

Для работы с текстовыми данными в Python важно понимать, как правильно конвертировать строки в байты. Этот процесс необходим, например, при работе с файлами, сетевыми запросами или при необходимости отправить данные в бинарном формате. Python предлагает несколько способов перевести строку в байты, и каждый из них имеет свои особенности, которые следует учитывать в зависимости от контекста задачи.
Основной способ перевести строку в байты – использовать метод encode(). Этот метод преобразует строку в байтовую строку, используя выбранную кодировку. По умолчанию используется кодировка UTF-8, которая поддерживает все символы большинства языков мира. Пример: "строка".encode(). Однако для работы с текстами на других языках или с особыми символами, может понадобиться указание другой кодировки, например "string".encode('latin1').
Одним из важных аспектов является выбор кодировки. UTF-8 – это наиболее универсальная кодировка, но в некоторых случаях может потребоваться другая, например ASCII, если нужно работать только с английскими буквами. При неправильном выборе кодировки могут возникнуть ошибки преобразования, особенно если строка содержит символы, не поддерживаемые в выбранной кодировке.
При работе с байтами важно помнить, что байтовые строки в Python начинаются с префикса b, как в b"строка". Это позволяет отличить байтовые строки от обычных текстовых строк, что критично для правильного выполнения операций с данными в низкоуровневых задачах, например, в работе с сокетами или при хранении данных в бинарных файлах.
Как использовать метод encode() для преобразования строки в байты
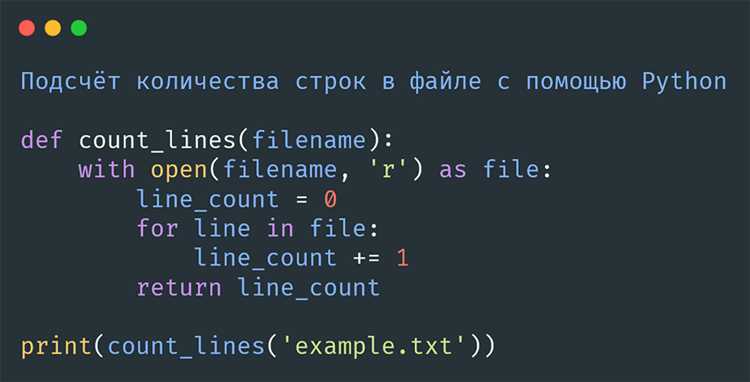
Для вызова метода encode() достаточно указать кодировку, которая будет использоваться для преобразования. Если кодировка не указана, используется кодировка по умолчанию (обычно UTF-8).
Основной синтаксис:
str.encode(encoding="utf-8", errors="strict")- encoding – кодировка, в которой будет произведено преобразование. Примеры: «utf-8», «ascii», «latin-1».
- errors – параметр, который управляет обработкой ошибок при преобразовании. Варианты: «strict» (выбрасывает ошибку), «ignore» (игнорирует ошибочные символы), «replace» (заменяет ошибочные символы).
Пример использования:
text = "Привет, мир!"
encoded_text = text.encode("utf-8")
В этом примере строка "Привет, мир!" преобразуется в байты с использованием кодировки UTF-8. Результат – это объект типа bytes, который начинается с символа b, что указывает на байтовое представление строки.
Важные замечания:
- Для работы с байтовыми строками важно учитывать, что они могут не поддерживать все операции, доступные обычным строкам, такие как сложение или замена символов.
- При использовании кодировки ASCII возможно появление ошибок, если строка содержит символы, которые не входят в стандартный набор ASCII.
- Использование кодировки UTF-8 позволяет сохранить все символы, включая символы национальных алфавитов, эмодзи и специальные знаки.
Заключение:
Метод encode() является удобным и мощным инструментом для преобразования строк в байты. Он позволяет гибко управлять кодировками и обработкой ошибок, что особенно важно при работе с текстами, требующими точности в представлении данных. Выбор правильной кодировки зависит от задач, стоящих перед разработчиком, и среды, в которой будет использоваться результат.
Выбор кодировки для преобразования строки в байты

При преобразовании строки в байты в Python необходимо выбрать подходящую кодировку. Это влияет на то, как символы будут представлены в виде байтов, и на успешность их обработки. Основные кодировки, которые используются для этой задачи, включают UTF-8, ASCII, Latin-1 и другие.
UTF-8 – наиболее универсальная кодировка для работы с текстами, содержащими символы различных языков. Она поддерживает все символы Unicode и является стандартом для большинства современных приложений. Если не требуется особых ограничений на набор символов, UTF-8 будет наилучшим выбором.
