В языке Python подстроки извлекаются с помощью срезов – конструкции, позволяющей точно указать начальную и конечную позицию символов. Срез записывается в квадратных скобках после строки: строка[начало:конец]. Например, выражение «пример»[1:4] вернёт «рим». Начальный индекс включается, а конечный – нет.
Индексация в Python начинается с нуля. При этом можно использовать отрицательные значения: -1 указывает на последний символ строки, -2 – на предпоследний и т.д. Это удобно, если нужно вырезать часть строки с конца, не зная её точной длины.
Если опустить начальный индекс, Python начнёт срез с начала строки. Аналогично, если опустить конечный индекс – срез продлится до конца. Например, строка[:5] вернёт первые пять символов, а строка[3:] – всё начиная с четвёртого символа до конца.
Для сложных сценариев, таких как извлечение подстроки между двумя символами или подстрока по регулярному шаблону, используется модуль re. Функция re.search() позволяет найти первую подходящую подстроку, соответствующую регулярному выражению, а re.findall() – все совпадения. Это особенно полезно при парсинге текстов и извлечении данных.
Если требуется удалить подстроку, используйте метод replace(), указав подстроку и пустую строку в качестве замены. Например, «файл.txt».replace(«.txt», «») вернёт «файл».
Как извлечь подстроку по индексам с помощью срезов
Срезы в Python позволяют извлекать подстроки, указывая начальный и конечный индексы. Формат записи: строка[начало:конец]. Индекс начало включается, конец – нет.
s = "программирование"s[0:6]вернёт"програм"s[6:]вернёт"мирование"– до конца строкиs[:11]вернёт"программиро"– с начала до 10 индексаs[-6:-1]вернёт"аниro"– с конца строки
Если указать шаг: s[::2], подстрока будет сформирована из каждого второго символа.
- Проверяйте, что индексы не выходят за границы:
s[100:]не вызовет ошибку, но вернёт пустую строку. - Используйте отрицательные индексы, чтобы обращаться к символам с конца.
- При step < 0 срез идёт в обратном направлении:
s[10:4:-1]вернёт символы между 10 и 5 индексами в обратном порядке.
Срезы не изменяют исходную строку. Результатом всегда будет новая строка.
Как вырезать подстроку между двумя символами
Для извлечения подстроки, расположенной между двумя заданными символами, применяйте метод str.find() для определения индексов. Например, чтобы получить содержимое между символами '[' и ']':
text = "Пример [подстрока] строки"
start = text.find('[') + 1
end = text.find(']', start)
substring = text[start:end]
Метод find() возвращает индекс первого вхождения. Смещение +1 необходимо, чтобы исключить начальный символ. Убедитесь, что оба символа найдены: проверьте, что start > 0 и end != -1. В противном случае подстрока не будет извлечена корректно.
Если требуется извлекать подстроку между несколькими парами символов в тексте, используйте регулярные выражения:
import re
text = "Код [один], затем [два]"
matches = re.findall(r'\[(.*?)\]', text)
Шаблон r'\[(.*?)\]' ищет непересекающиеся фрагменты между [ и ], включая случаи с несколькими подстроками. Результат – список всех совпадений.
Как получить подстроку до или после определённого слова
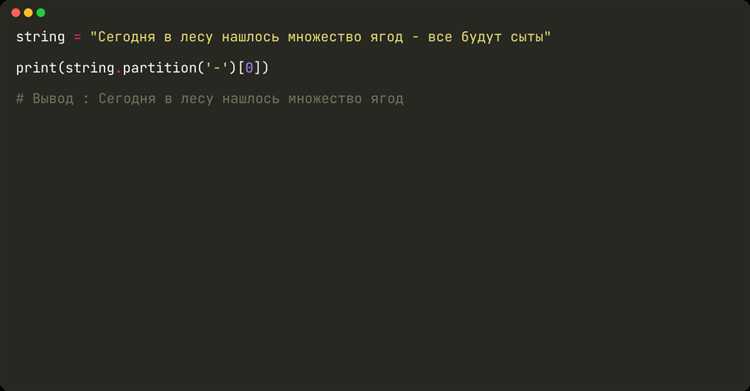
Для извлечения части строки до или после определённого слова используйте методы find() или split(), в зависимости от ситуации.
