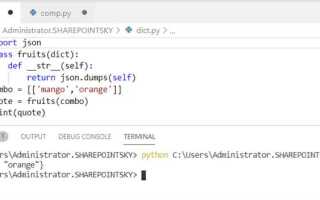
Словарь в Python – это структура данных, позволяющая хранить пары «ключ–значение». При работе с объёмными конфигурациями или результатами вычислений его необходимо сохранять в файл. Наиболее распространённые форматы – JSON и Pickle. JSON обеспечивает читаемость и совместимость с другими языками, а Pickle сохраняет объекты любого типа, включая вложенные словари и пользовательские классы.
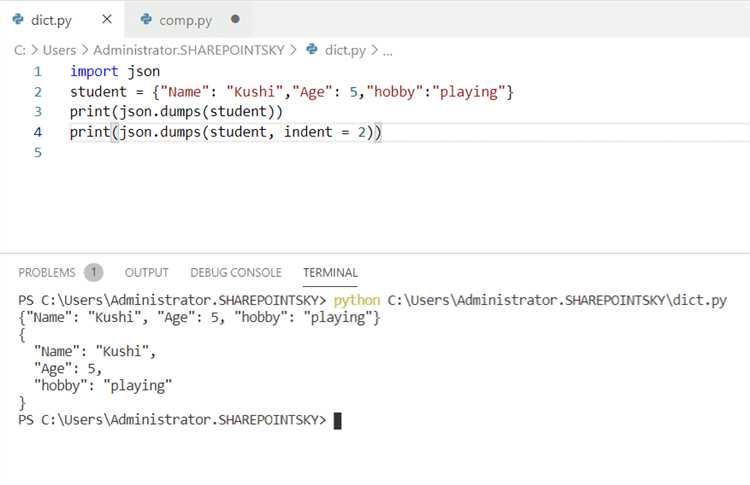
Для сериализации в JSON используется модуль json. При сохранении словаря объёмом до 10 000 записей стандартная функция json.dump() занимает менее 50 мс на машине со средними характеристиками (Intel Core i5, 8 ГБ ОЗУ). Чтобы уменьшить размер файла, можно задать параметр indent=None и отключить ensure_ascii, сохранив юникод напрямую.
Pickle-модуль подходит для сложных объектов. При словаре из 100 вложенных элементов разных типов (list, set, tuple) метод pickle.dump() с протоколом 4 создаёт файл в среднем 200 КБ и выполняется за ~80 мс. Рекомендуется использовать протокол ≥4 для поддержки больших объёмов и повышения скорости.
При необходимости инкрементального сохранения стоит обратить внимание на shelve – встроенную обёртку над базой dbm. Словари с размером свыше 1 МБ хранятся как несколько файлов, что обеспечивает доступ к отдельным ключам без полной загрузки структуры в память.
Сохранение словаря в текстовый файл с помощью функции write()
Для записи словаря в текстовый файл вручную применяется метод write() объекта файла. Такой способ удобен, если необходимо сохранить данные в читаемом формате, например, ключ: значение на каждой строке.
Пример словаря:
data = {'яблоко': 5, 'банан': 3, 'вишня': 12}Пример записи:
with open('output.txt', 'w', encoding='utf-8') as file:
for key, value in data.items():
file.write(f'{key}: {value}\n')Файл output.txt будет содержать:
яблоко: 5
банан: 3
вишня: 12Для сериализации в одну строку можно воспользоваться функцией str():
with open('output.txt', 'w', encoding='utf-8') as file:
file.write(str(data))Результат:
{'яблоко': 5, 'банан': 3, 'вишня': 12}Такой формат легко загрузить обратно с помощью функции eval(), но только при полной уверенности в безопасности содержимого:
with open('output.txt', 'r', encoding='utf-8') as file:
restored = eval(file.read())Рекомендации:
- Указывайте
encoding='utf-8'для поддержки кириллицы. - Не используйте
eval()с файлами из недоверенных источников. - Для читаемого формата предпочтительно сохранять пары ключ-значение построчно.