ASCII ограничивает набор символов 128 базовыми символами латинского алфавита, цифрами и некоторыми управляющими символами. Если строка содержит только английские буквы, цифры и знаки препинания, использование ASCII значительно эффективнее, так как она требует меньшего объема памяти.
Latin-1 подходит для большинства западноевропейских языков, включая французский, немецкий, испанский и другие. Это кодировка с фиксированным размером символов (1 байт на символ), что делает ее удобной для работы с текстами, содержащими эти языки, но она не поддерживает символы, выходящие за пределы латинского алфавита.
UTF-16 и UTF-32 используются реже, но могут быть полезны, если необходимо обрабатывать тексты с большим количеством уникальных символов, таких как иероглифы китайского языка. Эти кодировки требуют больше памяти на символ, но гарантируют поддержку всех символов Unicode.
Если кодировка не выбрана явно, Python по умолчанию использует UTF-8, что покрывает большинство сценариев. Однако, важно помнить, что при работе с конкретными данными и файлами важно учитывать, какая кодировка была использована при их создании, чтобы избежать ошибок при декодировании.
Использование неправильной кодировки может привести к ошибкам, таким как UnicodeDecodeError, если кодировка при преобразовании не совпадает с исходной. Поэтому, перед выбором кодировки стоит оценить, какие символы будут использованы в строках, и выбрать наиболее подходящий вариант для задачи.
Почему важно учитывать кодировку при преобразовании строки в байты
При преобразовании строки в байты необходимо правильно выбрать кодировку, чтобы избежать ошибок интерпретации данных. Строки в Python представляют собой последовательность символов, которые могут быть закодированы в байты с использованием различных кодировок, таких как UTF-8, ASCII или ISO-8859-1. Каждая кодировка имеет свои особенности и ограничения, которые важно учитывать для корректной работы программы.
Одной из распространенных проблем является несоответствие кодировки строки и системы, в которой она используется. Например, если строка закодирована в UTF-8, а программа ожидает ASCII, то символы, выходящие за пределы ASCII, не будут правильно преобразованы в байты, что приведет к UnicodeDecodeError или неправильному отображению данных.
Важно помнить, что кодировка влияет не только на корректность обработки текста, но и на его совместимость с другими системами. Например, UTF-8 является стандартом для большинства веб-приложений, а ASCII может быть ограничен в представлении специальных символов и языков с расширенной палитрой символов. Поэтому при работе с текстовыми данными важно учитывать, какая кодировка ожидается на стороне получателя данных.
Рекомендации: всегда указывайте кодировку при преобразовании строки в байты с помощью метода encode(). Это обеспечит гарантированную совместимость и предсказуемость результата. Например, для кодировки UTF-8 используйте:
text.encode('utf-8')
Также стоит помнить, что кодировка влияет на размер данных. Некоторые кодировки, такие как UTF-8, могут занимать больше места для представления символов, чем другие, такие как ASCII. Поэтому при работе с большими объемами текста стоит внимательно подойти к выбору кодировки для оптимизации памяти.
Как конвертировать строку в байты с использованием метода bytes()
Метод bytes() в Python позволяет преобразовать строку в последовательность байтов, что полезно для работы с низкоуровневыми операциями, такими как сетевые протоколы или запись в бинарные файлы.
Применение метода происходит следующим образом: необходимо передать строку, которую требуется преобразовать, и указать кодировку. Если кодировка не указана, по умолчанию используется utf-8.
str_data = "Пример текста"
byte_data = bytes(str_data, 'utf-8')
Результатом работы метода будет объект типа bytes, который можно использовать для различных целей. Метод подходит для строк, состоящих из символов в Unicode, и не вызывает ошибок при наличии символов, которые нельзя представить в кодировке ASCII.
Если необходимо преобразовать строку в байты с другой кодировкой, это можно сделать, передав нужную кодировку как второй параметр:
str_data = "Hello"
byte_data = bytes(str_data, 'latin-1')
Стоит учитывать, что неправильный выбор кодировки может привести к ошибкам, особенно если строка содержит символы, не поддерживаемые выбранной кодировкой.
Метод bytes() также может быть использован для создания пустого байтового объекта, если передать пустую строку:
empty_bytes = bytes("")
Важный момент: метод bytes() не изменяет исходную строку, а возвращает новый объект, который можно использовать в дальнейшем.