- До слова: используйте
str.find()для получения индекса начала слова, затем примените срез.
text = "Путь к файлу: C:\\Users\\Admin\\file.txt"
keyword = "C:\\"
index = text.find(keyword)
before = text[:index]
print(before) # Путь к файлу: - После слова: добавьте длину слова к индексу и выполните срез от этой позиции до конца строки.
after = text[index + len(keyword):]
print(after) # Users\Admin\file.txt- Если слово может встречаться несколько раз и нужен последний экземпляр – используйте
rfind().
index = text.rfind("\\")
after = text[index + 1:]
print(after) # file.txt- Если требуется всё между двумя словами – найдите их индексы и выполните срез между ними.
start = text.find("Users")
end = text.find("file")
between = text[start:end]
print(between) # Users\Admin\Обрабатывайте случаи, когда слово не найдено: find() возвращает -1, что может привести к некорректному срезу.
Как удалить подстроку из строки
text = "Привет, мир!"
text = text.replace("мир", "")
Если требуется удалить только первое вхождение подстроки, можно воспользоваться аргументом count, который указывает количество замен:
text = "Привет, мир! Мир!"
text = text.replace("Мир", "", 1)
Другой способ удаления подстроки – использование срезов. Этот метод полезен, когда известно точное местоположение подстроки:
text = "Привет, мир!"
text = text[:7] + text[12:]
Для более сложных задач, таких как удаление подстроки на основе регулярных выражений, можно использовать модуль re. Это полезно, если подстрока имеет сложную структуру или если нужно удалить несколько различных подстрок за один проход:
import re
text = "Привет, мир! Привет, мир!"
text = re.sub("мир", "", text)
Метод re.sub() позволяет удалить все вхождения подстроки, соответствующие регулярному выражению, и применим для более сложных случаев, где нужно учитывать шаблон или вариации подстроки. Важно помнить, что этот метод не изменяет оригинальную строку, а возвращает новую строку с заменами.
Для удаления подстроки на основе индексов в строке, можно также комбинировать методы срезов и поиска индексов через find() или index():
text = "Привет, мир!"
start = text.find("мир")
text = text[:start] + text[start + len("мир"):]
При использовании метода find() важно учитывать, что если подстрока не найдена, будет возвращено значение -1, что стоит учитывать для предотвращения ошибок.
Как извлечь часть строки с помощью регулярных выражений
Для извлечения части строки в Python часто используют модуль re, который позволяет работать с регулярными выражениями. Регулярные выражения позволяют точно указать шаблон для поиска, что значительно расширяет возможности манипуляции строками. Извлечение подстроки возможно с помощью функции re.search(), которая ищет первое совпадение с шаблоном в строке.
Пример извлечения числовой части из строки:
import re
text = "Цена: 2500 рублей"
pattern = r"\d+" # Шаблон для поиска чисел
match = re.search(pattern, text)
if match:
print(match.group()) # Выведет: 2500
Для поиска нескольких совпадений используется функция re.findall(), которая возвращает список всех найденных частей строки, соответствующих шаблону:
matches = re.findall(r"\d+", "Цена: 2500 рублей, скидка: 300")
print(matches) # Выведет: ['2500', '300']
Если нужно извлечь часть строки, обрамленную конкретными символами, можно использовать скобки в регулярном выражении. Например, для извлечения части строки между кавычками:
text = 'Это "важная информация" для всех.'
pattern = r'"(.*?)"' # Захватываем текст между кавычками
match = re.search(pattern, text)
if match:
print(match.group(1)) # Выведет: важная информация
Регулярные выражения также позволяют использовать метасимволы для уточнения поиска. Например, метасимвол \w соответствует любому символу алфавита или цифре, а \s – пробелу или любому другому пробельному символу. Это позволяет искать слова, фразы и даже форматы данных, такие как email-адреса или телефонные номера.
Пример извлечения email-адреса:
text = "Мой email: example@example.com"
pattern = r"\b[\w.-]+@[\w.-]+\.\w{2,4}\b"
match = re.search(pattern, text)
if match:
print(match.group()) # Выведет: example@example.com
Важно помнить, что регулярные выражения могут быть не всегда оптимальны для извлечения данных из очень больших строк, так как они могут привести к значительному потреблению ресурсов. Поэтому рекомендуется тщательно выбирать шаблоны для поиска.
