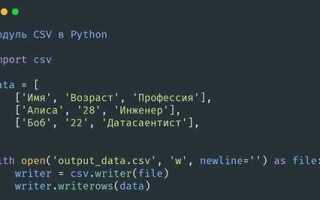
Работа с данными в Python часто включает преобразование объектов в различные форматы для дальнейшего использования. Одним из популярных форматов для хранения табличных данных является CSV. Если у вас есть словарь, и вы хотите экспортировать его в этот формат, Python предоставляет несколько простых и эффективных способов для выполнения этой задачи.
Для начала стоит отметить, что словарь в Python представляет собой набор пар ключ-значение. При сохранении словаря в файл CSV важно правильно структурировать данные. Обычно каждый ключ в словаре становится заголовком столбца, а значения – строками в этих столбцах.
Основной инструмент для работы с CSV файлами в Python – это встроенный модуль csv. Он позволяет легко записывать данные в CSV файлы, не требуя дополнительных библиотек. Модуль имеет методы, которые автоматизируют процесс форматирования и записи данных в таблицу. Применяя их, можно избежать ручной обработки строк и разделителей.
Для сохранения словаря в CSV файл потребуется преобразовать его в структуру, удобную для записи: список списков или список словарей. Один из способов – использование csv.DictWriter, который автоматически обрабатывает ключи словаря как заголовки столбцов. Это делает процесс записи более интуитивно понятным и уменьшает вероятность ошибок.
В этой статье мы подробно разберем, как с помощью простых команд сохранить словарь в файл CSV, и рассмотрим несколько примеров, которые помогут вам легко выполнить эту задачу в реальных проектах.
Подготовка данных: как создать словарь для записи в CSV
Для того чтобы правильно подготовить словарь, следуйте этим рекомендациям:
- Определите ключи словаря: ключи должны быть уникальными и четко отражать данные, которые будут записаны в соответствующие столбцы CSV файла. Например, если вы работаете с информацией о студентах, то ключами могут быть «Имя», «Возраст», «Оценки».
- Убедитесь в согласованности данных: все значения в словаре должны быть однотипными и соответствовать типу данных, который будет ожидаться в CSV файле. Например, для столбца «Возраст» должны быть только целые числа, а для «Имени» – строки.
- Создайте данные для каждого ключа: для каждого ключа нужно подготовить список или другой контейнер данных, соответствующий его типу. Например, если для ключа «Имя» у вас список студентов, то для «Оценок» это может быть список оценок каждого студента.
- Проверьте длину всех значений: все списки значений в словаре должны быть одинаковой длины. Если один из списков короче, чем другие, это может привести к ошибкам при записи данных в CSV.
Пример словаря, готового для записи в CSV:
students_data = {
"Имя": ["Иван", "Мария", "Петр"],
"Возраст": [20, 22, 21],
"Оценки": [4, 5, 3]
}
После того как словарь подготовлен, можно переходить к записи его данных в CSV файл с использованием модуля csv.
Использование модуля csv для работы с файлами CSV

Модуль csv в Python предоставляет простой способ для чтения и записи файлов CSV. Он поддерживает работу с разделителями, такими как запятая или точка с запятой, а также позволяет работать с различными типами кодировок. Для записи данных в файл CSV удобно использовать объект csv.writer, а для чтения – csv.reader.
При записи словаря в CSV важно правильно настроить ключи и значения. В Python для этого используется метод writerow, который принимает список или кортеж данных. Чтобы записать данные из словаря, можно преобразовать его в список значений, предварительно указав порядок столбцов в виде списка ключей.
Пример записи словаря в файл CSV:
import csv
data = {"name": "Alice", "age": 30, "city": "Moscow"}
keys = data.keys()
with open('output.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=keys)
writer.writeheader() # Записывает заголовки
writer.writerow(data) # Записывает данные
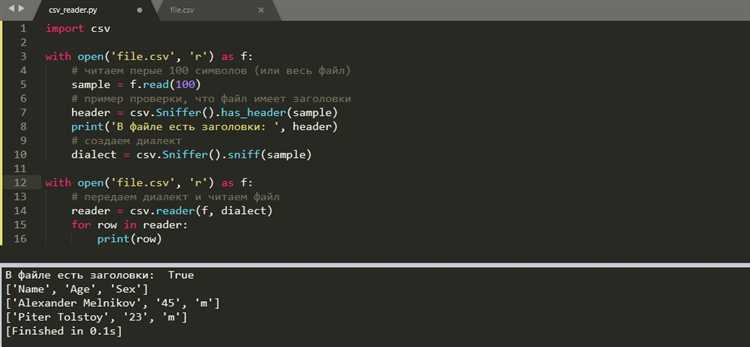
Для эффективного чтения CSV-файлов можно использовать csv.DictReader, который автоматически преобразует каждую строку в словарь, где ключи – это заголовки столбцов.
