Для взаимодействия с SQL базами данных в Python существует несколько библиотек, среди которых sqlite3, MySQL Connector и SQLAlchemy. Каждая из них имеет свои особенности, однако, вне зависимости от выбора, процесс добавления данных в таблицы обычно сводится к нескольким ключевым операциям: установлению соединения, подготовке SQL-запроса и его выполнению.
Основным элементом для работы с базами данных в Python является библиотека, позволяющая установить подключение к серверу. Например, для работы с SQLite достаточно использовать стандартный модуль sqlite3, который не требует установки дополнительных пакетов. В случае с MySQL или PostgreSQL необходимо установить сторонние пакеты, такие как mysql-connector-python или psycopg2, для реализации соединения с базой данных.
После установления соединения следующий этап – это формирование SQL-запроса для добавления данных. Здесь важно соблюдать два ключевых момента: правильное использование параметризированных запросов для предотвращения SQL-инъекций и корректная обработка типов данных. Важно использовать параметризацию запросов, чтобы избежать ошибок и повысить безопасность приложения. Вместо того чтобы вставлять значения напрямую в строку запроса, используются плейсхолдеры, которые заменяются на данные при выполнении запроса.
Чтобы корректно вставить данные, можно использовать метод execute() для выполнения SQL-запросов. После этого не забудьте вызвать commit(), чтобы изменения были сохранены в базе данных. Важно помнить, что некоторые базы данных, например, MySQL, требуют явного подтверждения транзакции, в то время как SQLite обрабатывает это автоматически после завершения работы с соединением.
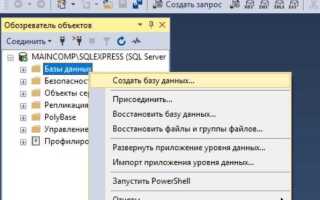
Выбор и установка библиотеки для подключения к SQL
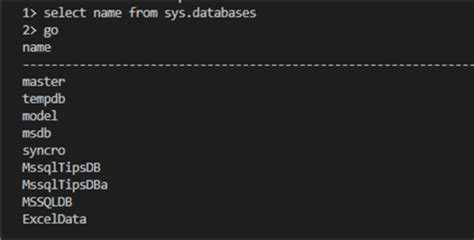
Для подключения Python к SQL-базе данных требуется специализированная библиотека. Наиболее популярные решения включают:
- MySQL –
mysql-connector-python,PyMySQL,MySQLdb - PostgreSQL –
psycopg2,asyncpg - SQLite –
sqlite3(встроенная в Python) - Microsoft SQL Server –
pyodbc,pymssql
Для каждой СУБД есть оптимизированные библиотеки, которые имеют свои особенности и возможности. Выбор зависит от используемой базы данных и требуемой функциональности.
Пример установки для каждой из библиотек:
- MySQL:
pip install mysql-connector-python - PostgreSQL:
pip install psycopg2 - SQLite:
sqlite3(предустановлен в Python) - Microsoft SQL Server:
pip install pyodbc
После установки библиотеки можно подключаться к базе данных и выполнять SQL-запросы. Важно выбрать правильную библиотеку, которая поддерживает все требуемые функции и гарантирует стабильную работу с вашим SQL-сервером.
Настройка строки подключения к базе данных
Основные компоненты строки подключения:
- Имя хоста – адрес сервера базы данных. Это может быть IP-адрес или доменное имя.
- Порт – номер порта, на котором слушает сервер базы данных. Для PostgreSQL это 5432, для MySQL – 3306.
- Имя базы данных – конкретная база данных, к которой осуществляется подключение.
- Пользователь – имя пользователя, под которым происходит подключение к базе данных.
- Пароль – пароль для аутентификации пользователя.
- Дополнительные параметры – могут включать параметры безопасности, тайм-ауты или настройки кодировки.
Пример строки подключения для PostgreSQL с использованием psycopg2:
dbname='mydatabase' user='myuser' password='mypassword' host='localhost' port='5432'
Для MySQL с использованием pymysql:
host='localhost', user='myuser', password='mypassword', database='mydatabase'
Строки подключения могут быть специфичными для каждой СУБД, и важно знать, как правильно их формировать для нужной базы данных. Например, для подключения к удаленному серверу важно использовать правильный IP-адрес или доменное имя, а также удостовериться, что порт доступен для внешних соединений.
