Когда работа с текстовыми файлами становится частью процесса обработки данных, необходимо эффективно управлять их содержимым. Одной из типичных задач является удаление нежелательных символов, таких как пробелы, знаки препинания или специальные символы, которые не влияют на анализ данных, но могут исказить результаты. В Python существует несколько инструментов и подходов для решения этой задачи, позволяющих легко и быстро очистить содержимое файла.
Основным методом для удаления символов из текста является использование встроенных методов работы со строками. Метод str.replace() может заменить конкретные символы на пустое значение, что эффективно для удаления отдельных символов. Однако, если задача более сложная и требуется удалить все символы, которые не относятся к буквам или цифрам, стоит использовать регулярные выражения через модуль re, что позволяет контролировать фильтрацию с высокой гибкостью.
Кроме того, важно помнить, что обработка больших файлов требует оптимизации. В таких случаях полезно работать с файлами построчно, чтобы избежать излишней загрузки в память. Модуль io и его методы могут существенно облегчить эту задачу. Технологии работы с текстом в Python позволяют минимизировать время на удаление символов, если подходить к решению с правильной стратегией.
Как открыть и прочитать содержимое txt файла с помощью Python
Для работы с текстовыми файлами в Python используется встроенная функция open(). С помощью этого метода можно не только открыть файл, но и указать режим его использования: чтение, запись или добавление данных. Для чтения файла в Python принято использовать режим 'r', который открывает файл только для чтения.
Простой пример:
file = open('example.txt', 'r')
content = file.read()
file.close()После выполнения этого кода переменная content будет содержать весь текст, который находится в файле example.txt. Важно закрыть файл с помощью метода close(), чтобы освободить ресурсы.
Рекомендуется использовать конструкцию with, которая автоматически закрывает файл по завершении блока кода. Это предотвращает возможные ошибки, связанные с забыванием закрытия файла:
with open('example.txt', 'r') as file:
content = file.read()Также важно помнить, что метод read() считывает весь файл целиком. Если файл слишком большой, это может привести к перегрузке памяти. В таких случаях лучше читать файл построчно с помощью метода readline() или обходить его строку за строкой с помощью цикла for:
with open('example.txt', 'r') as file:
for line in file:
print(line)Если нужно прочитать все строки в виде списка, можно использовать метод readlines(). Этот метод возвращает список, где каждый элемент – это одна строка из файла:
with open('example.txt', 'r') as file:
lines = file.readlines()Теперь переменная lines содержит список строк файла, и можно работать с ними по отдельности.
В случаях, когда необходимо работать с кодировками, Python поддерживает различные варианты через параметр encoding в функции open(). Например, для работы с файлами, закодированными в UTF-8, можно использовать:
with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()Если файл не существует, Python выбросит ошибку FileNotFoundError. Чтобы избежать этого, можно использовать конструкцию try-except для обработки ошибок:
try:
with open('example.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден.")Этот подход поможет сделать код более надежным и предотвратить сбои программы.
Использование метода.replace() для удаления символов
Метод replace() в Python позволяет заменять подстроки в строках. Он может быть использован не только для замены, но и для удаления символов, если в качестве нового значения передать пустую строку.
Основной синтаксис метода:
строка.replace(старое_значение, новое_значение)Чтобы удалить символы, необходимо передать в replace() старое значение, которое нужно удалить, и пустую строку как новое значение. Например:
текст = "Пример текста"
текст = текст.replace("е", "")В этом примере все символы «е» в строке будут удалены.
Если нужно удалить несколько различных символов, можно применить replace() несколько раз:
текст = "Пример текста"
текст = текст.replace("е", "").replace("т", "")Это удалит все символы «е» и «т» из строки. Однако такой подход может быть неэффективным, если необходимо удалить много различных символов, так как метод будет вызван для каждого из них отдельно.
Для более сложных случаев рекомендуется использовать регулярные выражения через модуль re, так как они позволяют удалить сразу несколько символов за один вызов.
