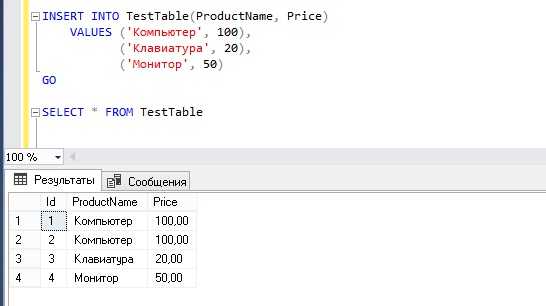
Импортирование данных в базу данных SQL – ключевая операция для работы с большими объемами информации. Этот процесс позволяет эффективно перенести таблицы из различных форматов в SQL, обеспечивая удобство и скорость обработки данных. В этой статье рассмотрим конкретные шаги, которые помогут быстро и без ошибок загрузить таблицу в базу данных SQL.
Подготовка данных – первый и один из самых важных этапов. Прежде чем импортировать таблицу, важно убедиться, что данные находятся в подходящем формате. Наиболее распространенные форматы для импорта – CSV, Excel (XLS, XLSX) и текстовые файлы (TXT). Преобразуйте данные в один из этих форматов, если они еще не подготовлены. Для этого используйте встроенные функции Excel или других программ для работы с таблицами.
Использование SQL-запросов позволяет минимизировать вероятность ошибок при импорте. Пример простого запроса для загрузки данных из CSV файла выглядит так:
LOAD DATA INFILE ‘/path/to/file.csv’ INTO TABLE имя_таблицы FIELDS TERMINATED BY ‘,’ ENCLOSED BY ‘\»‘ LINES TERMINATED BY ‘\n’;
Этот запрос загружает данные из CSV файла в таблицу, используя разделители, которые соответствуют формату файла. Для других форматов, таких как Excel, можно использовать дополнительные инструменты или плагины для работы с SQL-серверами.
Если база данных уже настроена и имеется доступ к инструментам, процесс импорта данных можно выполнить через графический интерфейс. В популярных СУБД, таких как MySQL Workbench или pgAdmin, имеется встроенный функционал для импорта данных. Выбирайте меню «Импорт» и следуйте указаниям мастера импорта, который предложит вам выбрать источник данных и соответствующие параметры для корректной загрузки.
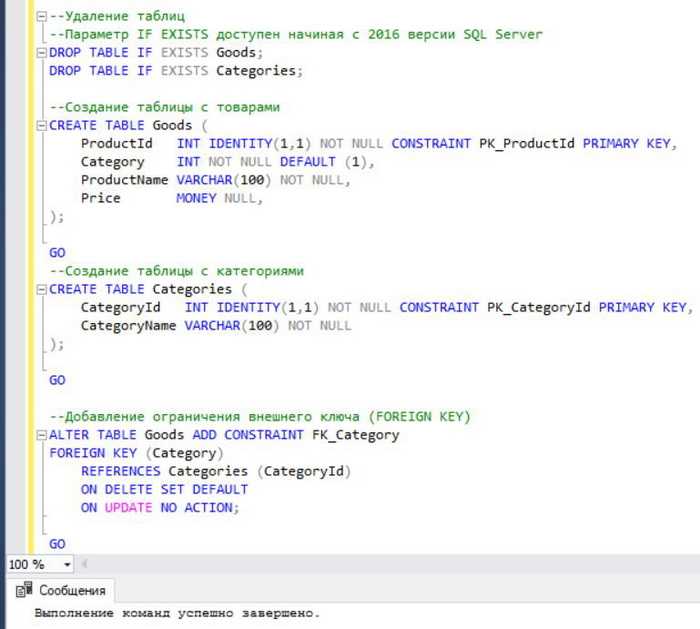
Подготовка таблицы для импорта в SQL
Перед импортом таблицы в базу данных важно убедиться, что данные готовы для корректной загрузки в SQL-систему. Это включает несколько ключевых шагов.
- Проверка структуры данных: Убедитесь, что столбцы в таблице соответствуют полям в базе данных. Типы данных, такие как целые числа, строки и даты, должны быть совместимы.
- Очистка данных: Удалите лишние пробелы, символы и пустые строки. Это предотвратит ошибки при импорте. Например, если столбец должен содержать только числовые значения, удалите текстовые символы.
