Работа с файлами – одна из базовых задач в программировании. В Python процесс чтения данных из файлов не представляет сложности и может быть выполнен несколькими способами, в зависимости от конкретных требований. Важно понимать, что для эффективного и безопасного извлечения информации из файлов нужно учитывать их тип, структуру и размер. Рассмотрим основные способы чтения текстовых данных в Python.
Для простого чтения текстового файла можно использовать встроенную функцию open(), которая открывает файл и позволяет взаимодействовать с его содержимым. Для чтения содержимого файла построчно, удобно использовать метод readline(), а для извлечения всего содержимого файла – метод read().
Пример:
with open('example.txt', 'r') as file:
content = file.read()
print(content)
Если необходимо обрабатывать большие файлы, то стоит обратить внимание на методы, которые не загружают весь файл в память, например, использование цикла для построчного чтения. Это особенно важно, когда файл занимает значительный объём и может вызвать переполнение памяти при попытке загрузить его полностью.
Открытие текстового файла для чтения в Python
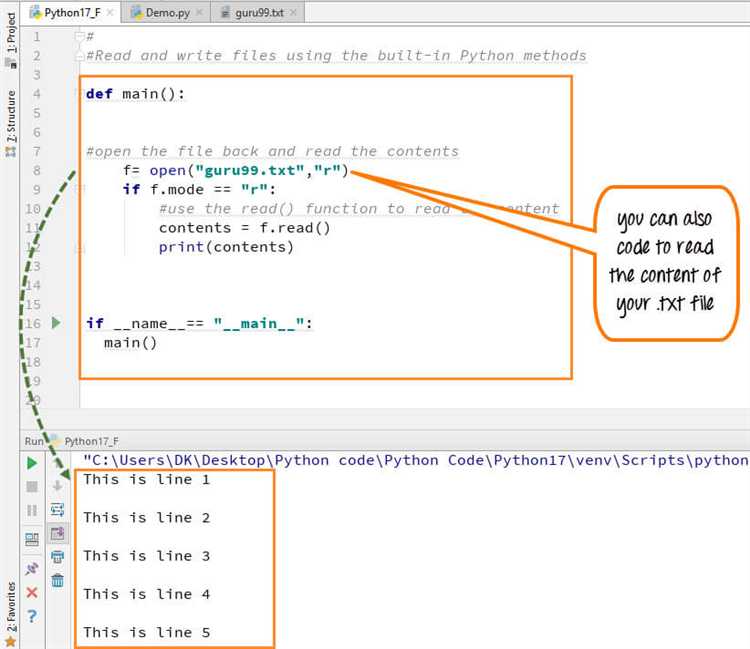
Для открытия текстового файла в Python используется встроенная функция open(). Она позволяет указать путь к файлу и режим открытия. Для чтения файла достаточно использовать режим 'r', который обозначает открытие файла в режиме только для чтения.
Пример открытия файла в режиме чтения:
file = open('example.txt', 'r')После открытия файла важно закрыть его с помощью метода close(), чтобы освободить ресурсы системы. Это можно сделать вручную:
file.close()Рекомендуется использовать конструкцию with для автоматического закрытия файла после завершения работы с ним. Пример:
with open('example.txt', 'r') as file:
content = file.read()В таком случае файл будет автоматически закрыт, когда выполнение выйдет из блока with, что предотвращает возможные ошибки, связанные с незакрытыми файлами.
Функция open() может принимать дополнительные параметры, например, кодировку файла. Если текстовый файл имеет специфическую кодировку, например UTF-8, укажите это в параметрах:
with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()Если файл не существует или возникает ошибка при открытии, Python выбрасывает исключение FileNotFoundError. Чтобы обработать такие ошибки, используйте конструкцию try-except:
try:
with open('example.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден.")Важно помнить, что режим 'r' не позволяет записывать в файл, он предназначен только для чтения. Если требуется открыть файл для записи или добавления данных, следует использовать другие режимы, такие как 'w' или 'a'.