Пример использования replace() для удаления символов из файла:
with open("файл.txt", "r") as file:
текст = file.read()
текст = текст.replace("лишний_символ", "")
with open("файл_без_символов.txt", "w") as file:
file.write(текст)Этот код читает содержимое текстового файла, удаляет все вхождения определённого символа и записывает изменённый текст в новый файл.
Метод replace() подходит для удаления одиночных символов или простых подстрок, но если задача сложнее, стоит обратить внимание на другие подходы, такие как использование регулярных выражений или написание собственной логики для фильтрации символов.
Удаление символов с использованием регулярных выражений в Python
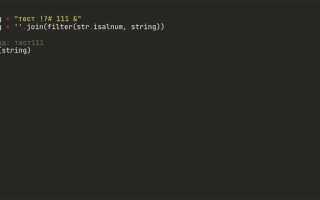
Для удаления символов из текста в Python часто используют модуль re, который поддерживает регулярные выражения. Регулярные выражения позволяют задать сложные паттерны для поиска и удаления различных символов. Это мощный инструмент для манипуляции строками, особенно если нужно удалить несколько типов символов за один проход.
Простейший способ удаления символов – использование функции re.sub(). Она заменяет все совпадения с регулярным выражением на указанное значение. Если требуется удалить символы, достаточно заменить их на пустую строку.
Пример удаления всех цифр из текста:
import re
text = "Пример 123 текста с числами 456."
result = re.sub(r'\d+', '', text)
print(result)В этом примере r’\d+’ – регулярное выражение, которое находит все цифры. Заменив их на пустую строку, мы удаляем все числа из исходного текста.
Можно удалять не только цифры, но и любые другие символы. Например, чтобы убрать все знаки препинания:
result = re.sub(r'[^\w\s]', '', text)
print(result)Регулярное выражение [^\w\s] означает «все символы, кроме букв, цифр и пробела». Таким образом, все знаки препинания будут удалены.
Для удаления конкретных символов можно использовать более точные регулярные выражения. Например, если нужно удалить только символы «<" и ">«, то можно использовать следующий паттерн:
result = re.sub(r'[<>]', '', text)
print(result)В случаях, когда необходимо выполнить удаление по нескольким условиям, регулярные выражения позволяют комбинировать различные паттерны. Например, если нужно удалить все пробелы и цифры:
result = re.sub(r'[\d\s]', '', text)
print(result)Здесь r'[\d\s]’ означает «цифры и пробелы». Все такие символы будут удалены из текста.
Регулярные выражения – это очень гибкий и мощный инструмент для работы с текстовыми данными. Однако важно помнить, что использование сложных выражений без должного тестирования может привести к ошибкам, особенно если паттерн слишком общий или неправильный. Поэтому рекомендуется тщательно проверять, что именно будет удаляться, прежде чем применять такие методы на больших объемах данных.
Как удалить пробелы и пустые строки из текста в файле
Удаление пробелов и пустых строк – важная задача при обработке текстовых файлов. Это позволяет очистить данные, уменьшить размер файла и подготовить его для дальнейшего анализа или использования. В Python для этой цели можно использовать встроенные функции, которые позволяют эффективно удалять ненужные пробелы и пустые строки.
Для удаления пробелов с концов строк и лишних пустых строк из файла можно воспользоваться следующим алгоритмом:
1. Откройте файл для чтения и считывания всех строк.
2. Пройдитесь по каждой строке, удаляя лишние пробелы с начала и конца с помощью метода strip().
3. Пропустите строки, которые становятся пустыми после удаления пробелов, или удалите их с помощью условия, проверяющего пустоту строки.
4. Сохраните очищенные строки в новый файл или перезапишите старый.
Пример кода для удаления пробелов и пустых строк:
with open('input.txt', 'r') as file:
lines = file.readlines()
cleaned_lines = [line.strip() for line in lines if line.strip()]
with open('output.txt', 'w') as file:
file.writelines('\n'.join(cleaned_lines))
В данном примере метод strip() удаляет пробелы с краев строки, а условие if line.strip() исключает строки, которые становятся пустыми после этого. В результате получаем текст без лишних пробелов и пустых строк.
