, Python использует кодировку по умолчанию, которая может не соответствовать реальной кодировке файла.
- Для UTF-8:
open('file.txt', 'r', encoding='utf-8') - Для Windows-1251:
open('file.txt', 'r', encoding='windows-1251') - Для ISO-8859-1:
open('file.txt', 'r', encoding='iso-8859-1')
Если кодировка файла неизвестна, можно попытаться использовать библиотеку chardet для её автоматического определения:
import chardet
with open('file.txt', 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
encoding = result['encoding']
with open('file.txt', 'r', encoding=encoding) as f:
text = f.read()Однако, использование chardet не всегда даёт 100% точность, особенно если текст содержит символы, которые могут быть интерпретированы несколькими кодировками.
Для файлов с нестандартной или малоизвестной кодировкой следует заранее уточнить её или запросить у источника данных, чтобы избежать ошибок.
При работе с большими файлами рекомендуется использовать контекстный менеджер with, который автоматически закроет файл после завершения работы:
with open('file.txt', 'r', encoding='utf-8') as f:
text = f.read()При чтении файлов с использованием разных кодировок, важно тестировать работу программы в различных окружениях, чтобы убедиться в корректности обработки символов, особенно если файл будет передаваться между различными операционными системами.
Импорт данных из файла с использованием библиотеки pandas

Часто для загрузки данных необходимо учитывать кодировку, разделители, а также возможность пропуска строк с ошибками или пустыми значениями. При работе с read_csv() можно указать различные параметры, такие как sep для указания разделителя, encoding для кодировки и header для выбора строки, которая будет заголовком.
Пример загрузки CSV файла с использованием pandas:
import pandas as pd
df = pd.read_csv('данные.csv', encoding='utf-8', sep=';', header=0)В данном примере encoding='utf-8' указывает на кодировку UTF-8, sep=';' означает, что разделителем является точка с запятой, а header=0 указывает на то, что первая строка файла будет заголовком.
Если файл содержит пропущенные данные или строки с ошибками, можно воспользоваться параметром error_bad_lines, чтобы пропускать такие строки:
df = pd.read_csv('данные.csv', error_bad_lines=False)Для загрузки данных из Excel используется pd.read_excel(), который поддерживает чтение нескольких листов. Если файл Excel имеет несколько листов, можно указать, какой лист нужно загрузить, через параметр sheet_name.
Пример загрузки данных из Excel:
df = pd.read_excel('данные.xlsx', sheet_name='Лист1')Если нужно загрузить все листы, параметр sheet_name можно установить в значение None, что вернёт словарь, где ключами будут имена листов:
df = pd.read_excel('данные.xlsx', sheet_name=None)Важной особенностью работы с pandas является возможность использовать read_csv() и read_excel() не только для загрузки структурированных данных, но и для их предварительной обработки во время импорта, например, выбора нужных столбцов с помощью параметра usecols или фильтрации строк с помощью skiprows.
Кроме того, pandas поддерживает работу с файлами различных форматов, включая JSON, Parquet и HDF5, что позволяет использовать одну и ту же библиотеку для широкого спектра задач по загрузке и обработке данных.