Что такое UTF-8 и как его применить для кодирования строки в байты
UTF-8 кодирует символы в диапазоне от 1 до 4 байтов. Символы, встречающиеся чаще, например, латинские буквы, занимают 1 байт, в то время как более сложные символы, такие как иероглифы или эмодзи, могут занимать до 4 байтов. Эта особенность делает UTF-8 удобным для работы с текстами, содержащими разнообразные символы, так как она минимизирует затраты на память для простых текстов и эффективно поддерживает более сложные символы.
Для кодирования строки в байты в Python используется метод encode() строки. Пример использования UTF-8:
text = "Привет, мир!"
encoded_text = text.encode('utf-8')
print(encoded_text)
Этот код преобразует строку "Привет, мир!" в байтовую последовательность, используя кодировку UTF-8. Важно отметить, что метод encode() возвращает объект типа bytes, который представляет строку в виде последовательности байтов.
При работе с UTF-8 важно учитывать, что кодировка этой строки может быть различной в зависимости от платформы и настроек. Однако UTF-8 является стандартом, поддерживаемым всеми современными операционными системами и языками программирования, что делает его универсальным выбором для кодирования строк в байты.
Как работать с байтами в Python после их получения из строки
После получения строки в виде байтов (с помощью метода encode()), работа с ними открывает новые возможности для обработки данных, особенно когда требуется взаимодействие с бинарными форматами или сетевыми протоколами.
Для начала, важно понимать, что байты в Python – это неизменяемые последовательности, и их элементы представляют собой значения в диапазоне от 0 до 255. Чтобы работать с байтами, можно использовать стандартные методы, которые позволяют преобразовывать, манипулировать и анализировать данные.
Чтение байтов можно осуществить с помощью метода decode(), который преобразует байты обратно в строку. Этот метод требует указания кодировки, например, UTF-8 или ASCII:
байты = b'hello'
строка = байты.decode('utf-8')
print(строка) # hello
Сравнение байтов можно выполнять как с обычными строками. Байты сравниваются по каждому элементу, и результат операции зависит от значения этих элементов:
байты1 = b'hello'
байты2 = b'world'
print(байты1 == байты2) # False
Конкатенация байтов возможна с помощью оператора +:
байты1 = b'hello'
байты2 = b'world'
результат = байты1 + байты2
print(результат) # b'helloworld'
Индексация байтов работает аналогично строкам, каждый элемент байтового объекта можно получить по индексу:
байты = b'hello'
print(байты[0]) # 104 (ASCII-код 'h')
Обработка ошибок при декодировании также важна. Когда данные, полученные в байтовом формате, не могут быть корректно преобразованы в строку из-за несовпадения кодировки, можно использовать параметр errors с различными режимами обработки ошибок:
байты = b'hello'
строка = байты.decode('utf-8', errors='ignore') # игнорирование ошибок
print(строка)
Применение байтов в файлах требует записи байтов, а не строк в бинарном режиме. Например, для записи байтов в файл используется режим 'wb':
содержимое = b'пример байтов'
with open('файл.bin', 'wb') as файл:
файл.write(содержимое)
Преобразование байтов в другие типы может понадобиться для использования в математических вычислениях или других операциях. Для этого байты можно конвертировать в числа с помощью функции int.from_bytes(), указав порядок байтов (little-endian или big-endian):
байты = b'\x01\x00\x00\x00'
число = int.from_bytes(байты, 'little')
print(число) # 1
Работа с байтами в Python важна для работы с низкоуровневыми данными, и знание этих методов и их применения позволяет эффективно манипулировать бинарными форматами.
Что делать с ошибками при преобразовании строки в байты
При преобразовании строки в байты в Python могут возникать ошибки, связанные с кодировкой или несовместимостью данных. Важно понимать, какие конкретно ошибки могут возникнуть и как их обработать.
Основные ошибки, с которыми можно столкнуться:
- UnicodeEncodeError – ошибка, возникающая, когда строка не может быть закодирована в заданной кодировке.
- UnicodeDecodeError – ошибка при попытке декодирования байтов в строку, если байты не соответствуют ожидаемой кодировке.
Чтобы избежать таких ошибок, следуйте следующим рекомендациям:
- Выбор правильной кодировки: Убедитесь, что строка может быть закодирована в выбранной кодировке. Наиболее распространенные кодировки – UTF-8, ASCII, ISO-8859-1. Пример:
str.encode('utf-8')
- Использование параметра
errors: Если вам нужно обработать ошибку кодирования, используйте параметр errors с подходящим значением, например, ignore или replace. Пример:
str.encode('utf-8', errors='ignore')
- Обработка исключений: Для защиты кода от неожиданных ошибок используйте конструкцию try-except. Пример:
try:
byte_string = str.encode('utf-8')
except UnicodeEncodeError as e:
print(f"Ошибка кодирования: {e}")
byte_string = b""
- Проверка содержимого строки: Иногда строка может содержать неподдерживаемые символы. Проверьте её перед преобразованием:
if all(ord(char) < 128 for char in str):
Правильная обработка ошибок при преобразовании строк в байты помогает избежать сбоев в работе программы и гарантирует корректное выполнение операций с кодировками.