Если необходимо просто удалить все пробелы внутри строк, то можно использовать метод replace():
cleaned_lines = [line.replace(" ", "") for line in lines if line.strip()]
Этот подход эффективно удаляет все пробелы, не оставляя их внутри текста, однако требует осторожности, так как удаление всех пробелов может изменить смысл текста, например, в случае, когда пробелы играют важную роль (например, в числовых значениях).
При работе с большими файлами рекомендуется использовать более эффективные методы, например, чтение и запись по частям, чтобы избежать излишней нагрузки на память.
Удаление конкретных символов из файла с помощью цикла for
Для удаления конкретных символов из текста файла можно использовать цикл for. Этот способ полезен, когда необходимо заменить или удалить определённые символы, не прибегая к сложным регулярным выражениям или сторонним библиотекам.
Процесс начинается с открытия файла и чтения его содержимого. После этого можно пройти по каждому символу с помощью цикла for и удалить нежелательные символы. Рассмотрим пример, где необходимо удалить все восклицательные знаки из текстового файла.
with open("input.txt", "r") as file:
text = file.read()
text_without_exclamation = ""
for char in text:
if char != "!":
text_without_exclamation += char
with open("output.txt", "w") as file:
file.write(text_without_exclamation)
В данном примере строка `text` содержит весь текст из файла. Мы создаём новую строку `text_without_exclamation`, в которую добавляются только те символы, которые не являются восклицательными знаками. Цикл for перебирает каждый символ в тексте и проверяет условие. Если символ не равен `!`, он добавляется в результат.
Этот способ хорошо подходит для удаления нескольких символов, если их можно перечислить. Например, можно удалить все знаки препинания или пробелы, расширив условие цикла:
chars_to_remove = "!.,?;:" for char in text: if char not in chars_to_remove: text_without_chars += char
Этот подход позволит гибко управлять набором символов для удаления и использовать цикл для обработки каждого символа в строках файла. Однако стоит помнить, что метод работает с небольшими текстами эффективно. Для обработки больших файлов может понадобиться использование более оптимизированных решений.
Как записать изменённый текст обратно в файл

После того как вы обработали текст и удалили лишние символы, следующий шаг – записать результат обратно в исходный файл или в новый. Для этого в Python используется встроенная функция open() с режимом записи.
Если вы хотите перезаписать файл, используйте режим 'w', который откроет файл для записи, очищая его содержимое. Пример:
with open('file.txt', 'w', encoding='utf-8') as f:
f.write(modified_text)
Важно помнить, что при использовании режима 'w' файл будет перезаписан, и все данные в нем будут удалены. Если нужно сохранить старое содержимое и добавить изменения в конец файла, используйте режим 'a' (append):
with open('file.txt', 'a', encoding='utf-8') as f:
f.write(modified_text)
Если же требуется полностью заменить старое содержимое новым, но при этом избегать потери данных при ошибках, можно сначала записать результат во временный файл, а затем переименовать его:
with open('temp_file.txt', 'w', encoding='utf-8') as temp_f:
temp_f.write(modified_text)
import os
os.replace('temp_file.txt', 'file.txt')
Для работы с текстовыми файлами рекомендуется всегда использовать with, так как это гарантирует закрытие файла даже в случае возникновения ошибок в процессе записи.
Обработка ошибок при удалении символов из файла
При удалении символов из текстового файла с использованием Python важно учитывать несколько типов ошибок, которые могут возникнуть в процессе работы. Ошибки могут быть связаны с чтением файла, его доступностью, а также с некорректной обработкой данных. Важно заранее предусмотреть возможные проблемы, чтобы обеспечить корректную работу программы.
