В задачах предобработки текста часто требуется оставить в строке только буквы, исключив цифры, знаки препинания, пробелы и другие символы. В Python для этого удобно использовать регулярные выражения из модуля re. Они позволяют задать чёткое правило фильтрации символов и легко адаптируются под разные языки и алфавиты.
Чтобы оставить только буквы латинского алфавита, используется шаблон [A-Za-z]. Для работы с кириллицей – [А-Яа-яЁё]. Чтобы обрабатывать оба алфавита одновременно, шаблон можно объединить: [A-Za-zА-Яа-яЁё]. Пример удаления лишнего: re.sub(r'[^A-Za-zА-Яа-яЁё]', '', text).
Если строка содержит символы юникода за пределами основных диапазонов, важно указать флаг re.UNICODE и использовать конструкцию \p{L} через модуль regex (альтернатива re): regex.sub(r'[^\p{L}]', '', text). Это обеспечит поддержку всех буквенных символов вне зависимости от языка.
Ручная фильтрация через str.isalpha() подходит для небольших строк: ''.join(c for c in text if c.isalpha()). Этот метод работает медленнее на больших объемах текста, но не требует дополнительных модулей и легко читается.
Выбор подхода зависит от объема данных, требований к производительности и языковой специфики. Для универсальности и масштабируемости предпочтительнее использовать регулярные выражения.
Как удалить все символы кроме латинских букв из строки
Для извлечения только латинских букв из строки в Python используйте регулярные выражения. Это обеспечивает высокую точность и скорость обработки.
- Импортируйте модуль
re. - Используйте шаблон
[^a-zA-Z]для поиска всех символов, не являющихся латинскими буквами. - Примените функцию
re.subдля замены ненужных символов на пустую строку.
import re
text = "Hello, мир! 123 @#%"
only_latin = re.sub(r'[^a-zA-Z]', '', text)
Шаблон [^a-zA-Z] означает «все, кроме букв от a до z и от A до Z». Он удаляет пробелы, цифры, кириллицу, знаки препинания и спецсимволы. Если важно сохранить регистр, дополнительной обработки не требуется. Для приведения к нижнему или верхнему регистру используйте .lower() или .upper() соответственно.
text.lower()– приводит строку к нижнему регистру.text.upper()– приводит строку к верхнему регистру.
Этот подход универсален и применим к любым строкам, включая данные из внешних источников, пользовательский ввод и текстовые файлы.
Как сохранить только кириллические буквы в строке

Для извлечения исключительно кириллических символов из строки в Python используется регулярное выражение r'[а-яА-ЯёЁ]+’. Модуль re обеспечивает необходимую функциональность. Пример:
import re
строка = "Текст123 с разными символами!@#"
результат = ''.join(re.findall(r'[а-яА-ЯёЁ]+', строка))
print(результат) # Текстсразнымисимволами
Регулярное выражение охватывает как строчные, так и заглавные буквы, включая букву ё. Символы других алфавитов, цифры и знаки препинания автоматически исключаются. Для работы с юникодом не требуется дополнительных флагов, так как Python 3 по умолчанию поддерживает юникод-строки.
Если строка может содержать символы, визуально схожие с кириллицей, но относящиеся к другому диапазону Unicode (например, латинские «а», «е»), используйте unicodedata.name() для фильтрации по имени символа:
import unicodedata
строка = "Теxt с латинскими a и e"
результат = ''.join(
c for c in строка
if 'CYRILLIC' in unicodedata.name(c, '')
)
print(результат) # Тс
Этот подход исключает латиницу, даже если она визуально совпадает с кириллицей. Полезен при обработке данных, полученных из ненадёжных источников.
Удаление всех не-буквенных символов с помощью регулярных выражений
Для удаления всех символов, не являющихся буквами, используется модуль re и шаблон [^a-zA-Zа-яА-ЯёЁ]. Он охватывает как латинский, так и кириллический алфавит, включая букву «ё».
Пример использования:
import re
строка = "Пример: строка с цифрами 123 и символами!@#"
только_буквы = re.sub(r"[^a-zA-Zа-яА-ЯёЁ]", "", строка)
Если требуется сохранить пробелы между словами, добавляется символ пробела в шаблон: [^a-zA-Zа-яА-ЯёЁ ].