Примеры использования байтов в сетевых запросах и сохранении файлов

В Python байты часто используются для передачи данных в сетевых запросах, а также для работы с бинарными файлами. При отправке HTTP-запросов через библиотеки, такие как requests, данные часто передаются в виде байтов. Это важно для правильной обработки различных типов контента, таких как изображения, аудио или файлы в бинарном формате.
Когда отправляется POST-запрос с файлом, его содержимое преобразуется в байты. Например, если нужно загрузить изображение, то его можно передать так:
import requests
with open('image.jpg', 'rb') as f:
files = {'file': f}
response = requests.post('https://example.com/upload', files=files)
Здесь файл открыт в бинарном режиме 'rb', что позволяет правильно обработать его как байты. В ответе можно получить статус загрузки и дополнительные данные о файле, такие как его идентификатор на сервере.
В случае с API, которое принимает данные в бинарном формате, важно отправлять запросы с правильно установленными заголовками, чтобы сервер понимал тип передаваемых данных. Например, при отправке JSON данных, преобразованных в байты, заголовок Content-Type должен быть установлен в application/json.
import requests
import json
data = {'key': 'value'}
json_data = json.dumps(data).encode('utf-8') # Преобразуем в байты
response = requests.post('https://example.com/api', data=json_data, headers={'Content-Type': 'application/json'})
Этот пример показывает, как данные в виде строки преобразуются в байты с помощью метода encode('utf-8'), что позволяет отправить их в сетевой запрос с правильным кодированием.
Для сохранения бинарных данных в файл, также используются байты. Например, если нужно сохранить изображение, полученное в ответе на запрос, файл записывается в бинарном формате:
response = requests.get('https://example.com/image.jpg')
with open('downloaded_image.jpg', 'wb') as f:
f.write(response.content)
Здесь response.content содержит данные в байтовом формате, которые записываются в файл с помощью режима 'wb', что указывает на бинарное сохранение.
Для оптимизации работы с файлами и сетевыми запросами важно учитывать размер передаваемых данных. Для работы с большими файлами и сетевыми потоками рекомендуется использовать пакет io для создания буферов и потоков данных. Это позволяет эффективно работать с файлами без необходимости загружать их целиком в память.
Когда работа с байтами связана с передачей чувствительных данных, важно использовать шифрование для защиты информации. Библиотеки, такие как cryptography, позволяют зашифровать данные перед отправкой, а затем расшифровать их на стороне получателя, обеспечивая безопасность.
Вопрос-ответ:
Как в Python перевести строку в байты?
В Python для того, чтобы перевести строку в байты, можно использовать метод `.encode()`. Например, строка `"Привет"` может быть преобразована в байты следующим образом: `"Привет".encode('utf-8')`. Это вернет байтовое представление строки в кодировке UTF-8.
Какая кодировка используется при переводе строки в байты по умолчанию?
Если при использовании метода `.encode()` не указать конкретную кодировку, Python по умолчанию использует кодировку UTF-8. Это наиболее распространенная кодировка для текстовых данных и она поддерживает все символы Юникода.
Что произойдет, если попытаться использовать кодировку, которая не поддерживает все символы строки?
Если в Python при вызове `.encode()` указать кодировку, которая не поддерживает все символы строки, возникнет ошибка `UnicodeEncodeError`. Например, кодировка `ascii` не поддерживает кириллические символы, и попытка закодировать строку с такими символами приведет к этой ошибке.
Могу ли я использовать другую кодировку, кроме UTF-8?
Да, можно использовать любую кодировку, поддерживаемую Python. Например, можно указать кодировку `utf-16`, `latin1`, `cp1251` и другие. Нужно только убедиться, что выбранная кодировка поддерживает все символы строки. Пример: `"Привет".encode('utf-16')`.
Что такое байты в Python и зачем их использовать?
Байты — это последовательности данных, представленные в виде чисел от 0 до 255. Они используются для работы с бинарными данными, такими как файлы, сетевые запросы или криптографические операции. В отличие от строк, байты не содержат информации о символах, а представляют собой именно двоичные данные, что делает их полезными для обработки низкоуровневых данных.





