Работа с данными в формате CSV является обычной практикой при обработке больших объемов информации. Однако, часто такие файлы содержат лишние пробелы, пустые строки или некорректные значения, что затрудняет их дальнейшую обработку. Python предлагает несколько эффективных инструментов для очистки CSV-файлов. В этом руководстве рассмотрим, как с помощью Python можно быстро устранить такие проблемы, как удаление лишних строк, замена пропусков и приведение данных к нужному формату.
Первым шагом будет использование библиотеки pandas, которая предоставляет мощные функции для работы с таблицами и данными. Один из основных методов для работы с CSV – это read_csv(), который позволяет загрузить данные в DataFrame. После загрузки можно применить различные фильтры, такие как удаление строк с пропущенными значениями с помощью метода dropna() или удаление дубликатов с помощью drop_duplicates().
Для более детальной очистки можно использовать регулярные выражения. Например, если нужно удалить строки с неправильными форматами данных, используйте метод str.contains(), чтобы фильтровать строки по определенному шаблону. Также стоит помнить о том, что часто в CSV-файлах встречаются неожиданные символы, которые могут быть удалены с помощью метода replace().
Подготовка данных: удаление лишних строк и столбцов
Удаление ненужных строк и столбцов – важный этап в процессе очистки CSV-файлов. В Python для работы с такими данными часто используется библиотека pandas. Ниже рассмотрены основные шаги для удаления ненужных элементов.
- Удаление пустых строк: Пустые строки могут встречаться в файле по разным причинам. Для их удаления используйте метод
dropna():
import pandas as pd
df = pd.read_csv('data.csv')
df_cleaned = df.dropna(how='all') # Удаление строк, где все значения пустые
- Удаление строк по индексу: Иногда нужно удалить конкретные строки по индексам. Это можно сделать с помощью метода
drop():
df_cleaned = df.drop([0, 2, 5]) # Удаление строк с индексами 0, 2 и 5
- Удаление столбцов: Для удаления лишних столбцов используйте параметр
axis=1в методеdrop():
df_cleaned = df.drop(['column1', 'column2'], axis=1) # Удаление столбцов 'column1' и 'column2'
- Удаление столбцов с пустыми значениями: Столбцы, содержащие пустые значения, могут быть удалены с помощью метода
dropna()с параметромaxis=1:
df_cleaned = df.dropna(axis=1, how='all') # Удаление столбцов, где все значения пустые
- Удаление столбцов с избыточной информацией: Если в файле есть столбцы, не содержащие значимой информации, их можно исключить вручную, например, при помощи метода
drop()или путем фильтрации по названию:
df_cleaned = df[['column3', 'column4']] # Оставление только столбцов 'column3' и 'column4'
Эти методы позволяют быстро и эффективно избавляться от лишних данных, оставляя только нужную информацию для дальнейшей работы.
Поиск и удаление дубликатов в csv файле
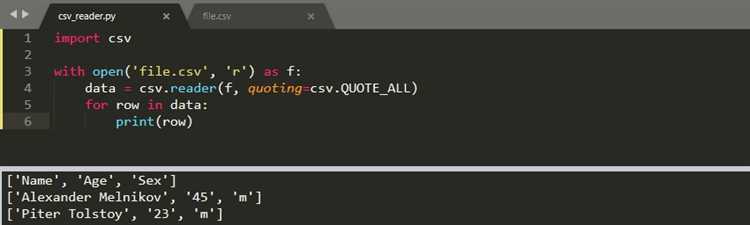
Чтобы найти дубликаты, достаточно загрузить данные в DataFrame и применить метод duplicated(). Этот метод возвращает серию булевых значений, где True означает дубликат. Например:
import pandas as pd
df = pd.read_csv('file.csv')
duplicates = df[df.duplicated()]
print(duplicates)Этот код выведет все строки, которые повторяются в исходном файле. По умолчанию duplicated() ищет дубликаты по всем столбцам. Если нужно проверять только несколько столбцов, передайте их список в параметр subset. Например:
duplicates = df[df.duplicated(subset=['column1', 'column2'])]
print(duplicates)Для удаления дубликатов можно воспользоваться методом drop_duplicates(). Он удаляет все строки, которые являются повторяющимися, оставляя только первую встреченную запись. Для этого используйте следующий код:
df_cleaned = df.drop_duplicates()
df_cleaned.to_csv('cleaned_file.csv', index=False)Если нужно удалить дубликаты, оставив последнюю запись, передайте параметр keep='last':
df_cleaned = df.drop_duplicates(keep='last')
df_cleaned.to_csv('cleaned_file.csv', index=False)Если необходимо удалить все дублирующиеся строки, а не только одну из них, используйте keep=False:
df_cleaned = df.drop_duplicates(keep=False)
df_cleaned.to_csv('cleaned_file.csv', index=False)Таким образом, поиск и удаление дубликатов с помощью pandas – это быстрый и эффективный способ очистки данных. Вы можете настроить параметры методов, чтобы точно контролировать, какие строки будут удалены.