Как вырезать подстроку по шаблону с использованием метода split()
Метод split() в Python разбивает строку на части по указанному разделителю, возвращая список. Это полезно для извлечения подстрок, которые соответствуют определенному шаблону, если правильно выбрать разделитель.
Пример использования метода для вырезания подстроки:
text = "Python is great for string manipulation"
result = text.split("is")
print(result) # ['Python ', ' great for string manipulation']
В этом примере строка разделяется по слову "is". Метод возвращает список из двух элементов: все, что до "is", и все, что после.
Если необходимо извлечь подстроку, содержащую конкретный шаблон, можно использовать регулярные выражения с методом split(). Например, для извлечения частей строки, разделенных любым количеством пробелов:
import re
text = "Python is great"
result = re.split(r'\s+', text)
print(result) # ['Python', 'is', 'great']
Здесь регулярное выражение \s+ соответствует одному или нескольким пробелам, что позволяет разделить строку на отдельные слова.
Также можно использовать метод split() для выделения подстрок до и после специфического шаблона, например, для извлечения всего после первого вхождения определенной подстроки:
text = "start:middle:end"
result = text.split(":", 1)
print(result) # ['start', 'middle:end']
Указав ограничение на количество разбиений (в данном примере 1), можно разделить строку только по первому вхождению шаблона.
Как обрабатывать ошибки при неверных индексах среза

При работе с срезами строк в Python можно столкнуться с ошибками, если индексы выходят за допустимые границы. Эти ошибки могут привести к неожиданным результатам или исключениям, если не предусмотрены механизмы обработки таких ситуаций.
Если индекс среза выходит за пределы строки, Python не выбрасывает исключение, а возвращает пустую строку или подстроку. Однако если используется неверный тип индекса или отрицательные значения в местах, где это не предусмотрено, могут возникнуть ошибки. Чтобы избежать этого, можно использовать блоки try-except.
Пример обработки ошибки при неверном индексе:
try:
result = my_string[start:end]
except IndexError:
print("Индекс за пределами строки")
Этот код позволяет отловить ошибку, если индекс среза выходит за допустимые границы. Однако для более сложных случаев, когда индексы могут быть переменными, можно использовать проверку валидности индексов до выполнения среза.
Для предотвращения ошибок лучше всегда проверять, что индексы находятся в пределах длины строки. Например, можно применить функцию len() для сравнения с размерами строки:
if start < len(my_string) and end <= len(my_string):
result = my_string[start:end]
else:
print("Неверные индексы для среза")
Также стоит помнить, что отрицательные индексы в Python используются для обращения к символам с конца строки. Поэтому важно учитывать, что индекс -1 будет ссылаться на последний элемент строки, а индекс -2 – на предпоследний. Если же значение индекса выходит за пределы возможных отрицательных индексов, это также приведет к некорректному срезу.
Еще один способ – использование встроенной функции slice(), которая позволяет контролировать диапазон среза:
s = slice(start, end)
result = my_string[s]
Этот подход более гибкий, так как позволяет вручную задавать поведение при некорректных индексах с помощью дополнительных параметров.
Как работать с подстроками в цикле при обработке списка строк
Когда необходимо обрабатывать список строк и извлекать из них подстроки, циклы становятся эффективным инструментом. Python предоставляет несколько удобных способов работы с подстроками, используя индексирование и срезы.
Использование срезов в цикле: Срезы позволяют быстро извлекать подстроки, указав диапазон индексов. Это полезно, когда нужно извлечь одинаковую часть из каждой строки. Например, если необходимо получить первые 5 символов каждой строки, можно использовать следующий подход:
strings = ["Python", "Java", "C++", "Ruby"]
for string in strings:
substring = string[:5]
print(substring)
Этот код извлечет первые пять символов из каждой строки списка.
Цикл с условием для извлечения подстрок: Если нужно извлекать подстроки только из строк, которые соответствуют определенным условиям, можно использовать условие в цикле. Например, чтобы получить все подстроки длиной больше 3 символов, можно использовать:
strings = ["Python", "Go", "JavaScript", "Rust"]
for string in strings:
if len(string) > 3:
substring = string[:4]
print(substring)
Этот код будет извлекать первые 4 символа только из тех строк, которые содержат больше трех символов.
