Модуль csv входит в стандартную библиотеку Python и предоставляет минималистичный, но надёжный инструмент для чтения и записи данных в формате CSV. Этот формат используется в электронных таблицах, базах данных и при передаче структурированных данных между системами. В отличие от библиотек вроде pandas, модуль csv не требует дополнительных зависимостей и подходит для обработки файлов с небольшим объёмом данных или низким уровнем вложенности.
Файл CSV можно открыть в режиме чтения с помощью встроенной функции open(), передав путь к файлу и режим ‘r’. При этом необходимо указать newline=» для корректной обработки переноса строк, особенно в Windows. После открытия файла объект передаётся в csv.reader(), который возвращает итератор по строкам, представленных в виде списков.
Модуль поддерживает настройку разделителя, символов кавычек, способа экранирования. Например, если данные разделены точкой с запятой, нужно указать delimiter=’;’. При наличии строк с вложенными кавычками полезно установить quotechar='»‘ и escapechar=’\\’. Это особенно важно при работе с экспортированными данными из Excel или LibreOffice, где могут встречаться нестандартные варианты форматирования.
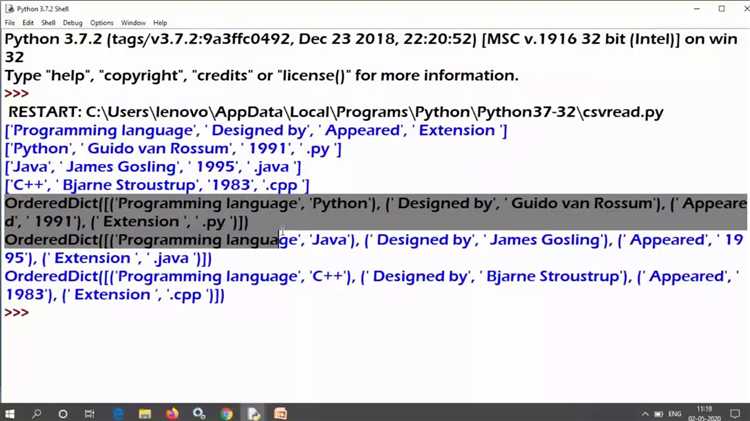
Для пропуска заголовков удобно использовать next(reader) до начала итерации. Если требуется доступ по имени столбца, следует использовать csv.DictReader, который возвращает строки в виде словарей. Это упрощает дальнейшую обработку и повышает читаемость кода.
Работа с модулем csv не требует загрузки в память всего файла, поэтому он подходит для построчной обработки больших файлов без риска превышения объёма оперативной памяти. При этом необходимо учитывать, что модуль не производит автоматическую проверку типов данных – все значения читаются как строки и требуют дополнительного преобразования при необходимости.
Как открыть CSV файл и прочитать строки построчно

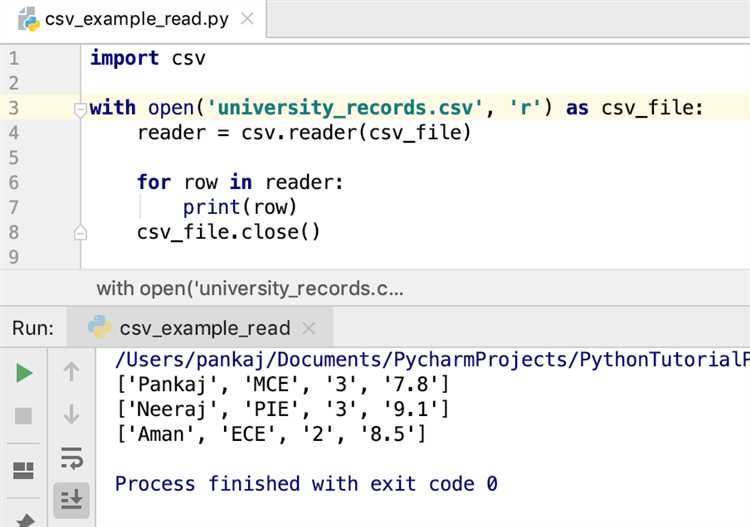
Для чтения CSV-файлов используется модуль csv, входящий в стандартную библиотеку Python. Основной способ – использовать функцию csv.reader() с файловым объектом.