1. Ошибка открытия файла
Одной из частых ошибок является отсутствие доступа к файлу. Это может быть связано с отсутствием файла по указанному пути или недостаточными правами доступа для чтения и записи. Чтобы избежать этой проблемы, используйте конструкцию try-except для перехвата ошибок, например, FileNotFoundError или PermissionError:
try:
with open('file.txt', 'r') as file:
data = file.read()
except FileNotFoundError:
print("Файл не найден")
except PermissionError:
print("Недостаточно прав для доступа к файлу")2. Ошибки при чтении данных
Если в процессе чтения файла возникают проблемы с его содержимым (например, файл поврежден или имеет нестандартное кодирование), можно столкнуться с ошибкой декодирования. Для этого стоит указать кодировку, например, UTF-8:
try:
with open('file.txt', 'r', encoding='utf-8') as file:
data = file.read()
except UnicodeDecodeError:
print("Ошибка при чтении файла: несовместимая кодировка")3. Ошибки при записи в файл
Когда требуется сохранить изменения, может возникнуть ошибка, связанная с записью в файл. Это может произойти, если файл открыт только для чтения или отсутствуют права на запись. Важно использовать правильный режим открытия файла (‘w’ или ‘a’), а также обработать возможные исключения, такие как IOError:
try:
with open('file.txt', 'w', encoding='utf-8') as file:
file.write(modified_data)
except IOError:
print("Ошибка записи в файл")4. Ошибки, связанные с операциями над строками
Если необходимо удалить определенные символы из данных, можно столкнуться с ошибками, связанными с типами данных. Убедитесь, что данные, которые вы пытаетесь обрабатывать, являются строками. Если работаем с бинарными файлами, обработка строк может вызвать ошибку. В таких случаях стоит конвертировать данные в строковый формат или работать с бинарными данными напрямую.
5. Обработка ошибок при удалении символов
При удалении символов из строки можно столкнуться с неправильным использованием метода replace() или попыткой удалить символ, которого нет в строке. Чтобы избежать неожиданных результатов, всегда проверяйте содержимое данных перед выполнением операций:
if target_symbol in data:
data = data.replace(target_symbol, '')
else:
print(f"Символ {target_symbol} не найден в данных")Дополнительные проверки, например, на пустоту строки или корректность символов, помогут избежать ошибок во время выполнения программы.
6. Ошибки при работе с большими файлами
При работе с большими файлами стоит учитывать возможность возникновения ошибки из-за недостаточной памяти. Использование построчной обработки данных позволяет избежать загрузки всего файла в память. Пример:
with open('file.txt', 'r', encoding='utf-8') as file:
for line in file:
modified_line = line.replace(target_symbol, '')
# Запись в новый файл или дальнейшая обработка строкиТакже важно следить за тем, чтобы программа не зацикливалась на ошибках и продолжала работать, не требуя вмешательства пользователя.
Применение данных рекомендаций позволит минимизировать риски и сделать процесс удаления символов из файла безопасным и эффективным.
Вопрос-ответ:
Как можно удалить символы из текста в файле с помощью Python?
Для удаления символов из текста в .txt файле с использованием Python можно воспользоваться стандартными методами работы с файлами и строками. Например, прочитать файл, пройтись по строкам, удаляя ненужные символы, а затем записать обновленный текст обратно в файл. Можно использовать методы как `.replace()` для замены символов или регулярные выражения для более сложных случаев. Пример простого кода:
Можно ли удалить все пробелы из текста в файле с помощью Python?
Да, для этого можно использовать метод `.replace()` или регулярные выражения. Например, если нужно удалить все пробелы в файле, можно прочитать содержимое, заменить все пробелы на пустую строку, а затем записать результат обратно в файл. Код для этого будет выглядеть так:
Как удалить несколько типов символов, например, пробелы и знаки препинания, из файла с помощью Python?
Для удаления нескольких типов символов, например, пробелов и знаков препинания, лучше использовать регулярные выражения. Библиотека `re` позволяет искать и заменять несколько символов одновременно. Вот пример кода, который удаляет все пробелы и знаки препинания из текста:
Как обработать файл построчно, удаляя символы из каждой строки?
Для этого можно открыть файл в режиме чтения и поочередно обрабатывать каждую строку. Внутри цикла для каждой строки можно удалить ненужные символы, например, с помощью метода `.replace()` или регулярных выражений, и затем записать результат обратно в новый файл. Пример:
Как использовать регулярные выражения для удаления символов в файле?
Регулярные выражения позволяют гораздо гибче удалять символы по заданному шаблону. Для этого нужно использовать модуль `re`. Например, если нужно удалить все цифры из текста, можно использовать такой код: