Прямое взаимодействие с базами данных через SQL – необходимый навык при разработке любых систем, где важна работа с данными. SQL (Structured Query Language) используется для создания, изменения и извлечения информации из реляционных баз данных, таких как PostgreSQL, MySQL, SQLite и Microsoft SQL Server. Освоение этого языка позволяет не просто выполнять простые запросы, но и оптимизировать хранение и обработку информации на уровне архитектуры проекта.
Для начала работы необходим минимальный набор инструментов: установленная СУБД (например, PostgreSQL) и клиент для работы с запросами (например, DBeaver или pgAdmin). Установка PostgreSQL сопровождается удобным мастером, после чего можно сразу создавать базу данных и пробовать базовые команды: CREATE TABLE, INSERT INTO, SELECT, UPDATE, DELETE.
Практика критически важна. Начните с моделирования простой структуры: таблицы пользователей, заказов или продуктов. Используйте реальные данные – даже десять строк сделают процесс осмысленным. Обратите внимание на типы данных: INTEGER, TEXT, DATE, BOOLEAN – и ограничения, такие как PRIMARY KEY, NOT NULL, UNIQUE. Это фундамент стабильной и безопасной базы.
Следующий шаг – освоение связей между таблицами через FOREIGN KEY и написание JOIN-запросов. Без этого невозможно работать с нормализованными структурами. Начните с INNER JOIN и усложняйте до LEFT JOIN и вложенных подзапросов. Понимание индексов (CREATE INDEX) и их влияние на производительность запросов позволит уверенно работать с большими объемами данных.
Выбор и установка системы управления базами данных (СУБД)
Перед началом работы с SQL необходимо выбрать подходящую СУБД. Конкретный выбор зависит от целей проекта, объёма данных, требований к масштабируемости и доступности.
- PostgreSQL – надёжная объектно-реляционная СУБД с поддержкой расширений (например, PostGIS для геоданных). Отличается строгим соблюдением стандартов SQL и мощной системой типов. Подходит для сложных аналитических задач и веб-приложений.
- MySQL – популярная реляционная СУБД с высокой производительностью. Хорошо работает в сочетании с PHP и широко используется в веб-разработке. Репликация и кластеризация реализованы проще, чем в PostgreSQL, но с меньшими возможностями.
- SQLite – лёгкая встраиваемая СУБД. Используется для локального хранения данных в мобильных и десктопных приложениях. Не требует установки сервера и настройки пользователей.
- Microsoft SQL Server – коммерческая СУБД с хорошей интеграцией в экосистему Windows. Подходит для корпоративных решений. Имеет визуальные инструменты для администрирования (SQL Server Management Studio).
Для установки PostgreSQL:
- Перейдите на официальный сайт https://www.postgresql.org/download/.
- Выберите версию под вашу ОС и загрузите установщик.
- Во время установки задайте суперпользователя (обычно
postgres) и порт (по умолчанию 5432). - После установки откройте pgAdmin или подключитесь через терминал командой
psql -U postgres.
Для начала работы с SQLite:
- Скачайте исполняемый файл
sqlite3с сайта https://sqlite.org/download.html. - Разархивируйте и поместите файл в удобную директорию.
- Запустите SQLite через терминал командой
sqlite3 mydb.sqlite– будет создан файл базы данных и открыт интерфейс командной строки.
Установка MySQL и Microsoft SQL Server может отличаться в зависимости от ОС, но для обеих систем доступны графические установщики и подробные пошаговые инструкции на официальных сайтах.
Создание первой базы данных и таблиц
Откройте SQL-клиент или интерфейс командной строки вашей СУБД. Для примера используем PostgreSQL. Выполните команду:
CREATE DATABASE school;
После создания подключитесь к базе:
\c school
Создадим таблицу для хранения информации о студентах:
CREATE TABLE students (
id SERIAL PRIMARY KEY,
full_name VARCHAR(100) NOT NULL,
birth_date DATE,
email VARCHAR(100) UNIQUE
);
id – автоинкрементируемый первичный ключ. full_name обязательно к заполнению. email должен быть уникальным.
