Поиск подстроки в строках данных – одна из самых часто выполняемых операций при работе с SQL. Важно понимать, какие методы существуют для решения этой задачи и какие из них наиболее эффективны в зависимости от конкретных условий. Некоторые из них требуют использования стандартных функций SQL, другие – более продвинутых операторов и регулярных выражений, что в свою очередь оказывает влияние на производительность запросов.
Операторы LIKE и ILIKE – это базовые инструменты для поиска подстроки в строках в SQL. LIKE позволяет выполнять поиск с учетом или без учета регистра (в зависимости от СУБД). Однако использование LIKE с символами подстановки (например, % или _) может существенно повлиять на производительность, особенно при больших объемах данных. Для более точного поиска по подстроке можно использовать оператор ILIKE в PostgreSQL, который игнорирует регистр символов.
Для более сложных запросов, где требуется поиск по регулярным выражениям, стоит обратить внимание на регулярные выражения в SQL, такие как REGEXP или REGEXP_LIKE. Эти инструменты позволяют значительно повысить гибкость поиска, давая возможность использовать сложные шаблоны для поиска, например, чисел, дат или специфических символов. Однако следует учитывать, что работа с регулярными выражениями может быть ресурсоемкой, особенно при больших объемах данных.
При необходимости оптимизации поиска стоит использовать полнотекстовый поиск. В СУБД, таких как PostgreSQL и MySQL, встроенные функции для полнотекстового поиска обеспечивают более высокую скорость выполнения запросов по сравнению с обычными операторами LIKE или REGEXP, так как эти методы используют индексированные данные.
Использование оператора LIKE для поиска подстроки в SQL

Оператор LIKE в SQL используется для выполнения поиска подстроки в строковых данных. Он поддерживает два основных шаблона: знак процента (%) и подчеркивание (_). Знак процента представляет собой любое количество символов, включая ноль, а подчеркивание обозначает ровно один символ. Эти символы позволяют гибко настраивать запросы для поиска различных сочетаний символов.
Простой пример использования оператора LIKE:
SELECT * FROM employees WHERE name LIKE 'A%';
Этот запрос вернет все записи из таблицы employees, где имя начинается с буквы «A». Оператор LIKE не чувствителен к регистру в большинстве СУБД, однако это можно изменить с помощью дополнительных функций, например, COLLATE.
Чтобы найти строки, содержащие определенную подстроку в любом месте, можно использовать символ процента с обеих сторон:
SELECT * FROM products WHERE description LIKE '%organic%';
Этот запрос найдет все записи, где в описании содержится слово «organic» в любом месте текста. Такое использование оператора LIKE полезно для поиска данных по частичным совпадениям.
Для поиска точного совпадения с одним символом используется подчеркивание. Например:
SELECT * FROM employees WHERE code LIKE '_123';
Здесь запрос вернет все записи, где поле code начинается с любого символа, за которым следуют «123».
Если необходимо исключить записи с определенными символами в начале или конце строки, можно комбинировать операторы LIKE с логическими операторами. Например:
SELECT * FROM customers WHERE email LIKE '%.com';
Этот запрос найдет все электронные адреса, заканчивающиеся на «.com».
Оператор LIKE подходит для работы с небольшими объемами данных, но для больших таблиц может значительно замедлить выполнение запросов, поскольку требует сканирования всех строк. В таких случаях рекомендуется рассматривать использование полнотекстового поиска или других индексов для повышения производительности.
Применение регулярных выражений с помощью оператора REGEXP

Оператор REGEXP в SQL позволяет использовать регулярные выражения для более сложных поисковых запросов в строках. В отличие от простого оператора LIKE, REGEXP даёт возможность задать более гибкие и мощные шаблоны поиска, что значительно расширяет функциональность поиска данных в базе.
Синтаксис оператора REGEXP зависит от СУБД, но основные принципы остаются схожими. Например, в MySQL и PostgreSQL использование REGEXP позволяет искать строки, соответствующие определённым шаблонам, используя стандартные регулярные выражения POSIX.
Регулярные выражения позволяют использовать такие метасимволы, как:
^– начало строки;$– конец строки;.– любой одиночный символ;*– ноль или более повторений предыдущего символа;+– одно или более повторений;[]– набор символов (например,[a-z]для всех строчных латинских букв);|– логическое «или» для альтернативных выражений;?– ноль или одно повторение.
Пример использования REGEXP в SQL-запросе:
SELECT * FROM users WHERE username REGEXP '^admin[0-9]+$';
Этот запрос найдёт всех пользователей, чьи имена начинаются с «admin» и заканчиваются числовой последовательностью (например, «admin123»).