- Импортируйте модуль:
import csv - Откройте файл с указанием кодировки. Для файлов в UTF-8 чаще всего достаточно:
with open('данные.csv', 'r', encoding='utf-8') as файл: - Создайте объект чтения:
читатель = csv.reader(файл) - Итерируйтесь по строкам:
for строка in читатель: print(строка)
Каждая строка возвращается в виде списка: элементы соответствуют значениям, разделённым запятой (или другим символом-разделителем, если указан явно).
- Чтобы указать разделитель, используйте параметр
delimiter:csv.reader(файл, delimiter=';') - Пустые строки не пропускаются автоматически. Проверяйте
if строка, если нужно исключить их вручную. - Заголовки не обрабатываются отдельно. Если они есть, их можно считать отдельно:
заголовок = next(читатель)
Работа с csv.reader подходит для последовательной построчной обработки, особенно при больших объёмах данных.
Как обрабатывать заголовки столбцов в CSV файле
При чтении CSV файлов с заголовками удобно использовать csv.DictReader. Он автоматически использует первую строку как имена ключей для словарей:
import csv
with open('данные.csv', encoding='utf-8') as файл:
читатель = csv.DictReader(файл)
for строка in читатель:
print(строка['Имя'])Чтобы задать свои заголовки, передайте список в параметр fieldnames:
с заголовками = ['Имя', 'Возраст', 'Город']
with open('данные.csv', encoding='utf-8') as файл:
читатель = csv.DictReader(файл, fieldnames=с заголовками)
next(читатель) # пропустить первую строку с ненужными заголовками
for строка in читатель:
print(строка['Город'])Если требуется сохранить порядок столбцов, используйте OrderedDict:
from collections import OrderedDict
with open('данные.csv', encoding='utf-8') as файл:
читатель = csv.DictReader(файл, dict_class=OrderedDict)
for строка in читатель:
print(list(строка.keys()))Для проверки наличия всех ожидаемых заголовков используйте множество:
ожидаемые = {'Имя', 'Возраст', 'Город'}
with open('данные.csv', encoding='utf-8') as файл:
читатель = csv.DictReader(файл)
if not ожидаемые.issubset(читатель.fieldnames):
raise ValueError('Некоторые заголовки отсутствуют')Чтобы переименовать заголовки, можно изменить fieldnames после создания объекта:
сопоставление = {'Name': 'Имя', 'Age': 'Возраст'}
with open('данные.csv', encoding='utf-8') as файл:
читатель = csv.DictReader(файл)
читатель.fieldnames = [сопоставление.get(н, н) for н in читатель.fieldnames]
for строка in читатель:
print(строка['Имя'])Для очистки заголовков от пробелов и невидимых символов используйте генератор:
with open('данные.csv', encoding='utf-8') as файл:
читатель = csv.reader(файл)
заголовки = [з.strip() for з in next(читатель)]
for строка in читатель:
данные = dict(zip(заголовки, строка))
print(данные)Чем отличается csv.reader от csv.DictReader
Функция csv.reader считывает строки CSV-файла как списки. Каждый элемент списка соответствует отдельной ячейке. Порядок полей важен, но названия столбцов игнорируются. При работе с этим вариантом необходимо самостоятельно следить за индексами и структурой данных.
csv.DictReader возвращает каждую строку в виде словаря, где ключи берутся из первой строки файла (заголовка). Это позволяет обращаться к данным по имени столбца, а не по позиции. Удобно, если структура CSV известна, но порядок полей может меняться.
DictReader автоматически пропускает заголовок. В reader заголовок читается как обычная строка и его нужно обрабатывать вручную. При отсутствии заголовка DictReader можно передать список названий полей через параметр fieldnames.