Добавим таблицу с информацией о курсах:
CREATE TABLE courses (
id SERIAL PRIMARY KEY,
title VARCHAR(100) NOT NULL,
description TEXT
);
И создадим связующую таблицу для регистрации студентов на курсы:
CREATE TABLE enrollments (
student_id INTEGER REFERENCES students(id),
course_id INTEGER REFERENCES courses(id),
enrolled_at TIMESTAMP DEFAULT NOW(),
PRIMARY KEY (student_id, course_id)
);
Проверяйте структуру с помощью команды \dt, а описание таблиц – через \d имя_таблицы.
Создание логичных связей и ограничений на этапе проектирования упрощает поддержку и предотвращает ошибки при работе с данными.
Основы SQL-запросов: SELECT, INSERT, UPDATE, DELETE
SELECT используется для извлечения данных. Указываются нужные столбцы, таблица и, при необходимости, условия отбора. Пример: SELECT имя, возраст FROM пользователи WHERE активен = true;. Ключевые конструкции: WHERE – фильтрация, ORDER BY – сортировка, LIMIT – ограничение количества строк.
INSERT добавляет новые строки. Указывается таблица и значения для соответствующих столбцов. Пример: INSERT INTO заказы (клиент_id, сумма) VALUES (5, 1200);. Убедитесь, что значения соответствуют типам данных и что не нарушаются ограничения (например, уникальность).
UPDATE изменяет существующие записи. Указывается таблица, изменяемые поля и условия отбора. Без WHERE обновятся все строки. Пример: UPDATE сотрудники SET должность = ‘менеджер’ WHERE отдел = ‘Продажи’;. Перед выполнением – резервное копирование критично важных данных.
DELETE удаляет строки. Требует осторожности: при отсутствии WHERE очищается вся таблица. Пример: DELETE FROM корзина WHERE дата_добавления < ‘2024-01-01’;. В некоторых СУБД можно использовать RETURNING для возврата удалённых данных.
Перед выполнением любых запросов, изменяющих данные, используйте SELECT с теми же условиями, чтобы убедиться в корректности отбора. Для сложных операций рекомендуется транзакция с возможностью отката.
Типы данных и их использование в SQL
Тип данных определяет, какие значения может принимать поле в таблице и как эти значения хранятся в памяти. Неправильный выбор типа данных приводит к утечке памяти, снижению производительности и ошибкам при обработке данных.
Целочисленные типы используются для хранения чисел без дробной части. Наиболее часто применяются INT (4 байта, диапазон от -2 147 483 648 до 2 147 483 647) и BIGINT (8 байт) для больших значений. Если заранее известен узкий диапазон значений, используйте SMALLINT или TINYINT – это экономит место и ускоряет запросы.
Числа с плавающей точкой – FLOAT и REAL – подходят для приближённых вычислений, но могут давать погрешность. Для финансовых и точных расчетов используйте DECIMAL(p, s), где p – общее количество цифр, s – количество знаков после запятой.
Строковые типы делятся на фиксированные (CHAR(n)) и переменные (VARCHAR(n)). CHAR полезен при строго определённой длине данных, например, кодах стран или идентификаторах. VARCHAR экономит место при разной длине строк, но требует немного большего времени на обработку.
Текстовые данные большого объема хранятся в TEXT. Избегайте его без необходимости – многие СУБД ограничивают использование TEXT в индексах и функциях.
Дата и время обрабатываются с помощью DATE, TIME, DATETIME и TIMESTAMP. DATETIME хранит дату и время без учета часового пояса, TIMESTAMP – с учётом. При хранении логов или событий, где важна временная зона, используйте TIMESTAMP.
Логические значения представлены типом BOOLEAN, но во многих СУБД он реализован через TINYINT(1), где 0 – false, 1 – true. Это важно учитывать при сравнении и экспорте данных.
Выбирайте тип данных не по привычке, а по назначению поля. Это влияет на эффективность индексов, объем хранимой информации и скорость выполнения запросов.
