

Чтобы получить полное содержимое сайта, недостаточно скачать одну страницу. Многие сайты разбивают контент на пагинированные списки, вложенные категории или динамически генерируемые URL. Для сбора всех данных потребуется анализ структуры ссылок и автоматизация переходов между страницами.
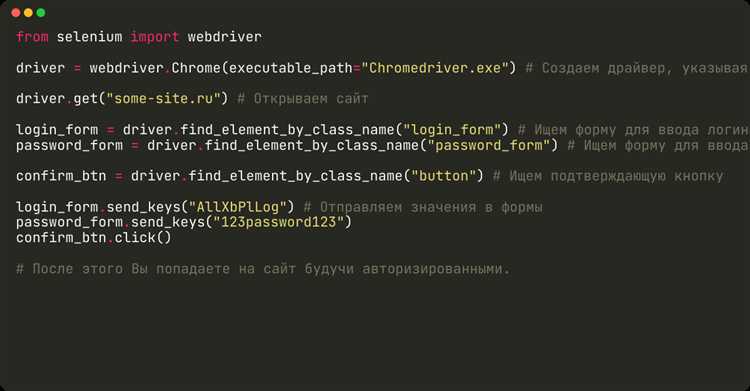
Python предоставляет несколько библиотек для решения этой задачи. requests используется для выполнения HTTP-запросов. BeautifulSoup или lxml позволяют извлекать нужные элементы из HTML. Для обхода JavaScript-зависимых сайтов применяют Selenium или Playwright, что позволяет взаимодействовать со страницей как в браузере.
Если структура URL предсказуема (например, постраничная навигация с параметром ?page=1), достаточно определить максимальное значение и последовательно отправлять запросы. Если ссылки на другие страницы доступны только через элементы на текущей странице, сначала нужно спарсить ссылки, а затем пройтись по ним. Для этого удобно использовать рекурсивный обход с учетом фильтрации по домену и игнорированием повторов.
При парсинге большого количества страниц стоит учитывать ограничения сайта: устанавливать задержки между запросами, использовать заголовки User-Agent и обрабатывать коды ответа сервера. Некоторые сайты могут блокировать подозрительную активность, поэтому важна реализация механизма повторных попыток и прокси-серверов.
Перед запуском необходимо определить цель парсинга: какие данные нужны, где они находятся, как часто обновляются. Это поможет сократить число запросов и упростит последующую обработку данных.
Как выбрать библиотеку для парсинга: BeautifulSoup или Scrapy?
Выбор между BeautifulSoup и Scrapy зависит от задач и требований к проекту. BeautifulSoup подходит для простых и одноразовых задач. Она не обрабатывает запросы и не работает асинхронно – её обычно комбинируют с requests. Scrapy – фреймворк, который сам выполняет запросы, обрабатывает редиректы, кэширует ответы и может работать асинхронно через Twisted.
Если нужно пройтись по десяткам или сотням страниц с одинаковой структурой и собрать данные без сложных условий, подойдёт BeautifulSoup. При необходимости авторизации, обработки JavaScript, повторных переходов по ссылкам или ограничения частоты запросов – Scrapy будет предпочтительнее.
Scrapy использует модели Item и пайплайны, позволяя структурировать код и обрабатывать данные после парсинга. Также поддерживает расширения, настройки логов, middleware и подключение прокси. BeautifulSoup проще, но придётся писать всё вручную: обход страниц, обработку ошибок, сохранение данных.
Сравнение ключевых характеристик:
| Критерий | BeautifulSoup | Scrapy |
|---|---|---|
| Работа с HTML | Да | Да |
| Отправка HTTP-запросов | Нет (нужен requests) | Да |
| Асинхронность | Нет | Да |
| Поддержка пайплайнов | Нет | Да |
| Порог входа | Низкий | Средний |
| Гибкость настройки | Минимальная | Высокая |
Для небольших скриптов, разового извлечения данных или обучения – BeautifulSoup. Для стабильного сбора данных с логикой, обработкой ошибок и масштабируемостью – Scrapy.
Как получить список всех URL на сайте с помощью Python?
Для получения списка всех URL сайта чаще всего используют обход ссылок, начиная с главной страницы. Один из базовых подходов – использовать библиотеку requests для загрузки HTML и BeautifulSoup для извлечения ссылок. Также необходима очередь для управления посещёнными и непосещёнными страницами.
