DOM (Document Object Model) – это структура, в которой браузер представляет HTML-документ после его загрузки. Она формируется в виде дерева объектов, где каждый элемент, атрибут и текстовый фрагмент становятся узлами. Такое представление позволяет программно взаимодействовать с содержимым страницы с помощью JavaScript.
Каждому тегу HTML соответствует объект типа Element. Например, тег <div> становится узлом с типом HTMLElement, а его атрибут class – дочерним узлом с типом Attr. Текст внутри тега представлен узлом типа Text. Эти узлы объединены в иерархию, где корневым элементом является document, а затем идёт document.documentElement, то есть <html>.
Изменения в DOM происходят в реальном времени. Добавление, удаление или замена узлов мгновенно отображаются в пользовательском интерфейсе. Это позволяет создавать интерактивные интерфейсы, обновляющиеся без перезагрузки страницы. Манипуляции с DOM выполняются с помощью методов, таких как getElementById(), querySelector(), appendChild(), removeChild(), createElement().
Производительность DOM-операций зависит от глубины дерева и частоты обращений к нему. Рекомендуется минимизировать количество обращений к DOM напрямую, использовать фрагменты (DocumentFragment) при массовом добавлении элементов и кешировать часто используемые узлы. Это снижает нагрузку на рендеринг и повышает отзывчивость интерфейса.
Как создаётся DOM при загрузке HTML-документа
Когда браузер получает HTML-файл, он начинает обработку сверху вниз. Сначала загружается и анализируется строка <!DOCTYPE html>, после чего запускается парсинг HTML.
HTML-парсер преобразует каждую строку документа в узлы. Текст внутри тегов становится текстовыми узлами, а сами теги – элементами DOM-дерева. Комментарии и служебные элементы тоже получают свои узлы. Браузер строит иерархическую структуру, в которой родительские и дочерние элементы связаны в соответствии с вложенностью HTML-кода.
Если парсер встречает тег <script> без атрибута async или defer, он приостанавливает построение дерева и выполняет скрипт. Это может задерживать дальнейший парсинг. Скрипты с defer откладываются до окончания построения DOM, а async-скрипты запускаются независимо от процесса парсинга.
При загрузке внешних ресурсов (например, изображений или стилей) DOM не блокируется, но может быть дополнен позже, если в скриптах появляются новые элементы. Например, метод document.createElement позволяет добавить узел после завершения начального построения дерева.
После завершения парсинга и выполнения всех defer-скриптов браузер вызывает событие DOMContentLoaded. Это сигнал о том, что DOM полностью сформирован и доступен для взаимодействия.
Чем DOM отличается от исходного HTML-кода

HTML – это текстовый документ, содержащий разметку. Он не реагирует на действия пользователя и не изменяется сам по себе. DOM, напротив, динамичен: его структура может изменяться во время выполнения страницы. Сценарии могут добавлять, удалять и изменять узлы DOM, что позволяет создавать интерактивные интерфейсы.
При парсинге HTML браузер может дополнять DOM-структуру элементами, которых не было в исходном коде. Например, если в HTML отсутствует тег <tbody> внутри таблицы, браузер добавит его в DOM автоматически. Также он может исправить ошибки, например, закрыть незакрытые теги.
Изменения, внесённые в DOM с помощью JavaScript, не отражаются в исходном HTML-коде. При просмотре страницы через «Просмотр исходного кода» пользователь увидит только начальный HTML. Чтобы увидеть текущее состояние DOM, нужно использовать инструменты разработчика.
Работа с DOM требует точного понимания структуры документа, поскольку даже незначительное изменение может затронуть вложенные элементы. Рекомендуется использовать методы вроде querySelector, appendChild, removeChild и свойства innerHTML, textContent только при необходимости и с учётом влияния на производительность и безопасность.
Как обращаться к элементам DOM с помощью JavaScript
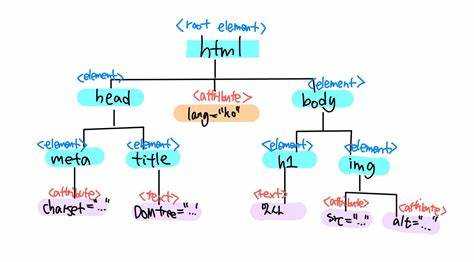
Для доступа к элементам DOM используются методы объекта document. Каждый из них подходит для определённых задач.
getElementById(id)– возвращает элемент по уникальному идентификатору. Работает быстрее других методов, но применим только к одному элементу.getElementsByClassName(className)– выдаёт HTMLCollection всех элементов с указанным классом. Коллекция автоматически обновляется при изменении DOM.getElementsByTagName(tagName)– возвращает HTMLCollection элементов с заданным тегом. Можно использовать, например, для сбора всех<p>на странице.querySelector(selector)– возвращает первый элемент, соответствующий CSS-селектору. Универсальный способ, удобен для сложных выборок.querySelectorAll(selector)– выдаёт статическую коллекцию NodeList, соответствующую селектору. Поддерживает цепочки селекторов, псевдоклассы и другие возможности CSS.
Рекомендуется использовать querySelector и querySelectorAll для точечных выборок, так как они поддерживают любой CSS-синтаксис. При этом getElementById остаётся самым быстрым способом получения одного элемента.
Для повышения читаемости кода лучше сохранять полученные элементы в переменные:
const header = document.getElementById('main-header');
const buttons = document.querySelectorAll('.btn-primary');Если необходимо работать с группой элементов, используйте forEach при работе с NodeList:
document.querySelectorAll('.item').forEach((el) => {
el.classList.add('active');
});HTMLCollection не поддерживает forEach напрямую. Для обхода применяйте цикл for или преобразование через Array.from().
Что такое узлы DOM и какие они бывают

DOM состоит из узлов, каждый из которых представляет отдельную часть HTML-документа. Узлы связаны иерархически, образуя дерево. Все элементы, атрибуты, текстовые фрагменты и даже комментарии в HTML рассматриваются как узлы разных типов.
1. Элементные узлы (Element nodes) – представляют теги HTML. Пример: <div>, <p>, <ul>. Являются основой структуры документа. Доступ к ним осуществляется через методы вроде getElementById, querySelector.
2. Текстовые узлы (Text nodes) – содержат текст внутри элементов. Даже пробелы и переводы строк учитываются как текст. Текстовый узел нельзя напрямую стилизовать или навесить на него обработчик событий.
3. Атрибутные узлы (Attribute nodes) – представляют атрибуты элементов, но напрямую в DOM-дереве как дочерние не отображаются. Доступ осуществляется через свойства element.attributes или методы getAttribute / setAttribute.
4. Комментарии (Comment nodes) – представляют собой узлы с содержимым HTML-комментариев. Доступ к ним возможен, но они редко используются при работе с DOM-программированием.
5. Документный узел (Document node) – корневой узел всего DOM-дерева. Представлен объектом document. С него начинается поиск и манипуляции с элементами страницы.
6. Документ-фрагмент (DocumentFragment) – временный контейнер для группировки узлов перед вставкой в документ. Используется для повышения производительности при массовом добавлении элементов.
Для точной работы с DOM полезно различать типы узлов. Свойство nodeType помогает определить тип: 1 – элемент, 3 – текст, 8 – комментарий. Это позволяет фильтровать нужные данные при обходе дерева.
Как изменять структуру DOM в браузере
Для добавления новых элементов используют методы document.createElement и Node.appendChild или Node.append. Например, чтобы создать абзац и добавить его в <div id="container">, пишут:
const p = document.createElement("p");
p.textContent = "Новый текст";
document.getElementById("container").appendChild(p);
Для вставки элемента до существующего узла используется Node.insertBefore. Чтобы добавить элемент в начало <ul>:
const li = document.createElement("li");
li.textContent = "Первый пункт";
const ul = document.querySelector("ul");
ul.insertBefore(li, ul.firstChild);
Удаление узлов выполняется через Node.removeChild или Node.remove(). Второй способ короче и не требует ссылки на родителя:
document.querySelector("li").remove();
Замену элемента осуществляют с помощью Node.replaceChild:
const newEl = document.createElement("span");
newEl.textContent = "Замена";
const oldEl = document.getElementById("старый");
oldEl.parentNode.replaceChild(newEl, oldEl);
Изменения напрямую через innerHTML перезаписывают содержимое элемента. Этот способ быстрый, но может удалять обработчики событий:
document.getElementById("container").innerHTML = "<p>Обновлённый текст</p>";
Для изменения текста без HTML-тегов безопаснее использовать textContent:
document.querySelector("h1").textContent = "Новый заголовок";
Какие ошибки возникают при работе с DOM и как их избежать
Работа с DOM может быть сложной, если не учитывать несколько основных аспектов. Ошибки при манипуляциях с DOM могут привести к сбоям, снижению производительности или неправильному отображению контента. Рассмотрим основные ошибки и способы их предотвращения.