Использование pandas для работы с пропущенными значениями
При обработке CSV файлов с помощью pandas часто встречаются пропущенные значения. Для их эффективного удаления или замены используется несколько методов, которые позволяют быстро подготовить данные для анализа.
Основной метод для поиска пропущенных значений – это функция isnull(). Она возвращает DataFrame с булевыми значениями, где True означает наличие пропущенного значения. Пример:
df.isnull()Для подсчета количества пропущенных значений в каждом столбце можно воспользоваться sum(), который суммирует булевы значения:
df.isnull().sum()Когда нужно удалить строки с пропущенными значениями, используется метод dropna(). Этот метод по умолчанию удаляет все строки, содержащие хотя бы одно пропущенное значение. Для удаления столбцов с пропущенными значениями применяется параметр axis=1:
df.dropna(axis=0, inplace=True) # Удаление строк
df.dropna(axis=1, inplace=True) # Удаление столбцовЕсли нужно заменить пропущенные значения, например, на среднее значение в столбце, используется метод fillna(). Для числовых данных часто применяют медиану или среднее:
df.fillna(df.mean(), inplace=True) # Заменить на среднееДля строковых столбцов разумно использовать наиболее часто встречающееся значение (моду):
df['column_name'].fillna(df['column_name'].mode()[0], inplace=True)Если требуется заменить пропущенные значения на значение, вычисленное на основе других столбцов, можно использовать функцию apply(), которая позволяет применить произвольную логику для заполнения пропусков.
Для более сложных сценариев можно использовать параметр method в fillna(), чтобы заполнить пропуски значениями, используя метод интерполяции. Например, линейная интерполяция заполняет пропуски на основе соседних значений:
df.interpolate(method='linear', inplace=True)В процессе очистки данных важно учитывать контекст данных и выбирать наиболее подходящий способ обработки пропусков в зависимости от задачи. Удаление строк или столбцов с пропущенными значениями может быть неприемлемо, если таких значений слишком много. В таких случаях заполнение пропусков на основе статистических методов или интерполяции является более разумным выбором.
Корректировка типов данных в столбцах csv файла

При работе с csv файлами важно убедиться, что каждый столбец имеет корректный тип данных, поскольку это влияет на производительность обработки и точность анализа. Например, столбцы с числами могут быть неправильно интерпретированы как строки. В Python для этого можно использовать библиотеку pandas.
Для корректировки типов данных столбцов используйте метод astype(). Он позволяет явно указать тип данных для каждого столбца.
df['column_name'] = df['column_name'].astype('тип данных')
Для числовых столбцов лучше использовать типы данных int или float, а для строковых данных – str. Для дат и времени можно использовать pd.to_datetime().
df['date_column'] = pd.to_datetime(df['date_column'])df['numeric_column'] = df['numeric_column'].astype('float')df['text_column'] = df['text_column'].astype('str')
Если столбец содержит значения, которые могут быть интерпретированы как различные типы, предварительно примените pd.to_numeric() с параметром errors='coerce', чтобы преобразовать некорректные данные в NaN:
df['numeric_column'] = pd.to_numeric(df['numeric_column'], errors='coerce')
После корректировки типов данных полезно проверить, что столбцы имеют нужный формат. Для этого можно использовать метод dtypes, который покажет тип данных каждого столбца:
print(df.dtypes)
Если тип данных не соответствует ожиданиям, можно повторить преобразование или удалить строки с ошибочными значениями с помощью dropna().
df = df.dropna(subset=['numeric_column'])
Для улучшения точности данных часто используют стандартные типы, такие как float32 вместо float64, чтобы экономить память и ускорить обработку.