Пример чтения CSV-файла:
with open('output.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
print(row)
Особое внимание стоит уделить параметру newline='' при открытии файлов. Это важно, чтобы избежать ошибок при записи данных в Windows-среде, где может быть добавлена лишняя пустая строка.
Модуль csv также позволяет работать с пользовательскими разделителями, что удобно при работе с нестандартными CSV-файлами. Для этого нужно указать параметр delimiter.
with open('file.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file, delimiter=';')
for row in reader:
print(row)
Работа с CSV-файлами с помощью модуля csv проста и эффективна, при этом модуль позволяет гибко настроить формат чтения и записи, учитывая особенности данных и структуры файла.
Запись простого словаря в файл CSV
Для записи словаря в CSV-файл в Python можно использовать встроенную библиотеку csv. Для начала определим словарь с ключами и значениями, где ключи будут представлять заголовки столбцов, а значения – данные для записи.
Пример словаря:
data = {'Имя': 'Иван', 'Возраст': 30, 'Город': 'Москва'}
Для записи словаря в файл CSV необходимо открыть файл в режиме записи и использовать csv.DictWriter, который автоматически распознает ключи словаря как заголовки столбцов.
Пример кода:
import csv
data = {'Имя': 'Иван', 'Возраст': 30, 'Город': 'Москва'}
with open('output.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=data.keys())
writer.writeheader()
writer.writerow(data)
В этом примере:
- fieldnames указывает на ключи словаря, которые будут использоваться как заголовки столбцов в CSV-файле.
- writeheader записывает строку заголовков в файл.
- writerow записывает сам словарь в файл.
После выполнения кода будет создан файл output.csv, содержащий следующие данные:
Имя,Возраст,Город
Иван,30,Москва
Если нужно записать несколько строк данных, можно использовать writerows и передать список словарей:
data_list = [
{'Имя': 'Иван', 'Возраст': 30, 'Город': 'Москва'},
{'Имя': 'Мария', 'Возраст': 25, 'Город': 'Санкт-Петербург'}
]
with open('output.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=data_list[0].keys())
writer.writeheader()
writer.writerows(data_list)
Такой подход позволяет эффективно записывать данные в CSV-файл с любым количеством строк, сохраняя структуру словаря.
Как правильно обработать вложенные данные в словаре при записи в CSV
При работе с вложенными словарями в Python необходимо учитывать структуру данных. Когда вы хотите сохранить такие данные в CSV, важно правильно извлечь вложенные элементы, чтобы каждая строка в файле содержала все необходимые значения.
Для начала, если словарь содержит другие словари или списки, нужно решить, как вы будете их представлять в плоском формате CSV. Один из способов – преобразовать вложенные структуры в строковое представление. Например, если словарь включает вложенный словарь с несколькими ключами, его можно представить в виде объединённой строки, где ключи будут разделены определённым символом, например, двоеточием или запятой.
Пример обработки вложенного словаря:
data = {
'id': 1,
'name': 'Alice',
'address': {'street': 'Main St', 'city': 'Wonderland'},
'age': 30
}
В этом случае для записи в CSV можно объединить данные из вложенного словаря «address» в одну строку:
address_str = f"{data['address']['street']}, {data['address']['city']}"
После этого можно записать его как обычное значение в строку CSV. Таким образом, структура данных будет приведена к единому формату, удобному для записи.
Если вложенные данные представляют собой список, например, несколько телефонных номеров, можно выбрать два варианта: либо объединить все элементы списка в одну строку через разделитель, либо создать отдельные столбцы для каждого элемента списка. Пример с объединением:
data = {
'id': 1,
'name': 'Alice',
'phones': ['123-456-7890', '987-654-3210'],
}
phones_str = ', '.join(data['phones'])
Теперь можно добавить это значение в строку CSV, где столбец для телефонов будет содержать строку с номерами, разделёнными запятой.
Если вам нужно более сложное представление данных, можно использовать дополнительные библиотеки для работы с вложенными структурами, такие как Pandas, который предоставляет удобные средства для работы с более сложными форматами и преобразования данных в нужный вид.
Обработка ошибок при записи словаря в файл CSV
Для начала можно использовать конструкцию try-except. Пример обработки ошибок при записи файла выглядит так:
try:
with open('output.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=your_dict.keys())
writer.writeheader()
writer.writerows(your_dict)
except PermissionError:
print("Ошибка доступа: файл используется другим процессом или у вас нет прав на запись.")
except IOError as e:
Если словарь содержит вложенные структуры данных (например, списки или другие словари), их нужно корректно сериализовать перед записью в CSV. В противном случае можно столкнуться с ошибками, связанными с форматом данных. Для таких случаев рекомендуется предварительно приводить данные в строки или использовать дополнительные библиотеки для обработки сложных объектов.