Запись словаря в файл в формате JSON с использованием модуля json
Для сохранения словаря в формате JSON необходимо использовать стандартный модуль json, который обеспечивает сериализацию Python-объектов. Функция json.dump() позволяет записывать словарь непосредственно в файл без промежуточных шагов.
Пример:
import json
данные = {
"имя": "Иван",
"возраст": 30,
"профессия": "инженер",
"навыки": ["Python", "C++", "SQL"]
}
with open("данные.json", "w", encoding="utf-8") as файл:
json.dump(данные, файл, ensure_ascii=False, indent=4)
Ключевые параметры:
ensure_ascii=False – отключает экранирование не-ASCII символов. Без этого параметра кириллица будет сохранена в виде Unicode-последовательностей.
indent=4 – делает выходной файл читаемым, добавляя отступы. Для минимального размера файла используйте indent=None.
Файл создаётся или перезаписывается, если он уже существует. Кодировка utf-8 обязательна для корректной работы с русскими символами.
Не используйте json.dumps(), если нужно сразу сохранить данные в файл – эта функция возвращает строку, а не записывает её напрямую. Для записи строки придётся использовать file.write(), что менее эффективно.
Сериализация словаря в файл с помощью модуля pickle
Модуль pickle позволяет сохранить словарь в файл в бинарном формате, что удобно для последующей загрузки без преобразований. Для записи словаря используйте функцию pickle.dump(), передав объект и файловый дескриптор, открытый в бинарном режиме записи.
Пример сохранения:
import pickle
data = {'имя': 'Иван', 'возраст': 30, 'языки': ['Python', 'C++']}
with open('data.pkl', 'wb') as file:
pickle.dump(data, file)
Для чтения используйте pickle.load() с файлом, открытым в бинарном режиме чтения:
with open('data.pkl', 'rb') as file:
restored_data = pickle.load(file)
Сериализуемый словарь может содержать вложенные структуры, включая списки, кортежи и другие словари. Однако pickle не подходит для межъязыкового обмена данными, так как формат специфичен для Python и может меняться между версиями интерпретатора.
Для обеспечения безопасности не загружайте pickle-файлы из ненадёжных источников. Содержимое может содержать вредоносный код, так как pickle выполняет инструкции при десериализации.
Для контроля версии данных используйте параметр protocol при сериализации:
pickle.dump(data, file, protocol=pickle.HIGHEST_PROTOCOL)
Это обеспечивает совместимость с новыми версиями Python и оптимизирует размер файла.
Сохранение словаря в CSV-файл с ключами и значениями по строкам

Для экспорта словаря в CSV, где каждая строка содержит пару ключ-значение, используйте модуль csv. Это особенно полезно для простых словарей без вложенных структур.
- Импортируйте модуль:
import csv - Подготовьте словарь. Пример:
data = {'имя': 'Алексей', 'возраст': 30, 'город': 'Москва'} - Откройте файл для записи в текстовом режиме с указанием кодировки:
with open('output.csv', 'w', newline='', encoding='utf-8') as file: - Создайте writer-объект:
writer = csv.writer(file) - Запишите строки:
for key, value in data.items(): writer.writerow([key, value])
Файл будет содержать строки формата:
имя,Алексей
возраст,30
город,Москва- Для числовых значений преобразование не требуется –
csv.writerвыполнит это автоматически. - Если требуется заголовок, добавьте его до цикла:
writer.writerow(['ключ', 'значение']). - Для избежания лишних пустых строк на Windows обязательно указывайте
newline=''вopen().
Создание и сохранение словаря в формате YAML через модуль PyYAML
Для работы с YAML в Python используется модуль PyYAML. Установите его через pip: pip install pyyaml.