Пример минимального кода:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
start_url = "https://example.com"
visited = set()
to_visit = {start_url}
while to_visit:
url = to_visit.pop()
if url in visited:
continue
try:
response = requests.get(url, timeout=5)
visited.add(url)
soup = BeautifulSoup(response.text, "html.parser")
for tag in soup.find_all("a", href=True):
link = urljoin(url, tag["href"])
parsed = urlparse(link)
if parsed.netloc == urlparse(start_url).netloc:
if link not in visited:
to_visit.add(link)
except requests.RequestException:
continue
for link in visited:
print(link)Фильтрация по домену исключает внешние сайты. Для ускорения обхода можно использовать многопоточность через concurrent.futures. Для сайтов с динамической загрузкой контента потребуется Selenium или Playwright, так как requests не выполняет JavaScript. Если сайт имеет карту сайта (sitemap.xml), сначала стоит попробовать получить список URL оттуда.
Пример для sitemap:
import requests
from xml.etree import ElementTree
sitemap_url = "https://example.com/sitemap.xml"
response = requests.get(sitemap_url)
root = ElementTree.fromstring(response.content)
for url in root.findall(".//{http://www.sitemaps.org/schemas/sitemap/0.9}loc"):
print(url.text)Как обрабатывать пагинацию и переходить между страницами сайта?
Для обработки пагинации нужно определить, как сайт реализует переход между страницами. Чаще всего URL содержит параметр страницы, например: example.com/page=2. В этом случае достаточно изменить значение параметра в цикле:
for page in range(1, 11):
url = f"https://example.com/page={page}"
response = requests.get(url)
# обработка responseЕсли ссылки на следующие страницы встроены в HTML, необходимо распарсить их с помощью BeautifulSoup. Например:
soup = BeautifulSoup(response.text, 'html.parser')
next_link = soup.find('a', text='Next')
if next_link:
next_url = next_link['href']Иногда ссылка на следующую страницу представлена как кнопка или элемент без прямого URL. В таких случаях используется JavaScript, и данные подгружаются через запросы к API. Необходимо изучить сетевую активность в инструментах разработчика браузера и повторить соответствующий запрос:
response = requests.get("https://example.com/api/items?page=2")Если сайт использует POST-запросы для перехода по страницам, их нужно воспроизвести с теми же параметрами:
payload = {'page': 2}
response = requests.post("https://example.com/data", data=payload)Для остановки парсинга используйте проверку наличия следующей страницы или сравнивайте содержимое: если страница пустая или дублирует предыдущую, цикл прекращается.
Избегайте слепого перебора. Проверяйте код ответа, валидность содержимого и корректность URL. Если сайт защищён от скрапинга, добавляйте заголовки User-Agent и соблюдайте паузы между запросами.
Как управлять задержками между запросами, чтобы не заблокировали доступ?

Если сайт не предоставляет API и используется прямой парсинг HTML, важно минимизировать вероятность блокировки. Серверы часто ограничивают количество запросов с одного IP или User-Agent за определённое время. Игнорирование этих ограничений может привести к блокировке доступа или получению искажённых данных.
- Используйте
time.sleep()для пауз между запросами. Значение задержки должно быть не меньше 1–2 секунд. Для сайтов с жёсткой политикой – от 5 секунд и выше. - Вместо фиксированных интервалов применяйте случайные задержки:
sleep(random.uniform(1, 3)). Это снижает вероятность выявления скрипта по паттернам активности. - Избегайте одновременных запросов к множеству страниц. Даже с прокси это может привести к блокировке. Используйте очереди и поэтапную обработку.
- Не парсьте весь сайт сразу. Разбивайте задачу на части и запускайте сбор данных с интервалом в несколько часов или дней.
- Настраивайте заголовок
User-Agent, имитируя поведение браузеров. Повторяющийся или отсутствующийUser-Agentповышает риск блокировки. - Проверяйте ответ сервера: коды 429 и 403 – сигнал, что нужно увеличить задержки или сменить стратегию.
- Следите за cookie и другими параметрами сессии. Их отсутствие или несогласованность тоже может привести к ограничениям.