Важно также помнить о корректной настройке кодировки. При записи в CSV-файл по умолчанию используется системная кодировка, что может привести к проблемам при работе с файлами, содержащими символы в других кодировках. В таких случаях стоит явно указать кодировку, например, ‘utf-8’.
Не менее важным моментом является правильная обработка строковых данных, чтобы избежать ошибок с разбором разделителей или кавычек в CSV. Для этого стоит использовать параметры, такие как delimiter или quotechar, в зависимости от потребностей.
Как сохранить словарь с ключами и значениями в разные столбцы CSV
Для сохранения словаря в CSV файл с разделением ключей и значений в разные столбцы используйте библиотеку csv, которая входит в стандартную библиотеку Python.
Чтобы создать CSV файл, в котором ключи словаря будут записаны в одном столбце, а значения – в другом, следуйте простым шагам:
- Импортируйте модуль
csv: - Создайте словарь, который хотите сохранить:
- Откройте файл в режиме записи, используя
with open(): - Создайте объект
csv.writer, который будет записывать данные в файл: - Запишите заголовки столбцов. В данном случае это будет «Ключ» и «Значение»:
- Запишите данные из словаря. Каждый ключ и его соответствующее значение будут записаны в одну строку:
import csvmy_dict = {"name": "John", "age": 30, "city": "New York"}with open('output.csv', mode='w', newline='') as file:writer = csv.writer(file)writer.writerow(['Ключ', 'Значение'])for key, value in my_dict.items():
writer.writerow([key, value])Вот пример полного кода:
import csv
my_dict = {"name": "John", "age": 30, "city": "New York"}
with open('output.csv', mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['Ключ', 'Значение'])
for key, value in my_dict.items():
writer.writerow([key, value])После выполнения этого кода в файле output.csv будет содержаться следующее:
Ключ,Значение
name,John
age,30
city,New YorkЭтот подход гарантирует, что в CSV файл будут записаны два столбца: один для ключей и один для значений, что удобно для дальнейшей обработки данных.
Открытие и проверка сохранённого CSV-файла после записи словаря
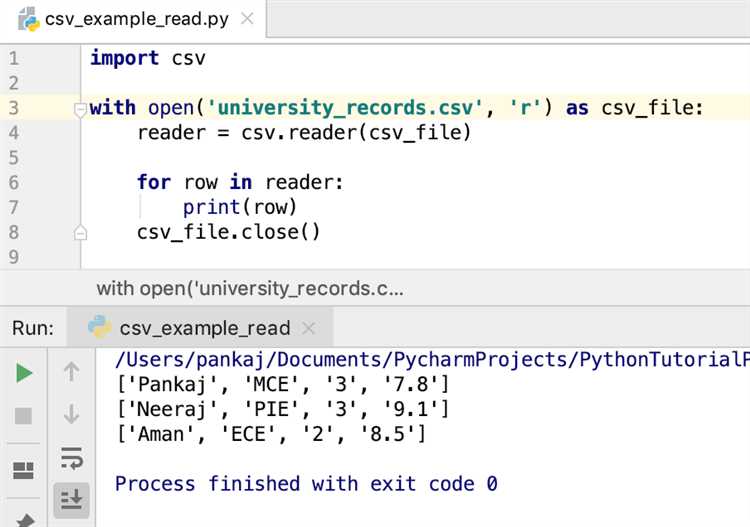
После того как словарь был записан в CSV-файл, важно убедиться в корректности сохранённого содержимого. Для этого откроем файл и проверим его содержимое, используя Python.
Для начала откроем CSV-файл в режиме чтения. Можно использовать стандартный модуль `csv` для этого:
import csv
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)
Этот код откроет файл `data.csv` и выведет каждую строку. Каждая строка будет представлять собой список значений, соответствующих колонкам в CSV.
Важно проверить, что в файле присутствуют все ключи из исходного словаря и что данные в столбцах соответствуют ожидаемым. Если словарь был записан с заголовками, то в первой строке CSV-файла должны быть эти заголовки. Вы можете использовать функцию `next(reader)` для пропуска первой строки, если хотите работать с данными, начиная с второй.
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
headers = next(reader) # пропускаем заголовки
for row in reader:
print(row)
Проверьте, что значения в каждой строке соответствуют типам данных, которые вы ожидаете. Например, если словарь содержал числа, убедитесь, что они остались числами, а не стали строками.
Если нужно проверить, что все ключи присутствуют в файле, можно сравнить их с исходными ключами словаря:
expected_keys = ['name', 'age', 'city']
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
headers = next(reader)
if headers != expected_keys:
print("Предупреждение: заголовки не совпадают.")
Таким образом, вы можете убедиться, что файл был записан корректно и данные сохранили свою структуру. Если что-то не так, можно скорректировать процесс записи или перезаписать файл с нужными параметрами.