Рекомендации по безопасности:
- Не храните пароли в строках подключения в открытом виде, особенно в публичных репозиториях. Используйте переменные окружения или конфигурационные файлы.
- При использовании пароля в строке подключения, предпочтительнее использовать SSL-соединение для защиты данных в пути.
- Периодически меняйте пароли и убедитесь в наличии актуальных прав доступа для используемого пользователя.
Для управления строками подключения в проектах рекомендуется использовать файлы конфигурации или переменные окружения, чтобы избежать дублирования данных и обеспечить гибкость при развертывании на разных серверах.
Создание таблицы в SQL через Python-скрипт
Первым шагом необходимо подключиться к базе данных. Если база данных не существует, она будет создана автоматически:
import sqlite3
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
Для создания таблицы используется SQL-запрос CREATE TABLE, который должен быть передан в метод execute. Например, чтобы создать таблицу с названием users и тремя полями (id, name, age), можно выполнить следующий код:
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER NOT NULL
);
''')
conn.commit()
В запросе указаны следующие элементы:
- id – поле с уникальным идентификатором. Тип данных INTEGER с атрибутом PRIMARY KEY AUTOINCREMENT автоматически увеличивает значение при добавлении новых записей.
- name – текстовое поле, в котором хранится имя пользователя. Атрибут NOT NULL означает, что значение этого поля обязательно для заполнения.
- age – поле для хранения возраста пользователя, также с ограничением NOT NULL.
После выполнения запроса таблица будет создана, если она ещё не существует. Важно помнить, что при использовании CREATE TABLE IF NOT EXISTS можно избежать ошибок при попытке создать уже существующую таблицу.
Для успешного завершения операции необходимо выполнить commit(), чтобы изменения были сохранены в базе данных. Если этого не сделать, таблица не будет создана.
Когда таблица создана, важно закрыть соединение с базой данных:
conn.close()
Этот процесс создания таблицы можно адаптировать под любые нужды, изменяя поля и их типы данных в запросе. Главное – помнить о правилах именования и типах данных для каждого поля в таблице.
Формирование SQL-запроса INSERT с параметрами
При работе с базой данных через Python использование параметризованных запросов позволяет избежать уязвимостей, связанных с SQL-инъекциями, и улучшить производительность. Параметризованный запрос вставки данных (INSERT) строится с использованием заполнителей, таких как вопросительные знаки или именованные параметры.
В Python для выполнения параметризованных запросов чаще всего используется библиотека sqlite3, которая поддерживает как позиционные, так и именованные параметры.
Пример формирования запроса с позиционными параметрами:
import sqlite3
connection = sqlite3.connect('database.db')
cursor = connection.cursor()
query = "INSERT INTO users (name, age, email) VALUES (?, ?, ?)"
data = ('John Doe', 30, 'john.doe@example.com')
cursor.execute(query, data)
connection.commit()
connection.close()
В этом примере используются знаки вопроса ? в качестве заполнителей для значений, которые будут подставлены в запрос. Параметры передаются в виде кортежа, порядок значений в котором соответствует порядку placeholders в SQL-запросе.
Для именованных параметров используется синтаксис с двоеточием перед именем параметра. Это удобно, когда параметры запроса имеют смысловые имена, что улучшает читаемость кода.
Пример запроса с именованными параметрами:
query = "INSERT INTO users (name, age, email) VALUES (:name, :age, :email)"
data = {'name': 'John Doe', 'age': 30, 'email': 'john.doe@example.com'}
cursor.execute(query, data)
connection.commit()
connection.close()
Здесь вместо символов ? использованы именованные параметры :name, :age и :email. Параметры передаются в виде словаря, где ключи соответствуют именам параметров в запросе.
Важно помнить, что использование параметризованных запросов способствует защите от SQL-инъекций, так как параметры передаются в виде данных, а не как часть строки SQL-запроса, исключая возможность выполнения произвольных команд.