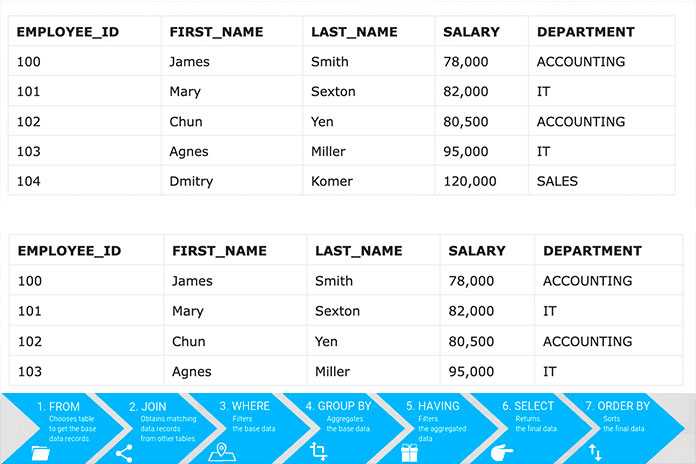
Связи между таблицами и использование JOIN

Связи между таблицами позволяют структурировать данные по принципу нормализации. Основные типы связей: один-к-одному, один-ко-многим и многие-ко-многим. На практике чаще всего используется связь один-ко-многим, реализуемая через внешний ключ (FOREIGN KEY).
Для объединения связанных таблиц применяются операции JOIN. Наиболее часто используются следующие типы:
| Тип JOIN | Описание | Сценарий использования |
|---|---|---|
| INNER JOIN | Возвращает строки, у которых есть совпадения в обеих таблицах | Получение заказов с информацией о пользователе |
| LEFT JOIN | Возвращает все строки из левой таблицы и совпадающие – из правой | Анализ пользователей, вне зависимости от наличия заказов |
| RIGHT JOIN | Все строки из правой таблицы и совпадающие – из левой | Реже используется; аналог LEFT JOIN при изменении порядка таблиц |
| FULL OUTER JOIN | Все строки из обеих таблиц, совпадающие и не совпадающие | Объединение данных с возможными пропусками с обеих сторон |
Для точного соединения необходимо использовать ключевые поля. Пример: SELECT * FROM users u INNER JOIN orders o ON u.id = o.user_id – выбирает пользователей с заказами. При проектировании базы важно следить за консистентностью типов соединяемых полей и индексировать поля, участвующие в JOIN, чтобы избежать деградации производительности при росте объема данных.
Если предполагается множественные связи, рекомендуется применять алиасы и явно указывать, из какой таблицы берётся поле, чтобы избежать неоднозначностей. Использование CTE (Common Table Expressions) может упростить чтение сложных запросов с несколькими JOIN.
Создание индексов и оптимизация запросов
Индексы позволяют ускорить выборку данных из таблиц, особенно при работе с большими объемами информации. Без них даже простые запросы могут потребовать полного сканирования таблицы.
- Создавайте индексы на колонках, которые часто используются в условиях
WHERE,JOIN,ORDER BY,GROUP BY. - Используйте составные индексы, если запросы фильтруют данные по нескольким колонкам одновременно. Порядок колонок в индексе должен соответствовать порядку фильтрации.
- Не создавайте индекс на каждую колонку. Это увеличивает объем хранимых данных и замедляет операции вставки, обновления и удаления.
- Избегайте индексов на колонках с высокой избыточностью (например, булевых), они малоэффективны.
- Регулярно анализируйте использование индексов с помощью
EXPLAIN(в MySQL) илиEXPLAIN ANALYZE(в PostgreSQL).
Оптимизация запросов начинается с понимания плана их выполнения.
- Используйте
EXPLAIN, чтобы выяснить, какие индексы задействуются и сколько строк сканируется. - Формулируйте условия фильтрации так, чтобы можно было использовать индекс. Например,
WHERE column = 'value'предпочтительнееWHERE FUNCTION(column) = 'value'. - Избегайте подзапросов в
WHEREпри наличии возможности переписать запрос сJOIN. - Не выбирайте лишние колонки с
SELECT *. Указывайте только нужные поля. - Используйте лимитирование результатов через
LIMIT, если требуется получить часть выборки.