Приведение текста в столбцах к единому формату
Когда данные содержат текстовую информацию, важно привести её к единому формату, чтобы избежать ошибок при анализе. В Python для этого можно использовать несколько полезных методов.
Первый шаг – это приведение текста к единому регистру. Обычно для обработки текста используется нижний регистр, чтобы избежать различий между строками вроде «python» и «Python». Для этого можно использовать метод str.lower(). Пример:
df['column_name'] = df['column_name'].str.lower()Также полезно удалить лишние пробелы в начале и в конце строк. Это можно сделать с помощью метода str.strip(), который удалит все пробелы и невидимые символы.
df['column_name'] = df['column_name'].str.strip()Если данные содержат символы, которые не нужны, например, спецсимволы или знаки пунктуации, их можно удалить с помощью регулярных выражений. Для этого используется метод str.replace(), либо можно воспользоваться re.sub() для более сложных операций. Пример для удаления всех цифр:
df['column_name'] = df['column_name'].str.replace(r'\d+', '')Ещё одной важной операцией является стандартизация различных вариантов написания одинаковых слов. Например, может встречаться несколько вариантов написания месяца («январь» и «Январь»). Для приведения к единому виду можно использовать метод str.capitalize() или str.title() для заглавных букв в словах.
df['column_name'] = df['column_name'].str.title()Если данные содержат опечатки или сокращения, рекомендуется составить список замен и применить его с помощью метода replace() или регулярных выражений. Например, заменить «млн» на «миллион»:
df['column_name'] = df['column_name'].replace({'млн': 'миллион'})Кроме того, полезно привести все текстовые данные к единому стилю в зависимости от контекста, например, использовать только кириллицу, если в данных могут быть латинские буквы. Для этого также можно использовать регулярные выражения или методы, такие как str.encode('ascii', 'ignore') для удаления не-ASCII символов.
Удаление или исправление некорректных значений
Для работы с некорректными данными в CSV файле в Python часто используется библиотека pandas. Если в столбцах встречаются пустые ячейки, дублирующиеся записи или значения, выходящие за допустимые пределы, их нужно обработать.
Чтобы удалить строки с пустыми значениями, можно воспользоваться методом dropna(). Это удалит все строки, где хотя бы одно значение отсутствует:
import pandas as pd
df = pd.read_csv('file.csv')
df = df.dropna()Если необходимо только удалить строки с пустыми значениями в определённых столбцах, укажите их в параметре subset:
df = df.dropna(subset=['column1', 'column2'])Для исправления некорректных данных можно использовать метод fillna(), чтобы заполнить пропущенные значения. Пример замены всех пропусков на нули:
df = df.fillna(0)Если значения выходят за допустимые границы (например, возраст больше 120 лет), можно применить фильтрацию:
df = df[df['age'] <= 120]Для обнаружения и удаления дублированных записей используется метод drop_duplicates(), который удаляет все строки, повторяющиеся по всем столбцам:
df = df.drop_duplicates()Если дубли нужно удалить только по определённым столбцам, это можно сделать так:
df = df.drop_duplicates(subset=['column1', 'column2'])Также, если в данных встречаются ошибки ввода, их можно заменить, например, с помощью replace(). Это полезно, когда требуется заменить текстовое значение на числовое или наоборот:
df['column'] = df['column'].replace({'old_value': 'new_value'})Экспорт очищенных данных в новый csv файл
Если вы используете csv, процесс экспорта заключается в открытии нового файла для записи и использовании метода writerow() для записи каждой строки. Пример:
import csv
# Данные после очистки
cleaned_data = [["Имя", "Возраст"], ["Иван", 30], ["Мария", 25]]
# Открытие нового файла для записи
with open('cleaned_data.csv', mode='w', newline='') as file:
writer = csv.writer(file)
# Запись строк в файл
writer.writerows(cleaned_data)
Для использования pandas процесс будет проще. Библиотека поддерживает метод to_csv(), который автоматически сохраняет данные в файл:
import pandas as pd
# Создание DataFrame из очищенных данных
cleaned_data = pd.DataFrame([["Иван", 30], ["Мария", 25]], columns=["Имя", "Возраст"])
# Экспорт в CSV файл
cleaned_data.to_csv('cleaned_data.csv', index=False)
При использовании pandas стоит обратить внимание на параметр index=False, который исключает добавление индекса в файл, если он не требуется. Это поможет сохранить чистоту данных без лишних столбцов.