Передача данных из Python-структур в базу
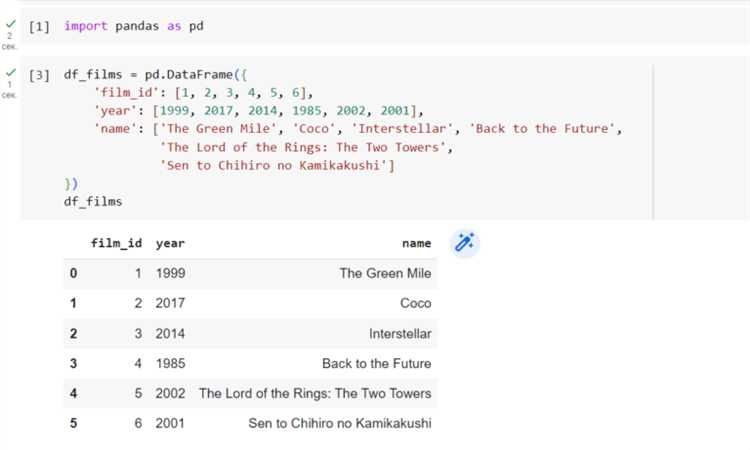
Для передачи данных из Python-структур в базу данных используется интерфейс Python с СУБД, обычно через библиотеки как `sqlite3`, `psycopg2`, `pymysql` и другие. Каждый тип данных Python, будь то числа, строки, списки или словари, имеет свой способ преобразования в формат, который воспринимается базой данных.
Основной процесс передачи данных начинается с установления соединения с базой. Например, с использованием библиотеки `sqlite3` можно подключиться следующим образом:
import sqlite3
conn = sqlite3.connect('database.db')
cursor = conn.cursor()
После подключения необходимо подготовить SQL-запрос для вставки данных. Для этого можно использовать параметризацию запросов, что не только предотвращает SQL-инъекции, но и облегчает передачу различных типов данных. Рассмотрим пример с передачей значений из словаря:
data = {'name': 'John', 'age': 30}
query = "INSERT INTO users (name, age) VALUES (:name, :age)"
cursor.execute(query, data)
conn.commit()
Здесь словарь `data` передает значения в SQL-запрос через параметры, обозначенные как `:name` и `:age`. Это позволяет избежать необходимости вручную обрабатывать типы данных и форматирование строк, что снижает вероятность ошибок.
Если передаются более сложные структуры данных, например, списки или кортежи, то также можно воспользоваться параметризацией, преобразуя структуру в формат, который можно легко вставить в таблицу. Например, для вставки нескольких записей:
data_list = [('Alice', 25), ('Bob', 28)]
query = "INSERT INTO users (name, age) VALUES (?, ?)"
cursor.executemany(query, data_list)
conn.commit()
В случае использования других СУБД, например, PostgreSQL с библиотекой `psycopg2`, синтаксис будет немного отличаться, но принцип работы остаётся тот же. Например, для PostgreSQL:
import psycopg2
conn = psycopg2.connect("dbname=test user=postgres password=secret")
cursor = conn.cursor()
data = {'name': 'Eve', 'age': 22}
query = "INSERT INTO users (name, age) VALUES (%(name)s, %(age)s)"
cursor.execute(query, data)
conn.commit()
При передаче данных из более сложных структур, таких как вложенные списки или словари, рекомендуется перед тем как отправить их в базу данных, приводить их к плоскому виду, чтобы избежать излишней сложности запросов и увеличения времени выполнения операций.
Не следует забывать об обработке ошибок при вставке данных. Это особенно важно в случае больших объемов данных или при многократных операциях. Использование транзакций, например, через `conn.begin()` или `conn.commit()` (в зависимости от базы), обеспечит атомарность операций и поможет избежать частичных вставок в случае ошибки.
Каждая структура данных требует корректного подхода к сериализации и передаче в базу данных. Использование встроенных возможностей Python и соответствующих библиотек для работы с базами данных гарантирует, что процесс будет эффективным и безопасным.
Обработка ошибок при вставке данных
При работе с библиотеками для взаимодействия с SQL, такими как sqlite3 или psycopg2, чаще всего встречаются следующие ошибки:
- IntegrityError: возникает, когда нарушается целостность данных, например, при попытке вставить дублирующееся значение в уникальное поле.
- OperationalError: может возникнуть при ошибках, связанных с базой данных, например, при невозможности установить соединение с сервером.
