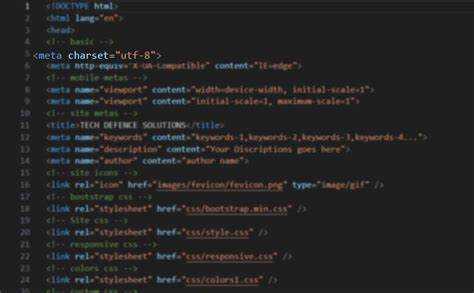
Каждый HTML-документ начинается с определения кодировки символов, и эта строка – <meta charset=»…»> – не просто техническая формальность. Она определяет, как браузер интерпретирует байты текста и во что они превращаются на экране. Ошибочный выбор charset может привести к некорректному отображению символов, особенно если сайт многоязычный.
Наиболее распространённая кодировка – UTF-8. Она поддерживает почти все письменные системы мира и позволяет использовать как латиницу, так и кириллицу без дополнительных настроек. В современных проектах других вариантов практически не остаётся: <meta charset=»UTF-8″> – это стандарт де-факто. Кодировки вроде Windows-1251 применялись в прошлом, но сейчас считаются устаревшими и потенциально проблемными.
Браузеры по умолчанию пытаются угадать кодировку, если она не указана, но такой подход ненадёжен. Всегда следует явно задавать charset в первых 1024 байтах HTML-документа, чтобы избежать ошибок декодирования. Оптимальное место – внутри тега <head>, сразу после тега <title> или даже перед ним.
Если сервер отдает заголовок Content-Type с параметром charset, он может переопределить мета-тег в HTML. Поэтому при конфигурации сервера важно убедиться, что оба источника информации согласованы. Для Apache и Nginx это настраивается в конфигурационных файлах или .htaccess.
Где и как правильно указывать charset в HTML-документе

Метатег <meta charset="..."> должен располагаться внутри секции <head> и как можно ближе к её началу. Это необходимо, чтобы браузер сразу определил кодировку и корректно отобразил содержимое страницы.
На практике используется следующий синтаксис: <meta charset="UTF-8">. Эта запись короче и предпочтительнее по сравнению со старым форматом <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">, который применялся в HTML4.
Кодировка UTF-8 обеспечивает поддержку большинства языков и символов, поэтому рекомендуется использовать именно её. Указание другой кодировки допустимо только при наличии объективных причин, например, если сервер передаёт документы в устаревшей кодировке.
Если метатег charset отсутствует или указан некорректно, браузер может выбрать кодировку автоматически, что приведёт к искажению текста. Чтобы избежать этого, метатег должен быть размещён до любых других элементов, включая <title> и <link>.
Также важно: сохраните сам HTML-файл в той же кодировке, что и указана в <meta charset>. Несовпадение приведёт к отображению «кракозябр».
Отличия между charset=“UTF-8” и charset=“Windows-1251”
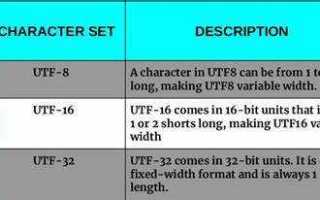
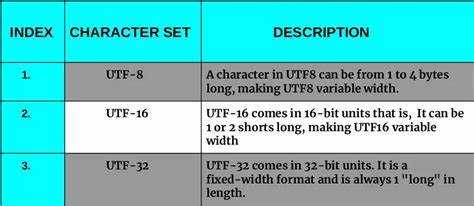
- Поддержка символов: UTF-8 охватывает весь Юникод, включая символы всех мировых языков. Windows-1251 ограничена кириллицей и несколькими дополнительными символами, всего 256 кодов.
- Совместимость: UTF-8 используется по умолчанию в большинстве современных браузеров, редакторов и серверов. Windows-1251 требует явного указания и может вызывать проблемы с отображением, особенно в многоязычных интерфейсах.
- Переносимость: UTF-8 корректно интерпретируется на любых платформах, включая Linux, macOS, Windows. Windows-1251 – устаревшая кодировка, часто неправильно отображается на системах, не поддерживающих CP1251.
- SEO и индексация: Поисковые системы отдают предпочтение UTF-8, поскольку она исключает ошибки кодировки при сканировании. Использование Windows-1251 может привести к искажённым фрагментам в сниппетах.