При использовании DictReader значения всегда возвращаются как строки, даже если поле пустое – в отличие от reader, где можно настроить последующую обработку списков в любой форме.
Если требуется максимальная скорость и структура данных известна заранее – reader предпочтительнее. При работе с нефиксированными полями и акценте на читаемость – DictReader удобнее.
Как задать нестандартный разделитель в CSV файле
По умолчанию модуль csv в Python использует запятую как разделитель. Чтобы задать другой символ, нужно указать параметр delimiter при создании объекта reader или writer.
Пример чтения CSV-файла, где поля разделены точкой с запятой:
import csv
with open('данные.csv', newline='', encoding='utf-8') as файл:
чтение = csv.reader(файл, delimiter=';')
for строка in чтение:
print(строка)
Аналогично, при записи файла с вертикальной чертой в качестве разделителя:
import csv
данные = [['Имя', 'Возраст'], ['Анна', '29'], ['Игорь', '34']]
with open('результат.csv', 'w', newline='', encoding='utf-8') as файл:
запись = csv.writer(файл, delimiter='|')
запись.writerows(данные)
Важно избегать конфликта символа-разделителя с содержимым ячеек. Если предполагается наличие разделителя в данных, используйте параметр quotechar для ограничения полей, например quotechar='»‘.
Как обрабатывать пустые строки и пропуски в данных
При чтении CSV-файлов с помощью модуля csv часто встречаются строки, содержащие только разделители, или ячейки без значений. Такие пропуски могут повлиять на обработку данных и вызвать ошибки при последующем анализе.
Чтобы игнорировать полностью пустые строки, используйте параметр skipinitialspace=True и предварительную фильтрацию итератора:
import csv
with open('данные.csv', newline='', encoding='utf-8') as f:
reader = csv.reader(f, skipinitialspace=True)
rows = [row for row in reader if any(cell.strip() for cell in row)]
Если необходимо обрабатывать пропущенные значения в отдельных ячейках, рекомендуется проверять каждую строку вручную и заменять '' на нужное значение или None:
обработанные_данные = []
with open('данные.csv', newline='', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
обработанные_данные.append([cell if cell.strip() else None for cell in row])
Для файлов с заголовками используйте csv.DictReader, чтобы обращаться к значениям по ключу. Это упростит проверку и замену пропущенных значений:
with open('данные.csv', newline='', encoding='utf-8') as f:
reader = csv.DictReader(f)
данные = []
for row in reader:
очищенная_строка = {ключ: (значение if значение.strip() else None) for ключ, значение in row.items()}
данные.append(очищенная_строка)
Если необходимо удалить строки, где пропущены значения в критически важных столбцах:
важные_поля = ['id', 'дата']
очищенные_данные = []
with open('данные.csv', newline='', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
if all(row[поле].strip() for поле in важные_поля):
очищенные_данные.append(row)
Такой подход позволяет сохранить только те строки, где все ключевые данные присутствуют.
Как читать CSV файл с кодировкой UTF-8 и Windows-1251
При работе с CSV файлами часто возникает необходимость учитывать кодировку файла. В Python для этого используется модуль csv, который позволяет легко обрабатывать данные в различных кодировках, таких как UTF-8 и Windows-1251. Рассмотрим, как правильно читать файлы в этих кодировках.
Чтение файла с кодировкой UTF-8
Для чтения CSV файла с кодировкой UTF-8, необходимо явно указать эту кодировку при открытии файла. Это гарантирует правильную обработку всех символов, включая специальные и неанглийские символы.
import csv
with open('file_utf8.csv', mode='r', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)Чтение файла с кодировкой Windows-1251
Файлы с кодировкой Windows-1251 часто встречаются при работе с данными на русском языке. Для их правильного чтения нужно указать кодировку windows-1251.
with open('file_windows_1251.csv', mode='r', encoding='windows-1251') as file:
reader = csv.reader(file)
for row in reader:
print(row)Этот пример аналогичен предыдущему, но используется другая кодировка для правильного чтения русских символов.
Проблемы с кодировками
- Ошибка «UnicodeDecodeError»: возникает, если файл открыт с неправильной кодировкой. В таком случае, нужно проверить кодировку файла и указать верную при его открытии.
- Проблемы с отображением символов: если кодировка не совпадает с фактической, вместо русских букв могут появляться знаки вопроса или другие непонятные символы. В таком случае, стоит попробовать другие кодировки, такие как
utf-16илиlatin1.
Использование автоматического определения кодировки
Для того чтобы не указывать вручную кодировку, можно использовать библиотеку chardet, которая автоматически определит кодировку файла.
import chardet
with open('file.csv', 'rb') as file:
raw_data = file.read(10000) # читаем часть файла
result = chardet.detect(raw_data)
encoding = result['encoding']
with open('file.csv', mode='r', encoding=encoding) as file:
reader = csv.reader(file)
for row in reader:
print(row)Этот код автоматически определит кодировку и откроет файл с правильными параметрами.
Как безопасно закрыть файл после чтения
После работы с файлом его необходимо закрыть, чтобы освободить ресурсы и избежать возможных ошибок в будущем. В Python для этого используется метод close(), который завершает работу с файлом и закрывает его.
Самый безопасный способ закрытия файла – использовать конструкцию with. Это гарантирует, что файл будет закрыт автоматически, даже если возникнет ошибка во время работы с ним. Пример:
with open('data.csv', 'r') as file:
reader = csv.reader(file)
for row in reader:
print(row)
В этом случае, когда блок with завершается, файл закрывается автоматически, независимо от того, произошло ли исключение или нет.
Использование явного вызова file.close() также эффективно, но требует дополнительного внимания, чтобы не забыть закрыть файл вручную, что может привести к утечке ресурсов. Пример с явным закрытием файла:
file = open('data.csv', 'r')
try:
reader = csv.reader(file)
for row in reader:
print(row)
finally:
file.close()
Этот метод гарантирует, что файл будет закрыт, даже если в процессе чтения возникнет ошибка, благодаря блоку finally.
Не следует открывать файл без закрытия, так как это может привести к различным проблемам, таким как недостаток памяти или невозможность записи в файл, если файл был открыт в режиме записи. Ресурсы системы остаются занятыми, что может привести к замедлению работы программы или даже к сбоям при попытке открыть файл повторно.
Как объединить чтение CSV с фильтрацией данных
Для эффективной работы с данными из CSV файла в Python можно сразу же внедрить фильтрацию, чтобы извлечь только нужную информацию. В этом процессе важно правильно настроить фильтрацию в момент чтения, что избавляет от необходимости дополнительной обработки после загрузки всех данных.
Для начала необходимо импортировать модуль csv. Затем можно открыть файл и использовать цикл для построчного чтения данных. Чтобы фильтровать строки на лету, можно добавить условие внутри цикла, которое будет проверять данные каждого поля. Например, если требуется выбрать только те записи, где значение в определенном столбце больше заданного порога, можно использовать такой код:
import csv
with open('data.csv', 'r') as file:
reader = csv.DictReader(file)
for row in reader:
if float(row['age']) > 30: # Фильтрация по возрасту
print(row)
Фильтрация может быть более сложной, например, если нужно комбинировать несколько условий. Для этого можно объединить их с помощью логических операторов. Например, если нужно выбрать записи, где возраст больше 30 и в поле ‘city’ указано ‘Moscow’, код будет следующим:
with open('data.csv', 'r') as file:
reader = csv.DictReader(file)
for row in reader:
if float(row['age']) > 30 and row['city'] == 'Moscow':
print(row)
Такой подход позволяет эффективно работать с большими наборами данных, фильтруя информацию уже при чтении. Это снижает нагрузку на память и ускоряет выполнение программы. Использование csv.DictReader также дает возможность гибко обрабатывать данные, так как с ними можно работать как с обычными словарями, что упрощает фильтрацию по нужным критериям.