- Преобразование форматов даты: Проверьте формат даты и времени. SQL часто использует стандарт ISO 8601 (YYYY-MM-DD HH:MM:SS), и его следует применять для всех соответствующих полей.
- Нормализация данных: Приведите данные к стандартному виду. Например, используйте одинаковое написание для всех значений в столбцах, таких как «Мужчина» и «Женщина» (а не «мужчина» или «женщина»).
- Удаление дубликатов: Пройдитесь по данным и удалите все дублирующиеся строки, чтобы избежать лишней загрузки данных в базу.
- Заполнение пустых значений: Проверьте таблицу на наличие пустых или NULL значений. Если это необходимо, замените их на стандартные значения, например, 0 или «Не указано».
После того как таблица будет подготовлена, можно переходить к следующему этапу – непосредственному импорту данных в SQL.
Выбор метода импорта в зависимости от формата файла
При импорте данных в SQL важно учитывать формат исходного файла. Каждый тип файла требует своего подхода для корректной загрузки в базу данных.
CSV (Comma-Separated Values) – один из самых распространённых форматов. Для импорта данных из CSV удобно использовать команду LOAD DATA INFILE в MySQL или COPY в PostgreSQL. Эти методы быстро обрабатывают большие объёмы данных. Важно, чтобы в CSV не было специальных символов, таких как запятые или кавычки в строках данных. Если файл содержит такие символы, их нужно экранировать или использовать другой разделитель.
Excel (XLS, XLSX) – для работы с файлами Excel можно использовать специализированные инструменты, такие как SQL Server Integration Services (SSIS) для SQL Server или MySQL Workbench для MySQL. Также доступны внешние библиотеки (например, pandas в Python) для конвертации данных в CSV перед загрузкой. Однако Excel не всегда эффективно справляется с большими объёмами данных, поэтому важно удостовериться в корректности всех значений перед импортом.
JSON – формат, популярный для хранения и передачи структурированных данных. Для импорта JSON в базы данных часто используют функции вроде JSON_EXTRACT в MySQL или json_populate_record в PostgreSQL. Это позволяет работать с вложенными объектами и массивами. При импорте важно обратить внимание на структуру данных, поскольку некорректная вложенность может привести к ошибкам.
XML – для XML можно использовать специализированные функции, такие как XMLTABLE в PostgreSQL или LOAD XML в MySQL. XML хорошо подходит для работы с иерархичными данными. При импорте XML важно удостовериться, что формат соответствует ожидаемой схеме, иначе возможны проблемы с парсингом.
Каждый формат имеет свои особенности, и выбор метода импорта зависит от структуры и объёма данных. Применение подходящего метода поможет избежать ошибок и ускорить процесс загрузки данных в базу.
Использование команды LOAD DATA для импорта CSV файлов
Команда LOAD DATA INFILE позволяет эффективно загружать данные из CSV файлов в таблицы MySQL. Это быстрый и мощный инструмент для обработки больших объемов данных.
Пример синтаксиса команды для загрузки данных из файла CSV выглядит так:
LOAD DATA INFILE '/путь/к/файлу.csv'
INTO TABLE имя_таблицы
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES;
Параметры команды:
- FIELDS TERMINATED BY: указывает разделитель полей, например, запятую для CSV.
- ENCLOSED BY: если значения в файле заключены в кавычки, укажите символ кавычек.
- LINES TERMINATED BY: определяет символ для окончания строки (чаще всего используется ‘\n’).
- IGNORE 1 LINES: пропускает первую строку, которая обычно содержит заголовки колонок.
Для загрузки данных с сервера можно использовать локальный файл, указав опцию LOCAL:
LOAD DATA LOCAL INFILE '/путь/к/файлу.csv'
INTO TABLE имя_таблицы
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES;
Важно помнить, что файл должен быть доступен для чтения сервером MySQL. При использовании LOAD DATA LOCAL файл может быть загружен с клиента, но для этого требуется разрешение на использование LOCAL.
При работе с большими объемами данных команда LOAD DATA значительно быстрее по сравнению с другими методами импорта, например, с использованием INSERT для каждой строки.
Перед импортом рекомендуется проверить соответствие структуры файла и таблицы. Ошибки в типах данных или неверные разделители могут привести к сбоям во время импорта.
Импорт данных с помощью SQL-запросов
Импорт данных в SQL может быть выполнен с использованием различных SQL-запросов, в зависимости от формата исходных данных и особенностей базы данных. Один из наиболее популярных методов – использование команды LOAD DATA INFILE для загрузки данных из текстовых файлов, таких как CSV или TSV. Этот способ особенно эффективен при необходимости загрузки больших объемов данных.
Для выполнения импорта с помощью LOAD DATA INFILE необходимо выполнить следующий запрос:
LOAD DATA INFILE 'путь_к_файлу.csv' INTO TABLE имя_таблицы FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 LINES;
В этом запросе:
FIELDS TERMINATED BY ','указывает, что поля в файле разделены запятыми.ENCLOSED BY '"'указывает, что данные в строках заключены в кавычки.LINES TERMINATED BY '\n'определяет, что каждая строка заканчивается символом новой строки.IGNORE 1 LINESпропускает первую строку, если она содержит заголовки.
Для использования LOAD DATA INFILE необходимо, чтобы файл находился на сервере базы данных или был доступен для чтения сервером. Также важно настроить права доступа, чтобы разрешить выполнение этой команды.
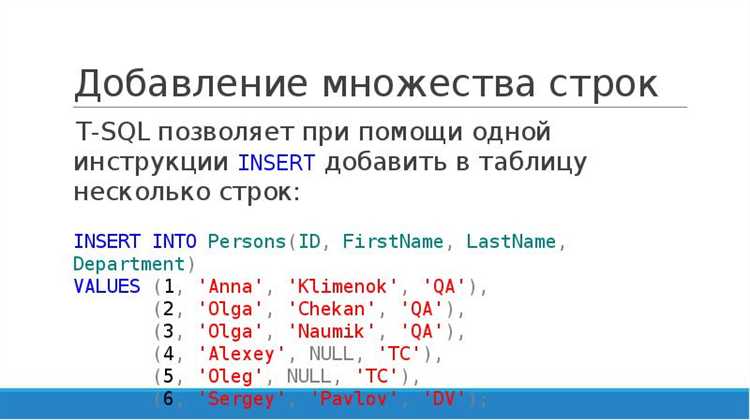
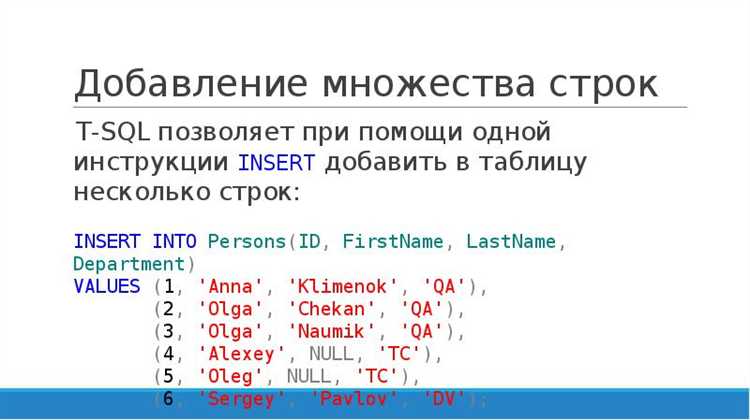
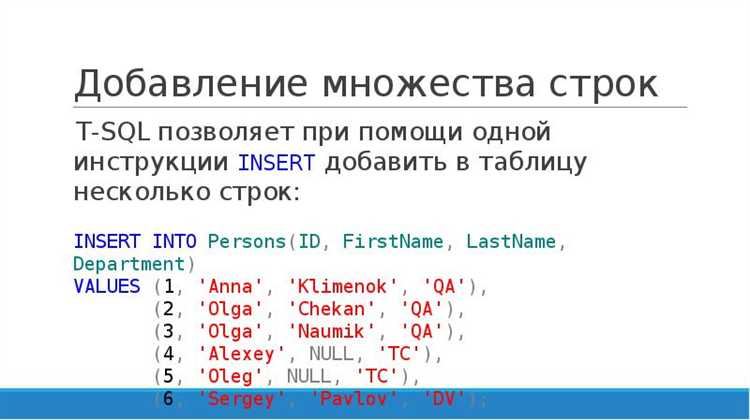
Другой способ импорта – использование команды INSERT INTO, которая подходит для загрузки данных из небольших файлов или для ручного добавления строк:
INSERT INTO имя_таблицы (колонка1, колонка2, колонка3)
VALUES ('значение1', 'значение2', 'значение3'),
('значение4', 'значение5', 'значение6');
Этот метод не так эффективен для больших данных, но он удобен для добавления отдельных строк в таблицу. Он также поддерживает импорт из динамически генерируемых данных или других источников.
Для сложных импортов можно использовать инструменты, встроенные в СУБД, такие как MySQL Workbench или pgAdmin, которые предлагают удобные графические интерфейсы для загрузки данных. Важно учитывать, что большие объемы данных могут потребовать дополнительной настройки индексов или транзакций для оптимизации работы базы данных.
Обработка ошибок при импорте данных
При импорте данных в SQL могут возникнуть различные ошибки, связанные с несовпадением типов данных, нарушением целостности данных или проблемами с подключением к базе. Ожидать их сложно, но важно быть готовым к быстрому реагированию.
Ошибка несовпадения типов данных встречается, когда данные в источнике не соответствуют типам данных в целевой таблице. Например, попытка вставить текстовое значение в числовое поле вызовет ошибку. Для устранения таких ошибок необходимо заранее проверять типы данных и преобразовывать их при необходимости, используя функции преобразования, такие как CAST или CONVERT.
Ошибка нарушения целостности данных возникает, когда вставляемые данные нарушают ограничения на уникальность, внешние ключи или другие ограничения. Например, если пытаетесь вставить строку с уже существующим значением в поле, которое должно быть уникальным, будет ошибка. Чтобы избежать этого, нужно либо обеспечить уникальность данных перед импортом, либо использовать команду IGNORE для пропуска таких записей.
Проблемы с подключением могут возникнуть, если сеть нестабильна или сервер перегружен. Это можно минимизировать, обеспечив постоянную проверку состояния соединения и использование транзакций, которые позволят откатить изменения в случае сбоя.
Ошибки форматирования данных чаще всего встречаются при импорте данных из CSV или других текстовых форматов. Например, неправильные разделители, кавычки или неполные строки могут привести к неправильной интерпретации данных. Решение – заранее настроить параметры импорта, чтобы указать правильные разделители и учитывать возможные проблемы с кодировкой.
Чтобы минимизировать количество ошибок, рекомендуется сначала выполнить тестовый импорт на небольшом наборе данных. Это позволяет выявить и исправить проблемы до основного процесса импорта.
Логирование ошибок является важной частью обработки. Включив логирование, можно отслеживать все ошибки, их источники и время возникновения, что упрощает диагностику и позволяет быстрее реагировать на проблемы.
Преимущества использования графических интерфейсов для импорта
Графические интерфейсы для импорта данных в SQL позволяют значительно упростить процесс. Они избавляют от необходимости вручную писать сложные SQL-запросы, что минимизирует вероятность ошибок. При использовании таких инструментов данные можно быстро просматривать и проверять перед загрузкой, что делает работу более прозрачной.
1. Удобство в работе с большими объемами данных
Графические интерфейсы поддерживают различные форматы файлов (например, CSV, Excel), что позволяет легко загружать и преобразовывать данные. Это особенно полезно при работе с большими объемами информации, где каждое изменение в запросе или файле требует значительных временных затрат при использовании командной строки.
2. Меньше ошибок и сложностей
Интерфейс позволяет визуально контролировать процесс импорта: от выбора источника до проверки правильности данных. Это снижает вероятность ошибок, таких как несоответствия типов данных или неправильное соответствие столбцов, которые могут возникнуть при ручном вводе SQL-запросов.
3. Визуальная проверка структуры данных
Графические интерфейсы предлагают возможность наглядно проверять структуру таблицы, что облегчает выбор нужных параметров для импорта. С помощью визуального интерфейса легче отслеживать, как именно будут распределяться данные по столбцам в таблице.
4. Поддержка различных источников данных
Многие графические инструменты поддерживают импорт данных не только из локальных файлов, но и из внешних баз данных, облачных хранилищ, REST API и других источников. Это открывает дополнительные возможности для интеграции SQL с другими системами.
5. Экономия времени и усилий
Использование графических интерфейсов экономит время, которое могло бы уйти на написание и тестирование SQL-запросов вручную. С помощью готовых шаблонов и мастеров импорта процесс можно ускорить, что особенно важно при регулярной работе с данными.
Импорт больших объёмов данных: подходы и оптимизация
Импорт больших объёмов данных в SQL требует внимательности к производительности. Здесь важны не только корректность обработки, но и минимизация времени загрузки и снижения нагрузки на систему. Рассмотрим несколько стратегий и рекомендаций для эффективного импорта.
1. Разделение данных на части
Если данные содержат миллионы строк, импортировать их целиком может быть слишком медленно. Лучше разделить данные на несколько частей. Это позволит:
- Снизить нагрузку на базу данных и сервер;
- Использовать параллельную обработку для ускорения процесса.
Можно делить данные по диапазонам значений или разбивать их по файлам, каждый из которых будет обрабатываться независимо.
2. Использование BULK INSERT
Для импортирования больших объёмов данных можно использовать команду BULK INSERT (или аналогичные инструменты для других СУБД). Это значительно быстрее стандартных вставок INSERT по одной строке. Для повышения производительности:
- Отключите индексы перед загрузкой данных;
- Используйте минимальные логирование транзакций;
- Используйте форматы файлов, поддерживающие быстрый ввод (например, CSV или TSV).
3. Оптимизация индексов
Наличие индексов на таблицах может замедлить процесс импорта. Важно:
- Удалять индексы перед началом загрузки;
- Восстанавливать индексы после завершения процесса импорта.
Для больших таблиц также имеет смысл использовать уникальные индексы только на тех столбцах, где это действительно необходимо, чтобы избежать дополнительных затрат на проверку уникальности данных при вставке.
4. Использование параллельной обработки
Для ускорения импорта больших объёмов данных применяйте параллельную обработку. В зависимости от СУБД это можно реализовать через:
- Запуск нескольких потоков или процессов для обработки разных частей данных;
- Использование технологий, поддерживающих параллельную загрузку, например, через использование разных серверов или баз данных.
Таким образом, можно значительно ускорить процесс без значительного увеличения нагрузки на систему.
5. Применение транзакций
Для защиты данных и обеспечения целостности важно использовать транзакции. Однако при импорте больших объёмов данных необходимо избегать чрезмерных накладных расходов, вызванных частыми фиксациями транзакций. Рекомендуется:
- Группировать данные в крупные блоки и обрабатывать их за один раз;
- Использовать транзакции только для каждой партии данных, чтобы избежать блокировок на длительные периоды времени.
6. Использование инструментов для миграции
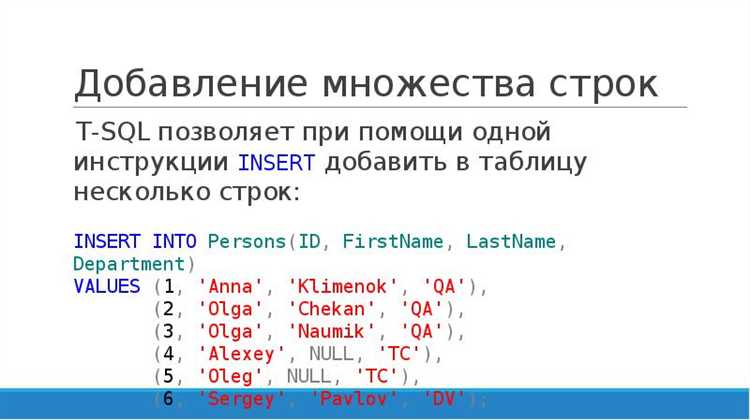
Для миграции больших объёмов данных можно использовать специализированные инструменты, такие как SQL*Loader (для Oracle) или pg_bulkload (для PostgreSQL). Эти инструменты обеспечивают:
- Быструю загрузку данных;
- Поддержку различных форматов файлов;
- Автоматизацию процесса обработки ошибок.
Выбор инструментов зависит от специфики вашей СУБД и задач импорта.
7. Мониторинг и анализ производительности
Перед массовым импортом рекомендуется провести тесты на меньших объёмах данных. Это поможет выявить узкие места в процессе и настроить параметры системы для лучшей производительности. Важные моменты для мониторинга:
- Нагрузка на диск и процессор;
- Скорость записи в базу данных.