В случае, если необходимо экспортировать данные с учётом специфических настроек (например, определённого разделителя или кодировки), в csv и pandas есть параметры, которые позволяют настроить форматирование. В csv можно указать параметр delimiter, а в pandas – sep и encoding.
Пример использования pandas с указанием кодировки:
cleaned_data.to_csv('cleaned_data.csv', index=False, encoding='utf-8')
После успешного экспорта рекомендуется проверять новый файл, чтобы убедиться, что все данные корректно сохранены, и нет посторонних символов или ошибок в форматировании.
Вопрос-ответ:
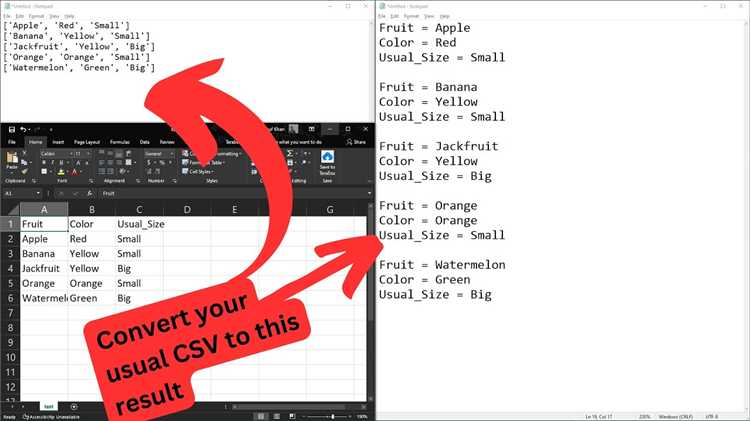
Как очистить CSV файл от лишних пробелов и пустых строк в Python?
Для того чтобы удалить лишние пробелы и пустые строки в CSV файле, можно использовать библиотеку `pandas`. Сначала нужно загрузить файл в DataFrame с помощью `pandas.read_csv()`. Затем можно использовать метод `dropna()` для удаления строк с пустыми значениями и `str.strip()` для очистки строк от лишних пробелов. Например:
Как удалить повторяющиеся строки из CSV файла?
Чтобы удалить повторяющиеся строки в CSV файле, можно воспользоваться методом `drop_duplicates()` библиотеки `pandas`. Он автоматически удаляет все дубликаты, оставляя только уникальные строки. Пример кода:
Каким образом можно преобразовать данные в CSV файле, чтобы все строки в колонке имели одинаковый формат?
Для приведения данных в одной колонке к единому формату можно использовать метод `apply()` с функцией для преобразования значений. Например, если нужно привести все значения в колонке к нижнему регистру, можно сделать так:
Как обработать ошибки, если в CSV файле есть некорректные данные или неправильный формат?
Если в CSV файле встречаются некорректные данные или ошибки формата, можно использовать параметр `error_bad_lines=False` при чтении файла через `pandas.read_csv()`, чтобы игнорировать строки с ошибками. Также можно применить функцию для обработки ошибок в каждой строке с помощью `try-except`, чтобы выявить и корректировать некорректные данные.
Как очистить CSV файл от ненужных символов, таких как спецсимволы или знаки?
Для удаления спецсимволов из строк в CSV файле можно использовать метод `str.replace()` в pandas. Например, чтобы удалить все ненужные символы, можно использовать регулярное выражение. Пример кода: