Прежде всего, важен правильный выбор методов агрегации и фильтрации данных. Использование функции DISTINCT часто является первым шагом для устранения повторяющихся строк, однако она не всегда может быть эффективной, особенно при работе с большими объемами данных. В таких случаях лучше сосредоточиться на точной настройке условий соединения таблиц и внимательном использовании операторов JOIN, где важно, чтобы соединяемые ключи уникально идентифицировали строки.
Не менее важным является правильное проектирование схемы базы данных. Плохо спроектированная структура может привести к ненужному дублированию данных уже на уровне хранения. Использование принципов нормализации и создание дополнительных индексов позволяет минимизировать избыточность на уровне базы данных, а также ускоряет выполнение запросов.
Еще одним способом предотвращения дублирования является использование подзапросов и оконных функций. Например, ROW_NUMBER() и DENSE_RANK() позволяют избирательно обрабатывать повторяющиеся данные, сохраняя только одну строку из группы дублированных значений. Эти функции особенно полезны при анализе сложных выборок и позволяют эффективно работать с большими наборами данных без потери точности.
Использование DISTINCT для устранения дубликатов в выборке

Ключевое слово DISTINCT в SQL используется для исключения дублирующихся строк в результирующем наборе данных. Когда запрос возвращает несколько строк с одинаковыми значениями в одном или нескольких столбцах, DISTINCT позволяет получить только уникальные строки, что особенно полезно при анализе больших объемов данных.
Применение DISTINCT осуществляется перед указанием столбцов, которые нужно отобразить. Например, запрос SELECT DISTINCT column_name FROM table_name; вернет только уникальные значения из указанного столбца. Важно отметить, что DISTINCT работает по всей строке, а не по отдельным столбцам, что означает, что для исключения дубликатов все значения в строке должны совпадать.
При использовании DISTINCT важно учитывать производительность. Применение этого оператора может быть затратным для больших таблиц, особенно если запрос включает несколько столбцов или сложные условия фильтрации. В таких случаях стоит внимательно анализировать индексы на таблицах и их влияние на эффективность запроса.
Для более точного управления результатами можно использовать DISTINCT с агрегатными функциями, такими как COUNT или AVG. Например, запрос SELECT COUNT(DISTINCT column_name) FROM table_name; позволяет посчитать количество уникальных значений в столбце. Такой подход полезен для вычислений, когда требуется знать количество разных элементов без учета повторов.
Также стоит помнить, что DISTINCT не всегда является единственным или лучшим решением для устранения дубликатов. В некоторых случаях можно использовать группировку данных с помощью оператора GROUP BY, который может предоставить большую гибкость при работе с агрегатами и вычислениями. Например, запрос SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name; позволяет сгруппировать данные по уникальным значениям и посчитать их количество.
Оптимизация JOIN операций для предотвращения повторных данных

При выполнении SQL-запросов с использованием JOIN операций, особенно с множественными соединениями, легко столкнуться с дублированием строк. Это происходит, когда одна строка из первой таблицы соединяется с несколькими строками из второй, что приводит к повторению данных. Чтобы избежать избыточных результатов и повысить производительность запроса, необходимо применять несколько оптимизаций.
Вот несколько подходов для эффективной работы с JOIN и минимизации повторных данных:
- Использование правильного типа JOIN: Для предотвращения дублирования данных важно тщательно выбирать тип JOIN. Например, LEFT JOIN или RIGHT JOIN могут привести к дублированию, если в присоединяемой таблице есть несколько строк для одного значения из основной таблицы. Используйте INNER JOIN, если вам нужны только те строки, которые есть в обеих таблицах, что поможет избежать повторов.
- Применение DISTINCT: В случаях, когда возможно дублирование из-за структуры данных, можно использовать ключевое слово DISTINCT для удаления повторяющихся строк. Однако это может снизить производительность, так как требует дополнительной обработки данных. Лучше использовать DISTINCT в сочетании с другими методами оптимизации.
- Группировка данных: Часто дублирование возникает, когда необходимо агрегация данных. В таких случаях можно использовать GROUP BY для группировки результатов и исключения повторных значений. Важно тщательно выбирать поля для группировки, чтобы не потерять нужную информацию.
- Использование подзапросов: Для минимизации дублирования можно использовать подзапросы. Например, если нужно выбрать только уникальные значения из соединенных таблиц, можно предварительно ограничить набор данных с помощью подзапросов, а затем выполнить основной JOIN на уже отфильтрованных данных.
- Использование оконных функций: В некоторых случаях оконные функции, такие как ROW_NUMBER() или RANK(), могут помочь исключить дублирующиеся строки, присваивая им уникальные порядковые номера. Эти функции позволяют фильтровать данные до или после JOIN операции, улучшая качество результатов.
- Оптимизация условий соединения: Часто повторение данных вызвано неправильными или слишком широкими условиями для JOIN. Например, если в соединении используется несколько условий, которые не ограничивают выборку, это может привести к значительному увеличению количества строк. Тщательно проверяйте условия соединений, чтобы они точно отражали нужды запроса.
Также важно обратить внимание на индексацию соединяемых столбцов. Индексы могут существенно ускорить выполнение JOIN операций и уменьшить нагрузку на базу данных, особенно если запросы выполняются часто.
При использовании этих методов важно помнить, что оптимизация всегда зависит от конкретного контекста запроса и структуры данных. Нужно тестировать разные варианты и анализировать их влияние на производительность и корректность результата.
Как правильно применять GROUP BY для уникальности результатов

Оператор GROUP BY используется в SQL для агрегации строк по указанным столбцам, что позволяет получать уникальные значения по определённым критериям. Его правильное применение помогает избежать дублирования данных и повышает точность итоговых результатов.
Прежде всего, важно понимать, что GROUP BY группирует строки, основываясь на значениях в одном или нескольких столбцах. Каждая группа будет содержать уникальные комбинации этих значений. Однако, если в запросе присутствуют столбцы, не включённые в GROUP BY, необходимо использовать агрегатные функции, такие как COUNT, SUM, AVG, MAX, MIN, чтобы избежать ошибок.
Например, если вам нужно вывести уникальные сочетания города и профессии сотрудников с количеством сотрудников в каждой группе, запрос может выглядеть так:
SELECT city, profession, COUNT(*) FROM employees GROUP BY city, profession;
Этот запрос обеспечит уникальные пары города и профессии с количеством сотрудников в каждой группе.
Чтобы гарантировать корректность данных, убедитесь, что GROUP BY применяется только к тем столбцам, которые действительно должны определять уникальность строки. Например, если вы хотите получить список уникальных пользователей по ID, а затем рассчитать их общие заказы, можно использовать следующий запрос:
SELECT user_id, SUM(order_amount) FROM orders GROUP BY user_id;
В этом примере мы группируем заказы по user_id, что позволяет избежать дублирования данных по каждому пользователю и корректно агрегировать суммы заказов.
Кроме того, важно помнить, что GROUP BY не всегда гарантирует уникальность на всех уровнях запроса. Если в запросе присутствуют столбцы, которые не участвуют в группировке и не агрегируются, результат может быть непредсказуемым. Например, если вы выберете столбцы, которые не включены в GROUP BY или агрегатные функции, это приведёт к ошибке выполнения или неправильным результатам.
Правильное использование GROUP BY требует тщательной проверки структуры запроса и понимания того, какие данные должны быть сгруппированы и какие – агрегированы. Такой подход позволяет не только избежать дублирования данных, но и эффективно обрабатывать большие объёмы информации.
Применение оконных функций для выявления и удаления дубликатов
Оконные функции в SQL предоставляют мощные инструменты для работы с данными, включая выявление и удаление дубликатов. Они позволяют эффективно обрабатывать строки, не изменяя их порядка и не требуя дополнительных операций с подзапросами. Применение оконных функций для работы с дубликатами сокращает время выполнения запросов и упрощает их структуру.
Один из распространенных методов удаления дубликатов – использование оконной функции ROW_NUMBER(). Эта функция присваивает каждой строке уникальный номер в пределах окна (группы строк), определенного PARTITION BY и ORDER BY. С ее помощью можно легко выбрать только одну строку из дубликатов.
Пример запроса для удаления дубликатов:
WITH ranked_data AS ( SELECT id, name, ROW_NUMBER() OVER (PARTITION BY name ORDER BY id) AS rn FROM employees ) DELETE FROM employees WHERE id IN ( SELECT id FROM ranked_data WHERE rn > 1 );
В этом запросе для каждой строки, у которой есть дубликаты по имени, присваивается уникальный номер, начиная с 1. Строки с номером больше 1 удаляются, что позволяет оставить только одну уникальную запись для каждого значения в столбце name.
Кроме ROW_NUMBER(), можно использовать другие оконные функции для работы с дубликатами, например RANK() и DENSE_RANK(). Разница между ними заключается в том, что RANK() пропускает номера в случае одинаковых значений, а DENSE_RANK() не пропускает, присваивая одинаковым значениям одинаковые номера, но не нарушая последовательности.
Пример с RANK() для выявления дубликатов:
WITH ranked_data AS ( SELECT id, name, RANK() OVER (PARTITION BY name ORDER BY id) AS rank FROM employees ) SELECT * FROM ranked_data WHERE rank > 1;
Применение оконных функций позволяет минимизировать сложность запросов и улучшить производительность при работе с большими объемами данных. Использование таких функций, как ROW_NUMBER(), RANK() и DENSE_RANK(), значительно упрощает процесс поиска и удаления дубликатов, делая код более понятным и эффективным.
Проверка данных на уровне индексов для предотвращения повторений

В SQL можно создать уникальный индекс с помощью команды CREATE UNIQUE INDEX. Это гарантирует, что в столбце или сочетании столбцов не будет дублирующих значений. Например, если необходимо исключить повторение значений в столбце email, можно использовать следующий запрос:
CREATE UNIQUE INDEX idx_email ON users (email);Такой индекс не позволит вставить строку с уже существующим значением в столбце email, что устраняет возможность дублирования на уровне базы данных. Однако, важно помнить, что создание индекса имеет свои особенности. Например, на таблицах с большим количеством данных это может повлиять на время вставки новых строк, так как индексы нужно будет обновлять при каждом изменении данных.
Для предотвращения повторений можно использовать комбинированные индексы. Это особенно полезно, если необходимо удостовериться, что комбинация нескольких столбцов будет уникальной. Пример создания комбинированного уникального индекса:
CREATE UNIQUE INDEX idx_user_details ON users (first_name, last_name, date_of_birth);Такой подход гарантирует, что комбинация first_name, last_name и date_of_birth будет уникальной для каждой записи, исключая возможность ввода одинаковых пользователей с одинаковыми данными.
Кроме того, при создании уникальных индексов следует учитывать типы данных. Например, индексы на строковых полях могут вести себя по-разному в зависимости от колlation (сравнение строк). Это может привести к неожиданным результатам при проверке уникальности. Лучше заранее определять, какой метод сравнения строк будет использован для индексации.
При использовании индексов важно не только создавать их, но и регулярно анализировать их эффективность. Индексы должны быть оптимизированы, чтобы не создавать избыточную нагрузку на систему. Например, можно использовать команду EXPLAIN для анализа эффективности запросов и понимания, какой индекс используется в каждом случае.
Наконец, помимо предотвращения дублирования, индексы помогают ускорить выполнение запросов с условиями на уникальные данные. Это важно при обработке больших объемов информации, где повторения могут значительно замедлять работу системы.
Использование подзапросов и CTE для очистки данных от дубликатов
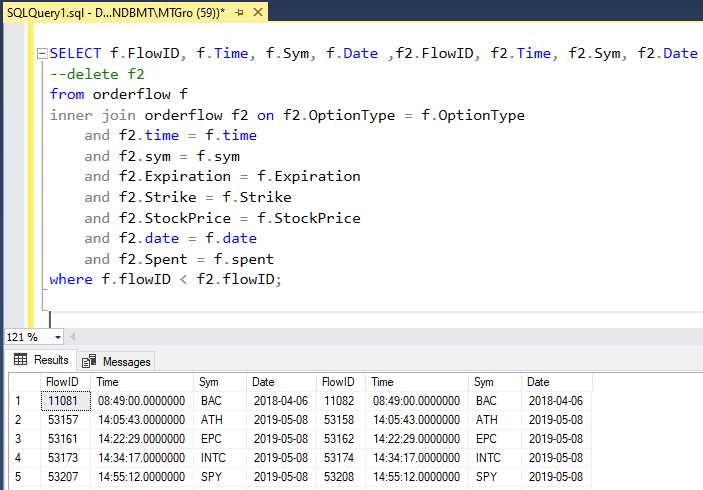
Подзапросы и Common Table Expressions (CTE) – два мощных инструмента для работы с дублирующимися записями в SQL. Оба метода позволяют эффективно очищать данные от повторяющихся элементов, улучшая производительность запросов и снижая нагрузку на сервер.
Подзапросы – это запросы, которые выполняются внутри других запросов. Они могут быть использованы для идентификации дубликатов и выбора уникальных значений. Например, если необходимо выбрать строки, где комбинация нескольких полей дублируется, можно использовать подзапрос для фильтрации этих записей. Пример:
SELECT id, name, value
FROM data_table
WHERE (id, name) NOT IN (
SELECT id, name
FROM data_table
GROUP BY id, name
HAVING COUNT(*) > 1
)В данном примере подзапрос находит все строки с повторяющимися значениями по полям id и name, а основной запрос исключает их из выборки.
CTE (Common Table Expressions) предоставляют более читаемую и гибкую структуру для работы с временными результатами, чем подзапросы. Это особенно важно, когда нужно работать с несколькими уровнями вложенности. Пример использования CTE для очистки данных:
WITH DuplicateRecords AS (
SELECT id, name, COUNT(*) AS cnt
FROM data_table
GROUP BY id, name
HAVING COUNT(*) > 1
)
SELECT id, name
FROM data_table
WHERE (id, name) NOT IN (SELECT id, name FROM DuplicateRecords)В этом примере CTE создает временную таблицу DuplicateRecords, которая содержит все дубликаты. Основной запрос затем исключает их из выборки, что делает запрос более структурированным и легче читаемым.
При использовании подзапросов или CTE важно следить за производительностью, особенно при работе с большими объемами данных. В таких случаях оптимизация запросов и правильное использование индексов может значительно ускорить процесс очистки.
Вопрос-ответ:
Что такое дублирование данных в SQL запросах и почему его нужно избегать?
Дублирование данных в SQL запросах означает наличие одинаковых записей в результате запроса, что может привести к избыточному использованию ресурсов, усложнению анализа данных и нарушению целостности базы данных. Избежать дублирования нужно, чтобы улучшить производительность запросов, снизить нагрузку на систему и повысить точность результатов.
Какие способы существуют для предотвращения дублирования данных в SQL запросах?
Для предотвращения дублирования данных можно использовать несколько методов. Один из них — это применение ключевого слова DISTINCT, которое позволяет выбирать только уникальные записи из таблицы. Также полезно использовать группировку данных с помощью GROUP BY и агрегатных функций, таких как COUNT, SUM, AVG. В некоторых случаях помогает добавление уникальных индексов на таблицы, что автоматически исключает повторяющиеся значения на уровне базы данных.
Когда лучше использовать DISTINCT в SQL запросах, а когда GROUP BY?
Если вам нужно получить только уникальные строки по всему запросу, то лучше использовать DISTINCT. Однако если вы хотите сгруппировать данные по каким-то конкретным столбцам и выполнять агрегатные операции (например, подсчитать количество или найти среднее значение), то предпочтительнее использовать GROUP BY. Например, если нужно посчитать количество заказов по каждому клиенту, лучше применить GROUP BY с функцией COUNT, чем использовать DISTINCT.
Как индексы помогают предотвратить дублирование данных в SQL?
Индексы в SQL помогают ускорить поиск и сортировку данных, а также могут быть использованы для предотвращения дублирования. Например, можно создать уникальный индекс на столбец или набор столбцов, чтобы база данных автоматически проверяла уникальность значений при вставке данных. Это помогает избежать дублирования данных на уровне таблицы и гарантирует, что только уникальные записи могут быть добавлены в базу данных.
Какие ошибки могут возникнуть, если не учитывать дублирование данных в SQL запросах?
Если не учитывать дублирование данных, это может привести к различным проблемам, таким как избыточная нагрузка на базу данных, увеличение времени отклика запросов и потребление больших ресурсов. Также дублирование может искажать результаты отчетности и анализа данных, поскольку они будут основаны на повторяющихся строках. Это может затруднить принятие правильных решений и привести к некорректной интерпретации данных.