Использование метода read() для получения данных из файла

Метод read() в Python позволяет считывать содержимое файла в виде строки. Это один из базовых методов работы с файлами, который используется, когда требуется загрузить весь текстовый контент целиком или зафиксировать определенный объем данных.
При использовании read() важно понимать, что метод возвращает строку, которая включает все символы из файла, включая символы новой строки. Если файл большой, может возникнуть ситуация, когда данные не поместятся в оперативной памяти. В таких случаях рекомендуется использовать другие методы или управлять объемом данных через аргумент в методе.
Пример использования:
with open('example.txt', 'r') as file:
content = file.read()
print(content)По умолчанию, если метод read() вызывается без параметров, он пытается прочитать весь файл. Если в качестве аргумента передается число, например read(100), то метод вернет только первые 100 символов. Важно помнить, что этот метод не обновляет указатель файла, поэтому при последующих вызовах read() чтение продолжится с того места, где оно было остановлено.
Для файлов больших размеров стоит использовать метод с аргументом, чтобы ограничить размер считываемых данных за раз, например:
with open('large_file.txt', 'r') as file:
chunk = file.read(1024) # Чтение порции в 1024 символа
while chunk:
process(chunk) # Обработка данных
chunk = file.read(1024)После завершения работы с файлом рекомендуется использовать конструкцию with, так как она автоматически закрывает файл, даже если произойдут ошибки в процессе работы с ним.
Важно учитывать, что метод read() не подходит для обработки бинарных данных. Для работы с бинарными файлами следует использовать режим 'rb' при открытии файла, например:
with open('image.jpg', 'rb') as file:
binary_content = file.read()Метод read() удобен для простых операций с небольшими файлами, но для более сложных сценариев, где нужно работать с большим объемом данных, стоит рассмотреть другие методы, такие как readline() или использование буферов.
Чтение файла построчно с помощью метода readline()
Метод `readline()` позволяет читать файл построчно. Этот метод используется для последовательного получения строк из файла, что особенно полезно при работе с большими файлами, где важно ограничить использование памяти. Метод возвращает одну строку за раз, включая символ новой строки `\n` в конце каждой строки.
Пример использования метода `readline()`:
with open('file.txt', 'r') as file:
line = file.readline()
while line:
print(line.strip()) # strip() удаляет лишние пробелы и символы новой строки
line = file.readline()В этом примере файл открывается в режиме чтения. Метод `readline()` вызывается внутри цикла, пока не достигнут конец файла (когда `readline()` вернет пустую строку). Метод удобно использовать в ситуациях, когда нужно обрабатывать строки по одной, не загружая весь файл в память.
Важно помнить, что при использовании `readline()` курсор в файле будет перемещаться по строкам. После выполнения метода курсор будет указывать на начало следующей строки. Для работы с большим количеством строк рекомендуется использовать цикл с `readline()` или применить метод `readlines()`, если требуется загрузить все строки сразу.
При работе с `readline()` следует учитывать возможное наличие пустых строк в файле. Чтобы избежать их обработки, можно использовать метод `strip()`, который удаляет символы новой строки и лишние пробелы с концов строк.
Чтение всех строк файла в список с методом readlines()

Метод readlines() позволяет считывать все строки из файла и сохранять их в список. Каждая строка файла становится отдельным элементом списка. Этот метод полезен, когда необходимо получить доступ к каждой строке для дальнейшей обработки, например, при анализе данных или постобработке текста.
Для использования readlines(), файл необходимо открыть в режиме чтения. После этого метод считывает весь файл построчно. Пример использования:
with open('example.txt', 'r') as file:
lines = file.readlines()
После выполнения кода в переменной lines окажется список, где каждый элемент будет содержать одну строку из файла, включая символы новой строки в конце. Чтобы избавиться от символа новой строки, можно применить метод strip():
lines = [line.strip() for line in lines]
Это удалит все символы новой строки и лишние пробелы по краям каждой строки. Однако при использовании readlines() важно учитывать возможные проблемы с памятью при работе с большими файлами, так как метод загружает все строки файла в память одновременно. В таких случаях лучше обрабатывать файл построчно, используя цикл for, чтобы избежать переполнения памяти.