- ProgrammingError: возникает, если запрос SQL некорректен, например, из-за ошибки в синтаксисе.
- DataError: возникает при попытке вставить неподобающие данные, например, строку в числовое поле.
Рекомендуется использовать обработку ошибок для каждой вставки данных, чтобы в случае ошибки можно было сделать откат транзакции и избежать частично выполненных операций. В SQL это реализуется с помощью команды ROLLBACK, которая отменяет все изменения в текущей транзакции.
Пример обработки ошибок при вставке данных:
import sqlite3
try:
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
cursor.execute("INSERT INTO users (id, name, age) VALUES (?, ?, ?)", (1, 'Alice', 30))
conn.commit()
except sqlite3.IntegrityError as e:
print(f"Ошибка целостности данных: {e}")
conn.rollback()
except sqlite3.OperationalError as e:
print(f"Ошибка операционной базы данных: {e}")
conn.rollback()
except sqlite3.DataError as e:
print(f"Ошибка данных: {e}")
conn.rollback()
except Exception as e:
print(f"Неизвестная ошибка: {e}")
conn.rollback()
finally:
conn.close()Такой подход позволяет логировать тип ошибки, возвращать подробную информацию и гарантировать, что база данных не окажется в неконсистентном состоянии.
Важно также учитывать, что при массовой вставке данных (например, с использованием executemany()) следует тщательно проверять типы данных и соответствие формата. Ошибки могут быть связаны с неверной подготовкой данных, что необходимо устранять до выполнения запроса.
Для повышения надежности рекомендуется использовать транзакции с явным управлением: начинайте транзакцию перед вставкой данных с помощью BEGIN TRANSACTION и завершайте ее с помощью COMMIT, либо откатывайте изменения в случае возникновения ошибки с помощью ROLLBACK.
Закрытие соединения и сохранение изменений
После выполнения операций с базой данных в Python необходимо правильно закрыть соединение и сохранить изменения. Это важный шаг, поскольку незавершённые транзакции могут привести к потерям данных или блокировкам в базе.
Для начала, важно понимать, что соединение с базой данных работает в контексте транзакции. Пока транзакция не завершена, изменения не сохраняются в базе данных. В Python для работы с базой данных используется библиотека, такая как sqlite3, mysql-connector или psycopg2, в зависимости от типа СУБД. Во всех случаях существуют методы для сохранения изменений и закрытия соединения.
Сохранение изменений происходит с помощью метода commit(). Этот метод фиксирует все изменения, сделанные в рамках текущей транзакции. Если вы работаете с базой данных в режиме автокоммита, метод commit() можно не вызывать, так как изменения будут сохраняться автоматически. Однако, в большинстве случаев рекомендуется явно вызывать commit() для более точного контроля над процессом транзакций.
Пример использования commit():
import sqlite3
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# Выполнение SQL-запроса
cursor.execute("INSERT INTO users (name, age) VALUES ('Иван', 30)")
# Сохранение изменений
conn.commit()
# Закрытие соединения
conn.close()
После сохранения изменений важно закрыть соединение с базой данных. Это освобождает ресурсы и предотвращает возможные утечки памяти. Для этого используется метод close(). В случае работы с множеством соединений, закрытие каждого из них гарантирует корректное завершение всех операций.
Закрытие соединения важно делать всегда, даже если не были выполнены изменения. Это помогает избежать блокировок или других непредвиденных ситуаций, связанных с открытым соединением.
Пример закрытия соединения:
# Закрытие соединения
conn.close()
Если в процессе выполнения операций произошла ошибка, транзакция не будет зафиксирована, если не вызвать commit(). В таких случаях рекомендуется использовать блок try-except, чтобы в случае возникновения ошибки автоматически откатить изменения с помощью метода rollback(). Это гарантирует, что база данных останется в консистентном состоянии.
Пример с использованием rollback():
try:
cursor.execute("INSERT INTO users (name, age) VALUES ('Петр', 25)")
conn.commit()
except Exception as e:
conn.rollback()
print(f"Ошибка: {e}")
finally:
conn.close()
Таким образом, завершение работы с базой данных должно включать вызов commit() для сохранения изменений и close() для закрытия соединения, что обеспечит правильную работу системы и её производительность.