Для работы с PDF-файлами в Python существует несколько библиотек, каждая из которых решает свою задачу. Одной из самых популярных является PyPDF2, которая позволяет извлекать текст, а также работать с метаданными и разделами документа. Однако, если требуется более сложная обработка (например, извлечение текста из изображений или сложных макетов), стоит обратить внимание на pdfplumber, которая даёт более точные результаты при извлечении текста из таблиц и других структурированных данных.
Первый шаг в парсинге PDF-файлов – это установка необходимых библиотек. Для работы с PyPDF2 достаточно установить её через pip: pip install PyPDF2. Для работы с pdfplumber процедура аналогична: pip install pdfplumber. Эти библиотеки позволяют извлекать текстовую информацию и работать с метаданными документов.
После установки библиотек, основной задачей становится правильная обработка файла. В случае с PyPDF2, вы можете прочитать содержимое страницы с помощью метода getPage(), а затем извлечь текст с помощью extractText(). Однако важно понимать, что такие методы не всегда дают точные результаты, особенно в случае с документами с нетекстовыми элементами или сложной версткой.
Для более точного извлечения данных из PDF, например, из таблиц или графиков, используйте pdfplumber. Эта библиотека извлекает текст с учётом структуры документа, что особенно полезно при работе с таблицами. Например, функция plumber.open(‘file.pdf’).extract_text() вернёт текст с учётом его позиционирования на странице, что значительно улучшает качество извлечённой информации.
Кроме того, для работы с PDF, содержащими изображения с текстом, можно использовать сочетание pdfplumber и Pytesseract для извлечения текста из картинок через технологию оптического распознавания символов (OCR). Это полезно, если ваш документ включает сканы или сложные элементы, требующие дополнительной обработки.
Установка и настройка необходимых библиотек для парсинга PDF
Для начала работы с парсингом PDF файлов в Python необходимо установить несколько библиотек. Рассмотрим наиболее популярные инструменты: PyPDF2, pdfplumber и PyMuPDF. Каждая из этих библиотек имеет свои особенности и преимущества, в зависимости от задач, которые вы ставите.
1. PyPDF2 – одна из самых популярных библиотек для работы с PDF. Она предоставляет функционал для извлечения текста, разделения и слияния страниц, а также для работы с метаданными файлов.
Для установки PyPDF2 используйте следующую команду:
pip install pypdf2
2. pdfplumber – более продвинутая библиотека, которая используется для извлечения текста с учетом структуры документа, включая таблицы. pdfplumber хорошо подходит для работы с документами, где важно извлечение данных в их исходной форме.
Для установки pdfplumber выполните команду:
pip install pdfplumber
3. PyMuPDF (также известная как fitz) – это мощный инструмент, который поддерживает извлечение текста, а также работу с изображениями, аннотациями и многими другими объектами внутри PDF.
Установить PyMuPDF можно с помощью следующей команды:
pip install pymupdf
После установки библиотек, можно начинать их использовать. Важно отметить, что каждая из этих библиотек имеет свои особенности, например, PyPDF2 не всегда корректно извлекает текст из сложных PDF-документов, в то время как pdfplumber работает с таблицами гораздо лучше.
Если вы хотите работать с несколькими типами документов, рекомендуется использовать pdfplumber или PyMuPDF, так как они обеспечивают более точное извлечение данных.
Извлечение текста из PDF с помощью PyPDF2

Для начала нужно установить библиотеку. Сделать это можно через pip:
pip install PyPDF2
После установки библиотеки, откроем PDF файл и извлечем из него текст. Рассмотрим пошаговый процесс:
- Импортируем PyPDF2. Для начала импортируем библиотеку в Python-скрипт:
- Открываем файл. Чтобы работать с PDF, нужно сначала открыть файл в режиме чтения. Обычно это делается с помощью стандартного Python-функционала:
- Создаем объект PdfReader. Далее создаем объект PdfReader, который будет работать с нашим PDF-файлом:
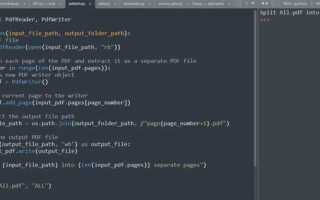
- Извлекаем текст. Теперь можно извлечь текст из каждой страницы PDF. Для этого используем метод .getPage() для доступа к странице и метод .extract_text() для извлечения текста:
- Обработка нескольких страниц. Если файл состоит из нескольких страниц, можно пройтись по всем страницам с помощью цикла:
import PyPDF2
with open('example.pdf', 'rb') as file:
reader = PyPDF2.PdfReader(file)
page = reader.getPage(0)
text = page.extract_text()
for page_num in range(len(reader.pages)):
page = reader.getPage(page_num)
text += page.extract_text()
print(text)
В результате выполнения кода вы получите текстовое содержимое PDF. Однако стоит помнить, что PyPDF2 не всегда идеально извлекает текст. Это может зависеть от структуры документа, например, если текст в файле находится в виде изображений или использует нестандартные шрифты.
Советы для улучшения извлечения текста:
- При работе с текстами на сканированных изображениях PDF, PyPDF2 не поможет. Для таких задач лучше использовать OCR (оптическое распознавание символов), например, с помощью Tesseract.
- Проверяйте наличие мультимедийных объектов или сложных таблиц в PDF. PyPDF2 может не извлечь эти элементы корректно.
- Если PyPDF2 не работает эффективно, можно попробовать другие библиотеки, такие как PDFMiner, которые могут быть более подходящими для сложных случаев.
PyPDF2 – это хороший инструмент для извлечения текста из PDF в стандартных случаях, однако для работы с более сложными документами могут потребоваться дополнительные методы обработки.
Обработка сложных PDF файлов с помощью PDFMiner
PDFMiner – мощная библиотека для извлечения текста и данных из PDF документов. Особенно полезна она при работе с файлами, содержащими сложные структуры, такие как таблицы, нестандартное форматирование или зашитый текст. В отличие от других инструментов, PDFMiner позволяет детально анализировать внутреннюю структуру документа, что важно для обработки сложных PDF файлов.
Для начала работы с PDFMiner необходимо установить библиотеку с помощью команды:
pip install pdfminer.six
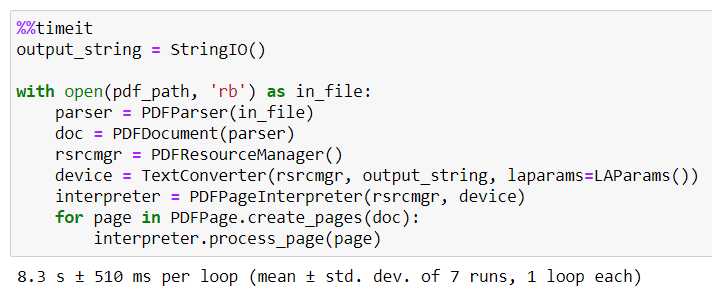
После установки можно приступать к извлечению текста. Основной инструмент для этого – класс PDFParser, который разбирает сам файл, и PDFDocument, который сохраняет его структуру. Для извлечения текста используют класс PDFTextExtractionNotAllowed, чтобы убедиться, что текст в документе доступен для извлечения.
Если структура документа сложная (например, таблицы или многоуровневые заголовки), нужно использовать дополнительные методы для обработки. В частности, можно применить LAParams – параметры для настройки алгоритма анализа текста, чтобы улучшить результат при извлечении текста, учитывая особенности документа, такие как межстрочный интервал или символы-разделители.
Пример кода для извлечения текста из сложного PDF файла:
from pdfminer.high_level import extract_text
text = extract_text('example.pdf')
print(text)
Когда требуется извлечь текст в специфическом порядке или с учётом форматирования, необходимо использовать более низкоуровневые методы PDFMiner. Например, класс PDFPage позволяет обрабатывать каждую страницу отдельно, а PDFResourceManager – управлять ресурсами документа, такими как шрифты и изображения.
Для работы с таблицами PDFMiner предоставляет класс TextConverter, который преобразует текстовые данные в более удобный формат для дальнейшего анализа. Важно помнить, что при извлечении данных из таблиц могут возникать проблемы с точностью, поскольку PDF не всегда сохраняет правильную структуру строк и колонок.
Пример более сложного кода для извлечения текста с учётом структуры документа:
from pdfminer.layout import LAParams
from pdfminer.high_level import extract_text
laparams = LAParams()
text = extract_text('complex_document.pdf', laparams=laparams)
print(text)
Иногда для обработки конкретных элементов (например, сохранения форматирования или извлечения только части данных) нужно использовать дополнительные инструменты, такие как pdfminer.layout, который позволяет работать с элементами страницы, такими как текстовые блоки, линии и изображения. Это полезно, когда необходимо точно распознать таблицы, графики или другие структурированные элементы документа.
Обработка сложных PDF файлов требует внимательности к деталям и настройки параметров для корректного извлечения данных. PDFMiner предоставляет гибкость в работе с такими документами, но важно учитывать специфику структуры каждого конкретного файла.
Парсинг изображений из PDF с использованием pdf2image
Библиотека pdf2image позволяет конвертировать страницы PDF в растровые изображения. Это особенно полезно при необходимости извлечь визуальные данные или передать файл на OCR-обработку. Перед началом требуется установка зависимостей:
pip install pdf2image
sudo apt install poppler-utils # для Linux
# или
brew install poppler # для macOS
Базовый пример преобразования всех страниц PDF в изображения:
from pdf2image import convert_from_path
images = convert_from_path('документ.pdf', dpi=300)
for i, img in enumerate(images):
img.save(f'page_{i + 1}.png', 'PNG')
Ключевые параметры convert_from_path:
dpi– разрешение изображения. Значение 300 подходит для последующего OCR.first_pageиlast_page– ограничение диапазона конвертации.
Если требуется извлечь изображения только с определённых страниц:
images = convert_from_path('документ.pdf', dpi=300, first_page=2, last_page=4)
При работе с большим числом страниц следует использовать параметр thread_count для ускорения обработки:
images = convert_from_path('документ.pdf', dpi=300, thread_count=4)
Для временного хранения без записи на диск можно использовать буфер:
from io import BytesIO
buffers = []
for img in convert_from_path('документ.pdf', dpi=300):
buf = BytesIO()
img.save(buf, format='PNG')
buffers.append(buf.getvalue())
Рекомендуется обрабатывать изображения сразу после извлечения – повторная конвертация ресурсоёмка. Если PDF содержит прозрачность или нестандартные цветовые профили, используйте формат TIFF или JPEG с дополнительными параметрами transparent и output_folder.
Чтение и анализ таблиц в PDF с помощью Tabula
Для начала необходимо установить библиотеку tabula-py, что можно сделать через pip:
pip install tabula-pyПосле установки, чтобы начать работу, импортируем нужные модули и загрузим PDF-файл. Пример простого кода:
import tabula
# Загрузка таблиц из PDF в DataFrame
file_path = "document.pdf"
tables = tabula.read_pdf(file_path, pages='all', multiple_tables=True)
for table in tables:
print(table.head())Функция read_pdf извлекает таблицы из указанного файла. Параметр pages позволяет задать страницы для анализа. Значение 'all' указывает на обработку всех страниц. Если вам нужно извлечь таблицы только с конкретных страниц, можно указать диапазон, например, pages='1,3,5'.
В случае, если PDF содержит несколько таблиц на одной странице, параметр multiple_tables=True позволит извлечь все такие таблицы в виде списка DataFrame, каждый из которых представляет собой одну таблицу. Можно также указать параметр area для выделения конкретной области страницы, если таблица располагается в определенной зоне.
После извлечения данных из таблицы, результаты можно обработать с помощью стандартных инструментов Python, например, библиотеки pandas, что позволяет легко работать с полученными DataFrame, выполнять анализ и экспортировать данные в нужный формат:
import pandas as pd
# Сохранение данных в CSV файл
for i, table in enumerate(tables):
table.to_csv(f"table_{i+1}.csv", index=False)Tabula может столкнуться с проблемами при извлечении данных из таблиц, если формат PDF сложный или структура документа нестандартная. В таких случаях можно использовать дополнительные настройки, такие как lattice и stream, которые меняют алгоритм извлечения таблиц:
lattice=True– используется для таблиц с четкими линиями, которые разделяют ячейки.stream=True– предпочтительнее для таблиц, где данные не имеют четких границ между ячейками, а строки и столбцы различаются по пробелам.
Вот пример использования этих параметров:
tables = tabula.read_pdf(file_path, pages='all', lattice=True)Когда данные успешно извлечены, Tabula также предоставляет возможность конвертировать их в другие форматы, такие как Excel, используя функцию tabula.convert_into:
tabula.convert_into(file_path, "output.xlsx", output_format="xlsx", pages="all")Tabula – мощный инструмент для автоматизации извлечения данных из PDF, но его эффективность зависит от качества исходного документа. Важно экспериментировать с настройками, чтобы добиться наилучших результатов в каждом конкретном случае.
Обработка ошибок и исключений при парсинге PDF файлов
При работе с PDF файлами в Python важно учитывать разнообразие ошибок, которые могут возникать на разных этапах парсинга. Ошибки могут быть связаны как с некорректным форматом файла, так и с проблемами в коде, библиотеках или внешних зависимостях. В этой части рассмотрим типичные исключения и методы их обработки.
try:
pdf = PyPDF2.PdfReader("invalid_file.pdf")
except PyPDF2.errors.PdfReadError as e:
print(f"Ошибка при чтении PDF: {e}")
Ещё одной проблемой может быть наличие защищённых паролем файлов. Библиотеки, как PyPDF2, могут выбросить исключение при попытке открыть защищённый файл без пароля. В таком случае необходимо проверить наличие пароля перед открытием:
try:
pdf = PyPDF2.PdfReader("protected_file.pdf")
if pdf.is_encrypted:
pdf.decrypt("password")
except PyPDF2.errors.PdfReadError as e:
print(f"Не удалось расшифровать PDF: {e}")
При парсинге PDF с большими объёмами данных или сложной структурой могут возникнуть ошибки из-за недостатка памяти. В таких случаях стоит использовать обработку исключений и предусмотреть возможность оптимизации работы с файлом, например, загружать страницы поочередно, а не всю структуру файла сразу:
try:
with open("large_file.pdf", "rb") as f:
reader = PyPDF2.PdfReader(f)
page = reader.pages[0]
except MemoryError:
print("Недостаточно памяти для обработки PDF")
Кроме того, стоит учитывать, что различные библиотеки могут иметь свои особенности в обработке файлов. Например, pdfplumber может не всегда корректно извлекать текст из сканированных документов, так как не поддерживает OCR. В таких случаях рекомендуется использовать библиотеки для оптического распознавания символов, такие как Tesseract:
import pytesseract
from PIL import Image
image = Image.open("scanned_page.png")
text = pytesseract.image_to_string(image)
Кроме ошибок, связанных с конкретными библиотеками, могут возникать ошибки связанные с файловыми путями, например, если указанный файл не существует или доступ к нему ограничен. Это можно проверить с помощью стандартных инструментов Python для работы с файловой системой:
import os
file_path = "file.pdf"
if not os.path.exists(file_path):
print(f"Файл {file_path} не найден")
else:
# Процесс парсинга
Использование всех этих методов в совокупности позволяет избежать большинства проблем, связанных с парсингом PDF файлов, и обеспечить более стабильную и предсказуемую работу вашего кода. Не забывайте также логировать ошибки для их дальнейшего анализа и устранения.
Вопрос-ответ:
Что такое парсинг PDF файлов в Python и зачем он нужен?
Парсинг PDF файлов — это процесс извлечения данных из документов в формате PDF с помощью программных инструментов. В Python для этого используют библиотеки, такие как PyPDF2, pdfminer, и PyMuPDF. Этот процесс полезен для автоматизации извлечения текста, таблиц, изображений или метаданных из PDF-документов, что важно для обработки больших объемов информации или извлечения данных из отчетов, счетов, научных статей и других документов.
Какие библиотеки можно использовать для парсинга PDF в Python?
Для парсинга PDF файлов в Python существует несколько популярных библиотек. Одна из них — PyPDF2, которая позволяет извлекать текст, разделять и объединять страницы PDF. Другая библиотека — pdfminer, которая может работать с текстами, шрифтами и структурой документа. Также стоит упомянуть PyMuPDF (fitz), которая имеет более гибкие возможности работы с текстом и изображениями в PDF. В зависимости от задачи, можно выбрать ту или иную библиотеку, так как каждая из них имеет свои особенности и преимущества.