Дополнительно рекомендуется логировать время, URL и код ответа для каждого запроса. Это поможет оперативно выявлять проблемы и корректировать интервалы между обращениями к серверу.
Как извлекать и сохранять данные с разных типов страниц сайта?

При парсинге сайта важно учитывать различия в структуре страниц. Страницы каталога, карточки товаров, новости, статьи и поисковая выдача требуют разных подходов к извлечению данных.
- Каталог: извлекаются ссылки на карточки, названия позиций, цены, фильтры. Используйте `requests` и `BeautifulSoup`, обращая внимание на пагинацию. XPath или CSS-селекторы должны быть устойчивыми к изменению порядка элементов.
- Карточки товаров: нужные данные – название, описание, характеристики, изображения. Для изображений лучше использовать `urljoin` из `urllib.parse` и сохранять через `requests.get(url).content` в файл. Характеристики удобно сохранять в виде словаря.
- Поисковая выдача: параметры запроса (GET или POST) можно зафиксировать через браузерные инструменты разработчика. Для динамической подгрузки применяют `requests` с передачей параметров или `Selenium`, если данные появляются только после выполнения JavaScript.
- Статьи и новости: основное – заголовок, дата, текст. Содержимое часто находится внутри одного блока, выделенного классом. Очистка от HTML-тегов выполняется через `.get_text(strip=True)` или `lxml.html.clean`.
Для сохранения используйте:
- JSON: подходит для структурированных данных. Сохраняется через `json.dump()` с указанием `ensure_ascii=False`.
- CSV: для табличных данных. Используйте модуль `csv`, соблюдая экранирование символов-разделителей.
- Базы данных: `sqlite3` или `SQLAlchemy` при необходимости последующей фильтрации или анализа.
- Файлы: текстовые данные удобно сохранять в `.txt` или `.md`, используя UTF-8. Изображения – в `jpg` или `png`, формируя уникальные имена на основе хэшей или идентификаторов.
При работе с разными страницами избегайте жёсткого связывания кода с конкретной структурой HTML. Регулярно проверяйте изменения в шаблонах страниц и тестируйте выборки на малых объёмах данных перед массовым сбором.
Как настроить автоматическое обновление парсинга с учетом изменений на сайте?
Чтобы избежать избыточного парсинга и снизить нагрузку на сайт, нужно отслеживать только изменённые страницы. Это можно реализовать с помощью хранения хэшей содержимого или временных меток последнего обновления.
1. Отслеживание изменений по ETag или Last-Modified
Многие сайты возвращают заголовки ETag и Last-Modified. Их можно сохранить при первом запросе и сравнивать при последующих. Если сервер вернул статус 304 Not Modified, повторный парсинг не требуется:
headers = {'If-None-Match': saved_etag}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# Страница обновлена
elif response.status_code == 304:
# Без изменений
2. Хэширование содержимого
Если заголовки отсутствуют, создаётся хэш содержимого страницы (например, MD5 или SHA-256) и сравнивается с предыдущим:
import hashlib
content = response.text
current_hash = hashlib.sha256(content.encode()).hexdigest()
if current_hash != saved_hash:
# Страница изменилась
3. Использование RSS или sitemap.xml
Если сайт предоставляет RSS или актуальный sitemap.xml, можно извлекать только новые или обновлённые URL:
import xml.etree.ElementTree as ET
tree = ET.fromstring(sitemap_xml)
for url in tree.findall('.//{*}url'):
loc = url.find('{*}loc').text
lastmod = url.find('{*}lastmod')
if lastmod is not None and lastmod.text > saved_lastmod[loc]:
# Добавить в очередь на парсинг
4. Планировщик задач
Для запуска парсинга по расписанию используйте cron (Linux/macOS) или Task Scheduler (Windows). Пример cron-задания для запуска скрипта каждый час:
0 * * * * /usr/bin/python3 /home/user/parser.py5. Хранилище состояния
Хэши, ETag, метки времени и список URL нужно сохранять в файле или базе данных. Для небольших проектов подходит SQLite:
import sqlite3
conn = sqlite3.connect('parser_state.db')
conn.execute('CREATE TABLE IF NOT EXISTS pages (url TEXT PRIMARY KEY, hash TEXT, last_checked TEXT)')