Регулярные выражения обрабатывают строку за один проход, что делает метод эффективным даже при работе с большими текстами. Предпочтительнее избегать методов, основанных на посимвольной фильтрации – они медленнее и менее читаемы.
Для учета регистра преобразование строки к нижнему или верхнему регистру следует выполнять до очистки, если задача это требует.
Обработка строк с буквами из разных алфавитов одновременно

Для удаления всех символов, кроме букв, в строках с буквами из разных алфавитов (например, латиницы и кириллицы), необходимо использовать регулярные выражения с поддержкой Unicode. Модуль re в Python позволяет задать соответствующее поведение через флаг re.UNICODE, однако по умолчанию в Python 3 он уже активен.
Чтобы сохранить только буквенные символы всех алфавитов, следует использовать класс символов \p{L} из стандарта Unicode. Однако стандартный модуль re не поддерживает синтаксис \p{...}, поэтому нужно использовать стороннюю библиотеку regex (устанавливается через pip install regex).
Пример кода: import regex as re
text = "Пример: example123! مثال؟"
result = re.sub(r"[^\p{L}]", "", text)
print(result)
Этот код удалит все символы, кроме букв из любых алфавитов, включая арабский, латинский, кириллический и другие. Для ускорения обработки при больших объемах данных рекомендуется предварительно нормализовать строку с помощью unicodedata.normalize, чтобы избавиться от составных символов и привести все буквы к одной форме.
Если необходимо сохранить пробелы между словами на разных языках, можно заменить регулярное выражение на [^\p{L}\s]. Это позволяет сохранить читаемость текста при одновременной очистке от нежелательных символов.
Удаление всех символов кроме букв без использования регулярных выражений

Для очистки строки от всех символов, кроме букв, без применения модуля re, можно воспользоваться методом перебора символов с последующей фильтрацией. Это даёт полный контроль над логикой обработки и позволяет исключить использование сторонних инструментов.
Ключевой инструмент – встроенный метод isalpha(), который возвращает True только для буквенных символов. Он охватывает символы латинского и кириллического алфавитов, а также поддерживает символы других языков, если они определены в Unicode как буквы.
Пример реализации:
def keep_only_letters(s):
return ''.join(c for c in s if c.isalpha())
# Пример использования
original = "Текст123! с лишними #символами."
cleaned = keep_only_letters(original)
print(cleaned) # Текстслишнимисимволами
Этот подход устойчив к ошибкам: isalpha() не требует дополнительных проверок и корректно работает с любыми строками, включая пустые. Также он не удаляет пробелы по умолчанию, если они нужны – их можно обработать отдельно.
Для повышения читаемости при сохранении слов можно модифицировать логику:
def keep_letters_and_spaces(s):
return ''.join(c for c in s if c.isalpha() or c == ' ')
Такой метод предпочтителен в случаях, когда необходимо сохранить разделение слов при удалении всех лишних символов.
Как удалить все символы кроме букв в списке строк
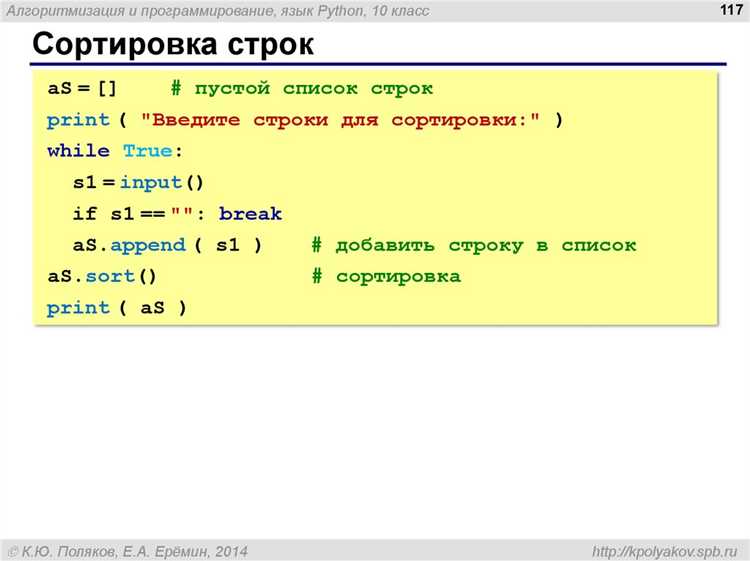
Для удаления всех символов кроме букв в списке строк можно воспользоваться регулярными выражениями с помощью модуля re. Регулярные выражения позволяют задать паттерн, который будет искать все символы, соответствующие буквам, и исключать остальные.