Для больших таблиц эффективны частичные и покрывающие индексы. В PostgreSQL можно использовать индекс-выражение или индекс по префиксу строки в текстовых колонках. В MySQL InnoDB лучше работает с индексами по первым байтам текстовых полей.
Периодически пересматривайте структуру индексов. Запросы могут измениться, и неиспользуемые индексы только замедляют СУБД. Используйте статистику и логи запросов для анализа реального поведения системы.
Резервное копирование и восстановление данных в SQL
Резервное копирование – критически важная задача при работе с SQL-базами данных. В PostgreSQL для создания бэкапа используется утилита pg_dump. Она позволяет экспортировать отдельную базу данных в файл командой pg_dump -U имя_пользователя -F c -b -v -f файл.backup имя_бд. Для восстановления применяется pg_restore с указанием файла и параметров подключения.
В MySQL резервное копирование осуществляется с помощью mysqldump. Команда mysqldump -u имя_пользователя -p имя_бд > файл.sql сохраняет структуру и данные. Восстановление выполняется через mysql -u имя_пользователя -p имя_бд < файл.sql.
Для Microsoft SQL Server используется BACKUP DATABASE. Пример: BACKUP DATABASE имя_бд TO DISK = 'путь\файл.bak'. Восстановление – через RESTORE DATABASE имя_бд FROM DISK = 'путь\файл.bak' с опциональными параметрами, такими как WITH REPLACE или WITH MOVE.
Плановое резервное копирование должно быть автоматизировано. В Linux удобно использовать cron для запуска скриптов бэкапа. В Windows – Планировщик заданий. Скрипты должны логировать ошибки и поддерживать ротацию файлов, чтобы избежать переполнения диска.
Важно регулярно тестировать восстановление данных. Храните резервные копии на внешних или облачных хранилищах, обеспечьте шифрование и контроль доступа. Наличие бэкапа без проверенной процедуры восстановления – потенциальная точка отказа.
Вопрос-ответ:
С чего лучше всего начать изучение SQL, если я раньше не работал с базами данных?
Начать можно с базовых понятий: что такое база данных, какие бывают типы баз данных и чем они отличаются. После этого стоит познакомиться с понятием реляционной базы данных и языком SQL, который используется для работы с такими системами. Хорошей отправной точкой будет изучение основных команд: SELECT, INSERT, UPDATE, DELETE. Рекомендуется установить бесплатную систему управления базами данных, например, SQLite или MySQL, и практиковаться на простых таблицах.
Какие инструменты нужны для практики работы с SQL на своем компьютере?
Для начала подойдёт любая реляционная СУБД, которую можно установить локально — MySQL, PostgreSQL, SQLite. Также пригодится простой текстовый редактор или специализированная среда, такая как DBeaver или HeidiSQL. Эти инструменты позволяют писать запросы и сразу видеть результат их выполнения. Если нет желания устанавливать программы, можно использовать онлайн-платформы с песочницей, такие как SQLFiddle или DB-Fiddle.
Какой тип задач можно решать с помощью SQL в реальной работе?
SQL часто применяют для анализа данных, составления отчетов, поиска нужной информации в больших массивах данных, автоматизации процессов. Например, можно написать запрос, который покажет всех клиентов, сделавших покупку за последний месяц, или найти самый продаваемый товар по регионам. В компаниях SQL используют аналитики, маркетологи, специалисты по продукту и другие сотрудники, которым нужно работать с данными.
Есть ли смысл учить SQL, если я не программист?
Да, имеет смысл. SQL полезен не только программистам, но и тем, кто работает с данными: аналитикам, менеджерам проектов, специалистам по финансам, маркетингу и логистике. Знание SQL помогает самостоятельно получать нужные данные без обращения к разработчикам, что экономит время и делает работу более самостоятельной.
Сколько времени обычно уходит на освоение основ SQL на базовом уровне?
Если заниматься регулярно, то базовые знания можно получить за 1–2 недели. Это включает в себя понимание структуры таблиц, освоение основных команд и написание простых запросов. Однако, чтобы уверенно чувствовать себя в реальных задачах и работать с более сложными запросами, может потребоваться несколько месяцев практики. Всё зависит от интенсивности занятий и опыта работы с данными в целом.