Если нужно выполнить обработку файла без сохранения всех строк в памяти, рекомендуется использовать следующий подход:
with open('example.txt', 'r') as file:
for line in file:
# обработка строки
Метод readlines() удобен для работы с небольшими файлами, где важно работать с каждой строкой файла по отдельности, сохраняя их в список для дальнейшей обработки или анализа.
Как избежать ошибок при открытии файлов в Python
try:
with open('file.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден.")
Также важно учитывать права доступа. Если файл существует, но программа не имеет разрешений на его чтение или запись, возникнет ошибка PermissionError. В таких случаях также полезен блок try-except для обработки ошибок доступа.
Рекомендуется всегда использовать конструкцию with при открытии файлов. Это автоматически закроет файл, даже если возникла ошибка. Пример:
with open('file.txt', 'r') as file:
content = file.read()
Обратите внимание на правильность пути к файлу. Для работы с абсолютными путями или путями относительно текущей директории используйте модуль os, который позволяет безопасно манипулировать путями:
import os
file_path = os.path.join('folder', 'file.txt')
with open(file_path, 'r') as file:
content = file.read()
Для более безопасного взаимодействия с файлами, когда требуется их запись, используйте режимы 'w' или 'a', но имейте в виду, что они перезаписывают файл, если он уже существует. Если нужно избежать перезаписи, перед открытием файла проверяйте его существование с помощью os.path.exists().
Не забывайте про обработку ошибок при работе с файлами в многозадачности. Если несколько процессов или потоков одновременно пытаются изменить один и тот же файл, это может привести к гонкам. В таких случаях стоит использовать блокировки файлов с помощью модуля `fcntl` или аналогичных инструментов для синхронизации.
Важно всегда проверять корректность путей и прав доступа, а также быть готовым к обработке ошибок, чтобы приложение работало стабильно и безопасно.
Основной способ работы с кодировками при открытии файла – это указание параметра encoding в функции open(). Без явного указания Python использует системную кодировку, что может быть не всегда верно, особенно при работе с текстами на разных языках.
Рассмотрим ключевые моменты:
- UTF-8 – наиболее распространённая кодировка для текстовых файлов, поддерживающая множество языков. Лучше всего использовать её, если файл может содержать символы разных языков.
- CP1251 – часто используется в русскоязычных странах для кодирования кириллицы. Если файл был сохранён в этой кодировке, необходимо указать её при чтении, чтобы избежать ошибок.
- ISO-8859-1 – кодировка, используемая для латиницы, часто применяется в старых файлах или при работе с текстами на западноевропейских языках.
Пример открытия файла с указанием кодировки:
with open('file.txt', 'r', encoding='utf-8') as f:
content = f.read()
print(content)Для определения кодировки файла можно использовать библиотеку chardet. Она помогает автоматически определить, в какой кодировке находится файл:
import chardet
with open('file.txt', 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
encoding = result['encoding']
print(f"Определённая кодировка: {encoding}")Однако автоматическое определение кодировки не всегда бывает точным, особенно если текст содержит символы, характерные для нескольких кодировок. В таких случаях лучше заранее узнать, в какой кодировке сохранён файл, или использовать универсальную кодировку UTF-8.
При работе с большими файлами может быть полезно читать их по частям, чтобы избежать загрузки всего содержимого в память. Это можно сделать с помощью режима r или rb и чтения файла построчно:
with open('file.txt', 'r', encoding='utf-8') as f:
for line in f:
print(line.strip())Также важно помнить, что при записи в файл необходимо учитывать кодировку, чтобы корректно сохранить текст. Для записи в UTF-8 используйте следующий код:
with open('output.txt', 'w', encoding='utf-8') as f:
f.write('Текст для записи в файл')Таким образом, правильная работа с кодировками – это ключ к успешному чтению и записи текстовых данных в Python, особенно если файлы содержат символы разных языков.