Основная цель – пройти по каждому элементу списка, применяя регулярное выражение, которое заменяет все символы, не являющиеся буквами, на пустую строку.
Пример реализации:
import re
def remove_non_alpha(strings):
return [re.sub(r'[^a-zA-Zа-яА-ЯёЁ]', '', s) for s in strings]
strings = ['Привет, мир!', 'Hello123', 'Python@2025']
cleaned_strings = remove_non_alpha(strings)
print(cleaned_strings)В этом примере используется регулярное выражение [^a-zA-Zа-яА-ЯёЁ], которое находит все символы, не являющиеся буквами латинского или кириллического алфавита, включая букву «ё». Эти символы затем заменяются на пустую строку.
Если необходимо поддерживать только латинские или только кириллические буквы, регулярное выражение можно адаптировать. Например, для исключения всех символов кроме латинских букв, регулярное выражение будет [^a-zA-Z].
Этот подход работает эффективно для строк, содержащих любые ненужные символы, и может быть адаптирован для более сложных случаев, например, для обработки пробелов, знаков препинания или цифр.
Вопрос-ответ:
Как удалить все символы, кроме букв, из строки в Python?
Для удаления всех символов, кроме букв, можно использовать регулярные выражения. Пример: `re.sub(‘[^a-zA-Z]’, », your_string)`. Этот код удаляет все символы, которые не являются буквами английского алфавита. Если нужно учесть буквы других языков, например, кириллицу, регулярное выражение можно расширить: `re.sub(‘[^a-zA-Zа-яА-Я]’, », your_string)`. Это регулярное выражение удаляет все символы, кроме латинских и кириллических букв.
Почему для удаления символов, кроме букв, используется регулярное выражение?
Регулярные выражения — мощный инструмент для поиска и замены шаблонов в строках. Они позволяют быстро и эффективно находить нужные символы и заменять их на другие или удалять. В случае удаления всех символов, кроме букв, регулярное выражение помогает точно указать, какие символы должны остаться (в данном случае буквы), а какие нужно удалить, что делает процесс обработки строки простым и понятным.
Можно ли удалить символы, кроме букв, без использования регулярных выражений?
Да, можно. Например, можно использовать функцию `isalpha()`, которая проверяет, является ли символ буквой. Пример кода: `».join([char for char in your_string if char.isalpha()])`. Этот код создает новую строку, включая только те символы, которые являются буквами. Такой подход не требует использования регулярных выражений и подходит для простых задач.
Как удалить все символы, кроме букв, если строка содержит символы в разных регистрах?
Для учета символов в разных регистрах можно использовать тот же подход с регулярными выражениями, не ограничиваясь только латинскими буквами. Пример: `re.sub(‘[^a-zA-Zа-яА-Я]’, », your_string)`. Это регулярное выражение будет удалять все символы, кроме букв как латинского, так и кириллического алфавита, независимо от их регистра. Если нужно учитывать только один язык, можно модифицировать шаблон под конкретные буквы.
Какие могут быть альтернативы регулярным выражениям для удаления символов из строки в Python?
Кроме использования регулярных выражений, можно использовать другие методы для удаления символов. Например, метод `str.translate()` в сочетании с таблицей перевода может быть полезен для удаления нежелательных символов. Пример: `your_string.translate(str.maketrans(», », ‘0123456789!@#$%^&*’))`. В этом примере удаляются все цифры и спецсимволы из строки. Такой подход может быть полезен, если список символов для удаления заранее известен.