Проверка корректности импорта и работа с дубликатами
После завершения импорта данных в SQL важно удостовериться в их корректности и целостности. Для этого следует выполнить несколько проверок.
1. Проверка на количество строк. Сравните количество строк в исходном файле с количеством строк в таблице после импорта. Если числа не совпадают, возможно, данные были утеряны или не все записи были успешно импортированы. Для проверки используйте SQL-запрос SELECT COUNT(*) FROM имя_таблицы;.
2. Проверка на соответствие типов данных. Убедитесь, что данные в таблице соответствуют заданным типам данных (например, числа не преобразованы в строки). Это можно сделать с помощью запросов, которые проверяют наличие аномальных значений, например: SELECT * FROM имя_таблицы WHERE поле IS NULL;.
3. Работа с дубликатами. Чтобы избежать дублирования записей, используйте уникальные ограничения на ключевых столбцах (например, PRIMARY KEY или UNIQUE). Если дубликаты уже присутствуют, их можно найти с помощью запроса SELECT поле, COUNT(*) FROM имя_таблицы GROUP BY поле HAVING COUNT(*) > 1;.
4. Удаление дубликатов. Если необходимо удалить дубликаты, можно использовать подзапросы или временные таблицы. Пример удаления дубликатов с сохранением одной записи: DELETE FROM имя_таблицы WHERE id NOT IN (SELECT MIN(id) FROM имя_таблицы GROUP BY поле);.
5. Проверка на целостность данных. Если импорируемые данные имеют внешние ключи, убедитесь, что все связи между таблицами корректны. Используйте JOIN для проверки соответствия данных в связанных таблицах.
Внимательная проверка и удаление дубликатов обеспечат точность и полноту базы данных, предотвращая возможные ошибки в дальнейшем использовании.
Вопрос-ответ:
Как импортировать таблицу в SQL из Excel?
Для импорта таблицы из Excel в SQL можно использовать встроенные инструменты в СУБД, такие как SQL Server Management Studio (SSMS) для SQL Server или другие аналогичные инструменты. Например, в SSMS для этого нужно выбрать пункт «Импорт данных», указать путь к файлу Excel и выбрать соответствующие настройки для импорта. Важно правильно настроить соответствие столбцов в Excel и поля в таблице SQL.
Какие форматы файлов поддерживает SQL для импорта данных?
SQL поддерживает множество форматов для импорта данных. Наиболее популярные из них включают CSV (Comma-Separated Values), Excel (XLSX), и текстовые файлы (например, TXT). В зависимости от СУБД могут быть доступны и другие форматы, такие как XML и JSON. Выбор формата зависит от того, какие данные необходимо загрузить и какие инструменты используются для импорта.
Какие шаги нужно предпринять, чтобы импортировать данные из CSV в SQL?
Чтобы импортировать данные из CSV в SQL, выполните следующие шаги: сначала откройте вашу СУБД, затем используйте команду импорта, например, «BULK INSERT» в SQL Server. Укажите путь к файлу CSV и настройте параметры, такие как разделитель и текстовые ограничения. После этого SQL автоматически загрузит данные в таблицу. Важно заранее убедиться, что структура таблицы соответствует данным в файле CSV, чтобы избежать ошибок импорта.
Какие проблемы могут возникнуть при импорте таблицы в SQL?
При импорте данных в SQL могут возникнуть различные проблемы, такие как несоответствие типов данных (например, если в столбце с числовыми данными содержатся текстовые значения), ошибки в форматировании дат, а также проблемы с кодировкой текста. Также стоит обратить внимание на размер файла и ограничения по памяти в СУБД. Чтобы избежать ошибок, рекомендуется проверить данные перед импортом и правильно настроить параметры импорта.
Как проверить, что данные корректно импортированы в SQL?
Чтобы проверить корректность импорта данных, можно выполнить несколько шагов: выполните запрос SELECT для отображения загруженных данных и убедитесь, что они отображаются правильно. Также стоит проверить количество строк и типы данных, чтобы убедиться в отсутствии ошибок. Если есть подозрения на проблемы, можно сравнить несколько случайных записей с исходным файлом, чтобы проверить соответствие.