Использование методов строки в цикле: В Python существует множество встроенных методов для работы с подстроками, например, find() или split(). Метод find() позволяет искать подстроки в строках. Если задача состоит в том, чтобы найти определенную подстроку в строке, можно использовать следующий код:
strings = ["hello world", "hello Python", "hi there"]
for string in strings:
if string.find("hello") != -1:
print(string)
Извлечение подстроки с помощью регулярных выражений: Для более сложных случаев, когда подстроки имеют сложные шаблоны, можно использовать модуль re. Например, чтобы извлечь все подстроки, которые состоят только из цифр, можно воспользоваться следующим кодом:
import re
strings = ["abc123", "456def", "789"]
for string in strings:
result = re.findall(r'\d+', string)
if result:
print(result[0])
При обработке списка строк важно учитывать производительность. Для больших списков строк использование методов поиска и срезов может существенно ускорить процесс, если их применять эффективно, минимизируя количество операций и избегая излишней обработки строк.
Вопрос-ответ:
Как в Python вырезать подстроку из строки?
Для того чтобы вырезать подстроку в Python, можно использовать срезы. Синтаксис среза выглядит так: `строка[начало:конец]`. Например, если у вас есть строка `s = "Hello, World!"`, то подстроку с 0 по 5 можно получить так: `s[0:5]`, что даст результат `"Hello"`. При этом индекс начала среза включается, а индекс конца — нет.
Можно ли использовать отрицательные индексы для вырезания подстроки в Python?
Да, в Python можно использовать отрицательные индексы для работы с срезами. Отрицательные индексы отсчитываются с конца строки. Например, если у вас есть строка `s = "Python"`, то `s[-3:]` вернёт последние 3 символа: `"hon"`. Это позволяет легко извлекать части строк с конца.
Что происходит, если в Python указать неверный диапазон для среза?
Если указать неверный диапазон, например, начало среза больше, чем конец, или индексы выходят за пределы строки, Python не выдаст ошибку. Вместо этого будет возвращён пустой результат. Например, в случае с `s = "Hello"` выражение `s[5:2]` вернёт пустую строку `""`, так как диапазон не имеет смысла.
Можно ли вырезать подстроку из строки с помощью метода `split()`?
Метод `split()` в Python используется для разделения строки на части по определённому разделителю, а не для вырезания подстрок по индексам. Например, строка `s = "apple,banana,cherry"`. Если вы вызовете `s.split(",")`, то получите список: `['apple', 'banana', 'cherry']`. Это не совсем то же самое, что срез, но в некоторых случаях этот метод может быть полезен для извлечения подстрок.
Как вырезать подстроку, начиная с определённого индекса и до конца строки?
Если вам нужно вырезать подстроку, начиная с определённого индекса и до конца строки, достаточно указать только индекс начала в срезе. Например, для строки `s = "Python programming"` выражение `s[7:]` вернёт подстроку, начиная с символа на позиции 7 до конца строки, то есть `"programming"`. Вы можете не указывать индекс конца среза, и тогда он будет по умолчанию равен длине строки.
Как можно вырезать подстроку из строки в Python?
Для того чтобы вырезать подстроку из строки в Python, можно использовать срезы. Например, если у вас есть строка `s = "Привет мир"`, и вы хотите вырезать из неё первые пять символов, можно сделать так: `s[:5]`. В этом случае результатом будет подстрока "Приве". Важно помнить, что индексация в Python начинается с нуля. Если нужно вырезать часть строки с определённого индекса, то можно использовать такой формат: `s[start:end]`, где `start` — это начальная позиция, а `end` — конечная позиция (не включая её). Например, `s[7:10]` даст подстроку "ми".
Можно ли использовать отрицательные индексы для вырезания подстрок в Python?
Да, в Python можно использовать отрицательные индексы для вырезания подстрок. Отрицательные индексы начинают отсчёт с конца строки. Например, если у вас есть строка `s = "Привет мир"`, то `s[-3:]` вырежет последние три символа строки, то есть "мир". Если нужно вырезать подстроку с конца строки, можно комбинировать положительные и отрицательные индексы. Например, `s[2:-2]` вырежет часть строки, начиная с третьего символа и заканчивая двумя символами до конца, давая результат "ивет".