Чтение больших файлов: способы оптимизации
Чтение больших файлов может привести к высокой нагрузке на систему, если не использовать правильные методы. Для эффективной работы с большими объемами данных в Python важно учитывать производительность и потребление памяти.
- Использование буферизации: Чтение файла по частям с использованием буферов значительно уменьшает время обработки. Вместо того, чтобы читать весь файл целиком, можно читать его по строкам или блоками фиксированного размера. Метод
open(file, 'r', buffering=...)позволяет задать размер буфера. - Чтение файла построчно: Вместо загрузки всего содержимого в память, читайте файл построчно с помощью
for line in file:. Это особенно полезно при работе с текстовыми файлами, где строки могут быть обрабатываны отдельно. - Использование генераторов: Генераторы позволяют загружать данные по мере необходимости, что снижает использование памяти. Пример:
def read_large_file(filename):with open(filename, 'r') as file:for line in file:yield line. - Многоуровневая загрузка: Для обработки больших файлов можно использовать асинхронное чтение, например, с использованием библиотеки
asyncio. Это позволяет не блокировать выполнение программы, одновременно читая и обрабатывая файл. - Чтение с помощью mmap: Модуль
mmapпозволяет отображать файл в память и работать с ним как с массивом. Это полезно для бинарных файлов и файлов, размер которых превышает объем доступной оперативной памяти. Использованиеmmap.mmap()позволяет избежать необходимости читать файл построчно, что ускоряет процесс. - Оптимизация операций с данными: При чтении больших файлов для анализа данных полезно использовать библиотеки, такие как
pandasилиnumpy, которые эффективно работают с большими объемами данных, загружая только нужные части файлов в память. - Параллельная обработка: Использование многозадачности или многопоточности с помощью модуля
concurrent.futuresможет ускорить обработку больших файлов за счет параллельной загрузки и обработки данных. Это особенно актуально для файлов, которые могут быть разделены на независимые части.
Использование этих методов позволяет значительно улучшить производительность при работе с большими файлами и минимизировать потребление памяти. Выбор метода зависит от размера файла, типа данных и специфики задачи.
Закрытие файлов и управление ресурсами после чтения
После завершения работы с файлом в Python важно корректно его закрыть. Это позволяет освободить ресурсы, которые были использованы операционной системой для открытия и работы с файлом. Пренебрежение этим может привести к утечке памяти или блокировке файла для других процессов.
Закрытие файла вручную можно осуществить с помощью метода close(), который закрывает файл, освобождая ресурсы. Например:
file = open('example.txt', 'r')
content = file.read()
file.close()Однако, это подход не всегда безопасен, поскольку если возникнет ошибка до вызова close(), файл останется открытым. Чтобы избежать таких ситуаций, рекомендуется использовать контекстный менеджер.
Контекстный менеджер автоматически закрывает файл после завершения блока кода, даже если произошло исключение. Для этого используется конструкция with:
with open('example.txt', 'r') as file:
content = file.read()В данном примере файл будет автоматически закрыт по выходу из блока with, что исключает необходимость вручную вызывать метод close() и гарантирует корректное завершение работы с файлом.
Использование контекстного менеджера улучшает читаемость кода и упрощает управление ресурсами, предотвращая возможные ошибки, связанные с забытым закрытием файлов. Это особенно важно при работе с большим количеством данных или файлов, когда ресурсы ограничены.
В случае работы с несколькими файлами можно использовать несколько контекстных менеджеров, разделяя их запятой:
with open('file1.txt', 'r') as file1, open('file2.txt', 'r') as file2:
content1 = file1.read()
content2 = file2.read()Такой подход позволяет избежать лишних строк кода и делает программу более компактной и эффективной.
Правильное управление файлами и ресурсами помогает избежать ошибок в программе и обеспечить стабильную работу приложений, которые работают с большим объемом данных или долгое время. Использование контекстных менеджеров – это оптимальный способ работы с файлами в Python.