1. Несоответствие типов данных
- При попытке работы с элементами DOM можно столкнуться с несоответствием типов данных, когда ожидался, например, элемент, а получен текстовый узел. Это может привести к ошибкам при попытке использовать методы DOM, такие как
appendChild()илиsetAttribute(). - Для предотвращения этой ошибки нужно проверять типы данных перед использованием методов. Используйте
nodeTypeдля определения типа узла.
2. Манипуляции с несуществующими элементами
- Попытка манипулировать элементами DOM, которых нет на странице, приводит к ошибкам, так как операции выполняются над неопределёнными объектами. Это часто возникает, если селектор
querySelector()не находит элемент, а код продолжает работать с несуществующим объектом. - Используйте проверки: перед вызовом методов на объекте DOM всегда проверяйте его существование, например:
if (element !== null) {
// манипуляции с element
}
3. Проблемы с асинхронными запросами
- Ошибка возникает, когда DOM изменяется в процессе выполнения асинхронного кода (например, при получении данных с сервера). Это может привести к тому, что код попытается манипулировать элементами, которые ещё не загружены или не существуют.
- Для избежания таких проблем используйте механизмы, которые гарантируют завершение загрузки страницы или данных перед манипуляциями с DOM, например, события
DOMContentLoadedилиload.
4. Модификация DOM в цикле
- Модификация DOM внутри циклов может быть неэффективной, так как каждый вызов методов, таких как
appendChild()илиremoveChild(), инициирует перерисовку страницы. Это замедляет выполнение скриптов и ухудшает производительность. - Для предотвращения таких проблем рекомендуется собирать изменения в память, а затем внести все изменения за один раз. Например, создавайте элементы в память, а затем добавляйте их в DOM.
5. Неправильное использование события onclick
- При добавлении обработчиков событий непосредственно в HTML (через атрибут
onclick) могут возникать проблемы с повторной инициализацией или конфликтами с другими скриптами. - Для избежания этого используйте метод
addEventListener(), который позволяет добавлять несколько обработчиков и лучше управлять событиями.
6. Избыточная работа с DOM
- Частые и необоснованные изменения DOM, например, чрезмерное обновление стилей или классов, могут замедлить работу страницы, особенно если это происходит в реальном времени при прокрутке или вводе данных.
- Ограничьте количество операций с DOM и минимизируйте их до тех пор, пока изменения не станут необходимыми. Использование технологий, таких как
requestAnimationFrame, помогает с оптимизацией.
Вопрос-ответ:
Что такое DOM в HTML?
DOM (Document Object Model) — это программная модель, которая представляет структуру веб-страницы в виде дерева объектов. Каждый элемент HTML на странице превращается в объект в DOM, что позволяет взаимодействовать с этим элементом через JavaScript. В DOM элементы страницы можно добавлять, удалять или изменять их свойства и содержимое.
Как устроен DOM в HTML?
DOM представляет страницу в виде иерархической структуры, где каждый элемент HTML, атрибуты и текст рассматриваются как узлы дерева. Корневой узел — это объект, который представляет сам документ. Все другие элементы, такие как теги `
`, `` и другие, становятся дочерними узлами, образуя дерево, которое можно динамически изменять.
Зачем нужен DOM в HTML?
DOM позволяет взаимодействовать с элементами страницы через скрипты. Например, с помощью JavaScript можно менять текст в элементах, скрывать или показывать части контента, изменять стили и реагировать на действия пользователя, такие как клики или ввод текста. Это дает гибкость в создании интерактивных и динамичных веб-страниц.
Как можно манипулировать элементами через DOM?
Через DOM можно манипулировать элементами с помощью JavaScript. Для этого используются различные методы, такие как `getElementById()` для поиска элементов по ID, `createElement()` для создания новых элементов, `appendChild()` для добавления новых дочерних элементов и `removeChild()` для удаления элементов. Эти методы позволяют динамически изменять структуру и содержимое страницы.
Какие типы узлов есть в DOM?
В DOM существует несколько типов узлов: элементные узлы (например, теги HTML), текстовые узлы (содержимое внутри элементов), атрибутные узлы (свойства элементов, такие как `class` или `id`), а также комментарии. Каждый из этих узлов может быть доступен и изменен с помощью JavaScript, что позволяет гибко управлять содержимым страницы.
 (пока оценок нет)
(пока оценок нет)