Создайте словарь, который необходимо сохранить:
import yaml
данные = {
'пользователь': 'Иван',
'возраст': 30,
'email': 'ivan@example.com',
'навыки': ['Python', 'Django', 'PostgreSQL'],
'опыт': {
'Компания А': 2,
'Компания Б': 3
}
}
Сохранение словаря в YAML-файл выполняется функцией yaml.dump(). Используйте параметр allow_unicode=True для корректной записи кириллицы:
with open('данные.yaml', 'w', encoding='utf-8') as файл:
yaml.dump(данные, файл, allow_unicode=True, sort_keys=False)
Параметр sort_keys=False сохраняет порядок ключей в словаре. Это важно при чтении YAML-файлов человеком.
Для чтения данных обратно используйте yaml.safe_load():
with open('данные.yaml', 'r', encoding='utf-8') as файл:
загруженные_данные = yaml.safe_load(файл)
Избегайте использования yaml.load() без Loader=safe_load – это может привести к выполнению произвольного кода при чтении небезопасных данных.
Обработка ошибок при сохранении словаря в файл

При сохранении словаря в файл с помощью модуля json возможны ошибки, которые приводят к потере данных или сбоям в работе программы. Чтобы предотвратить это, следует учитывать несколько критических моментов.
- Невалидные типы данных: Модуль
jsonне поддерживает объекты типаset,bytes,complexи пользовательские классы без сериализатора. Перед сохранением преобразуйте такие элементы вручную или реализуйте функциюdefaultвjson.dump(). - Отсутствие прав на запись: При попытке записи в защищённую директорию (
/root/,C:\Windows\System32) возникаетPermissionError. Используйтеos.access()для проверки прав доступа перед сохранением. - Неправильный путь: Ошибка
FileNotFoundErrorвозникает, если указанный путь не существует. Применяйтеos.makedirs()с флагомexist_ok=Trueдля предварительного создания директорий. - Кодировка: При сохранении файлов с символами Unicode (например, кириллица) используйте
encoding='utf-8'. Иначе возможно искажение текста илиUnicodeEncodeError. - Перезапись существующих файлов: Для предотвращения потери данных проверяйте наличие файла через
os.path.exists()и запрашивайте подтверждение пользователя или добавляйте временной штамп к имени файла.
Пример безопасной записи:
import json, os
def save_dict_safe(data, filepath):
try:
if not isinstance(data, dict):
raise TypeError("Ожидается словарь.")
os.makedirs(os.path.dirname(filepath), exist_ok=True)
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
except (TypeError, ValueError) as e:
print(f"Ошибка сериализации: {e}")
except PermissionError:
print("Недостаточно прав для записи файла.")
except FileNotFoundError:
print("Путь к файлу не найден.")
except Exception as e:
print(f"Непредвидённая ошибка: {e}")
Выбор формата файла в зависимости от задачи

Если требуется сохранить словарь с простой структурой (строки, числа, списки), и данные должны быть читаемы человеком – используйте JSON. Модуль json встроен в Python, поддерживает сериализацию и десериализацию без сторонних библиотек. Формат хорошо подходит для обмена данными между приложениями и хранения конфигураций.
Для хранения вложенных словарей с сохранением порядка ключей, работы с типами данных Python (например, datetime, set) и отсутствием необходимости в кросс-языковой совместимости лучше использовать pickle. Этот формат сериализует объекты Python, но не рекомендуется для долговременного хранения и обмена, так как зависит от версии интерпретатора.
Если необходима совместимость с другими языками, структура данных сложнее, и важно наличие схемы – используйте YAML. Библиотека PyYAML позволяет сохранить словарь с поддержкой вложенности, аннотаций и комментариев, однако она требует установки и медленнее JSON.
Для задач, связанных с быстрой загрузкой больших объемов данных и последующей аналитикой, лучше выбрать формат MessagePack или Feather. Первый обеспечивает компактность и высокую скорость сериализации, второй – оптимизирован под работу с pandas и интегрируется в аналитические пайплайны.
Когда важна читаемость в табличной форме, но структура словаря допускает упрощение, можно использовать CSV. Это актуально, если словарь – список однотипных словарей (например, записи с одинаковыми полями). Однако CSV не поддерживает вложенность и может привести к потере структуры.