- Размер файла: В текстах, состоящих только из латиницы, UTF-8 эффективнее по размеру. Однако для кириллицы Windows-1251 даёт меньший размер, так как каждый символ занимает ровно 1 байт, в отличие от UTF-8, где кириллические символы – это 2 байта.
Для современных веб-проектов рекомендуется использовать charset="UTF-8". Это избавит от проблем с кодировкой, обеспечит совместимость и упростит интернационализацию.
Что происходит, если не указать charset в HTML
Некорректное определение charset также может повлиять на поведение JavaScript: строки, полученные из DOM или через AJAX, могут содержать искажённые символы. Это нарушает работу интерфейсов, фильтров, поиска и валидации данных.
Без charset невозможно гарантировать корректную индексацию страниц поисковыми системами. Роботы могут проигнорировать контент или некорректно его проанализировать. Также снижается вероятность правильного отображения страниц в кэше или при сохранении на диск.
Чтобы избежать подобных проблем, необходимо явно указывать кодировку в метатеге: <meta charset="UTF-8">. Это минимизирует риски неправильной интерпретации контента и повышает надёжность отображения на разных платформах.
Как определить текущую кодировку HTML-страницы

Кодировка страницы указывается в мета-теге <meta charset="...">, который должен располагаться в секции <head>. Чтобы узнать, какая кодировка используется, откройте исходный код страницы (Ctrl+U в большинстве браузеров) и найдите строку с атрибутом charset.
Если используется более старая форма указания кодировки, она может выглядеть так:
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">Современные страницы чаще используют UTF-8:
<meta charset="UTF-8">Также можно проверить кодировку через инструменты разработчика (F12). В Google Chrome: вкладка «Network» → клик по HTML-файлу → в разделе «Headers» найти заголовок Content-Type. Пример значения:
Content-Type: text/html; charset=UTF-8Если кодировка не указана явно, браузер может попытаться её угадать, что приводит к некорректному отображению символов. Поэтому отсутствие явного указания – признак потенциальной проблемы.
Для анализа локальных HTML-файлов используйте текстовые редакторы, отображающие кодировку, например Notepad++, Sublime Text или Visual Studio Code. В них кодировка часто указывается в нижней панели или в меню «File» → «Reopen with Encoding».
Влияние charset на отображение текста и символов
Кодировка символов (charset) напрямую определяет, как браузер интерпретирует байты в HTML-документе. Неверно заданный charset приводит к замене символов на �, вопросительные знаки или некорректные иероглифы.
Наиболее критично это для языков с нелатинским алфавитом – кириллицы, китайского, арабского. Например, если документ на русском языке открыт с кодировкой ISO-8859-1 вместо UTF-8, все кириллические буквы отобразятся как бессмысленный набор символов.
Современные браузеры по умолчанию предполагают UTF-8, но если в документе явно указана другая кодировка через <meta charset>, будет использоваться именно она. Поэтому необходимо всегда задавать правильную кодировку в первых 1024 байтах HTML, иначе автоопределение может не сработать корректно.
Использование UTF-8 устраняет большинство проблем: она поддерживает все символы Юникода, включая emoji, математические знаки и нестандартные алфавиты. Также она необходима при работе с API и базами данных, ожидающими строки в единой кодировке.
Рекомендация: используйте <meta charset=»UTF-8″> в каждой HTML-странице. Не полагайтесь на HTTP-заголовки, поскольку их может перезаписать сервер или прокси.
Проблемы с кодировкой: причины и пути их устранения
- Несовпадение charset в HTML и фактической кодировки файла: если файл сохранён в UTF-8, но в метатеге указано, например, Windows-1251, браузер будет интерпретировать байты некорректно. Решение: установить в <head> корректный метатег –
<meta charset="UTF-8">– и убедиться, что редактор сохраняет файл в этой же кодировке. - Отсутствие charset в HTTP-заголовках: сервер может отправить заголовки без указания кодировки, и браузер будет делать догадки. Это особенно критично для старых браузеров. Убедитесь, что сервер (например, Apache или Nginx) настроен передавать правильный заголовок
Content-Type: text/html; charset=UTF-8. - Неправильная кодировка базы данных: если данные записываются в БД в одной кодировке, а читаются в другой, возникают ошибки отображения. В MySQL проверьте параметры
character_set_client,character_set_connectionиcharacter_set_results. Для веб-приложений всегда устанавливайте соединение с указаниемSET NAMES 'utf8mb4'. - Перекодировка на этапе обработки файлов: при копировании или обработке файлов в системах с разной локалью (Windows/Linux) возможна непреднамеренная перекодировка. Используйте редакторы, поддерживающие явный выбор кодировки (например, VS Code, Sublime Text) и проверяйте BOM-метку в UTF-8, если она влияет на поведение интерпретаторов.
- Ошибки при передаче данных по API: если API не декларирует кодировку в заголовках, потребитель может интерпретировать текст неверно. Всегда задавайте
Content-Typeв HTTP-запросах и ответах, и по возможности используйте JSON с явной кодировкой UTF-8.
Для проверки кодировки удобно использовать команды file, iconv и chardet в Unix-системах. В браузере – инструмент разработчика: вкладка Network, где отображаются HTTP-заголовки и загруженные ресурсы.
Поддержка различных charset в популярных браузерах
Поддержка кодировок в браузерах зависит от их версии и операционной системы. Большинство современных браузеров, таких как Google Chrome, Mozilla Firefox, Safari и Microsoft Edge, поддерживают стандарт UTF-8 по умолчанию, что гарантирует корректное отображение символов большинства языков.
Google Chrome использует UTF-8 как основную кодировку, но если в HTML-документе не указан charset, браузер пытается определить кодировку автоматически. В случае несоответствия данных о кодировке Chrome может прибегнуть к анализу контента, что не всегда идеально и может вызвать проблемы при отображении символов.
Mozilla Firefox также преимущественно использует UTF-8. В случае сомнений по поводу кодировки, Firefox анализирует HTTP-заголовки и метатеги, что обеспечивает более точное определение charset. Однако, если страница не содержит явного указания кодировки, могут возникнуть проблемы с правильным отображением символов в некоторых случаях.
Safari и Microsoft Edge используют схожий алгоритм работы с кодировками. Safari активно применяет автоматическое определение charset, но, как и другие браузеры, может сталкиваться с проблемами при ошибках в метатегах или HTTP-заголовках. Edge, в свою очередь, перенял многие особенности Chromium, что обеспечило улучшенную поддержку UTF-8, а также возможность использования других популярных кодировок, таких как Windows-1251.
Для обеспечения совместимости и корректного отображения страниц на всех устройствах и браузерах рекомендуется всегда указывать кодировку в метатеге <meta charset="UTF-8">. Это гарантирует, что браузеры не будут полагаться на автоматическое определение charset и минимизирует риск ошибок.
Рекомендация: Если необходимо поддерживать страницы на нескольких языках или работать с данными, содержащими специальные символы, лучше всего использовать UTF-8. Это стандарт де-факто для веб-разработки, обеспечивающий широкую совместимость с современными браузерами и платформами.
Вопрос-ответ:
Что такое charset в HTML и зачем он нужен?
Charset (или кодировка символов) в HTML определяет способ, в который текст на веб-странице отображается в браузере. Кодировка важна для правильного отображения различных символов, таких как буквы, цифры и знаки препинания, особенно если на странице используются языки с нелатинскими алфавитами (например, русский или китайский). Указание правильного charset помогает избежать проблем с отображением символов и предотвращает ошибки в текстах.
Какая кодировка charset используется по умолчанию в большинстве браузеров?
Большинство современных браузеров по умолчанию используют кодировку UTF-8, если в HTML-документе не указана другая кодировка. Это связано с тем, что UTF-8 поддерживает все символы и знаки мира, и является стандартом для большинства веб-страниц, обеспечивая правильное отображение текста на разных языках. Однако, если указана другая кодировка, браузер будет использовать её.
Почему важно указывать charset в HTML, и что будет, если не указать?
Если кодировка не указана, браузер может попытаться сам определить её на основе контента, но это не всегда даёт правильный результат. В случае неправильного распознавания кодировки, текст может отображаться как набор непонятных символов. Чтобы избежать таких проблем, всегда лучше явно указывать кодировку с помощью мета-тега. Это особенно важно для многоязычных сайтов, где используются разные алфавиты.
Что такое charset в HTML и зачем его использовать?
Charset в HTML — это параметр, который указывает кодировку символов, используемую для отображения текста на веб-странице. Он необходим, чтобы браузер правильно интерпретировал текст, особенно если на странице используются символы, отличные от латинских букв, такие как кириллица, китайские или арабские символы. Без указания кодировки могут возникнуть проблемы с отображением символов, например, знаки могут быть заменены на странные символы или нечитаемые буквы.