Особенность оператора REGEXP заключается в его чувствительности к регистру (в MySQL по умолчанию поиск регистрозависимый). Для игнорирования регистра можно использовать флаг REGEXP BINARY, либо модификатор i в некоторых СУБД.
REGEXP часто используется для проверки форматов данных, например, для проверки правильности ввода электронной почты или телефонных номеров:
SELECT * FROM users
WHERE email REGEXP '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$';
Этот запрос проверяет корректность формата email адресов.
Для улучшения производительности следует избегать использования регулярных выражений в условиях с большими объёмами данных, так как они требуют больше ресурсов для обработки, чем стандартные операторы LIKE или =. Использование индексов в таких запросах может не дать ожидаемого эффекта, так как регулярные выражения не могут использовать индексы для оптимизации поиска.
Поиск с учетом регистра: использование COLLATE в SQL
Для выполнения поиска с учетом регистра в SQL можно использовать оператор COLLATE. Этот оператор позволяет задать конкретную сортировку и правило сравнения строк для выполнения запросов. В стандартных настройках базы данных часто используется нечувствительное к регистру сравнение, но с помощью COLLATE можно изменить это поведение, чтобы искать строки с учетом регистра.
В SQL существуют различные сортировки, которые могут быть указаны через COLLATE, например, Latin1_General_BIN для двоичного сравнения, которое чувствительно к регистру. Сравнение строк с такой сортировкой учитывает каждый символ, включая регистр, что важно при поиске, где различие в верхнем и нижнем регистре имеет значение.
Пример использования COLLATE для поиска строки с учетом регистра:
SELECT * FROM users WHERE username = 'JohnDoe' COLLATE Latin1_General_BIN;
В данном случае, поиск будет учитывать, что «JohnDoe» и «johndoe» – это разные строки. Это полезно в ситуациях, когда требуется строгое соответствие вводу пользователя или в случае чувствительных данных.
Важно отметить, что использование COLLATE также может быть полезным в различных базах данных с различной локализацией и стандартами сортировки. Например, на некоторых системах используется SQL_Latin1_General_CP1_CI_AS (нечувствительное к регистру), и чтобы изменить это поведение, необходимо явно указать COLLATE с нужной сортировкой.
Еще один вариант применения COLLATE – использование в операторах JOIN, где требуется обеспечить корректное сравнение строк с учетом регистра, например:
SELECT * FROM products p JOIN categories c ON p.category_name = c.category_name COLLATE Latin1_General_BIN;
Таким образом, COLLATE предоставляет гибкость для точного контроля над поведением поиска и сравнения строк в SQL-запросах, что особенно важно для специфических случаев работы с чувствительностью к регистру.
Оптимизация поиска с помощью полнотекстового индекса в MySQL
Полнотекстовый индекс в MySQL значительно ускоряет поиск слов в текстовых данных. Это особенно важно при работе с большими объемами информации, где стандартные операторы сравнения (например, LIKE) не дают должной производительности. Применение полнотекстового индекса позволяет не только ускорить поиск, но и повысить его точность.
Для использования полнотекстового индекса в MySQL необходимо выполнить несколько шагов:
- Создание полнотекстового индекса: Индекс можно создать на колонках типа CHAR, VARCHAR или TEXT. Пример SQL-запроса:
CREATE FULLTEXT INDEX idx_text_search ON articles (title, content);
Этот запрос создаст индекс на колонках title и content таблицы articles, что ускорит поиск по этим полям.
- Поиск с использованием полнотекстового индекса: Для поиска по индексу используется оператор
MATCH() ... AGAINST(). Пример:
SELECT * FROM articles WHERE MATCH(title, content) AGAINST('MySQL оптимизация');
Данный запрос выполнит поиск по полям title и content для слова «MySQL оптимизация» с использованием полнотекстового индекса.
Полнотекстовый поиск позволяет использовать различные опции, такие как:
- Режим Natural Language Search: Это стандартный режим, при котором MySQL анализирует запрос как набор слов с определенной семантикой.
- Режим Boolean Search: При использовании этого режима можно комбинировать запросы с операторами AND, OR и NOT для точной настройки поиска.
- Настройка минимальной длины слов: В MySQL есть параметр
ft_min_word_len, который определяет минимальную длину слова для индексации. По умолчанию это значение равно 4, что означает, что слова длиной менее 4 символов не будут индексироваться. Для изменения этого значения необходимо перезапустить сервер:
SET GLOBAL ft_min_word_len = 3;
После изменения необходимо пересоздать индексы для применения новых настроек.
Для оптимизации производительности полнотекстового поиска следует учитывать несколько аспектов:
- Использование частичных индексов: Если таблица содержит много строк, не всегда требуется индексировать все поля. Лучше создавать полнотекстовый индекс только на тех полях, которые чаще всего используются в запросах.
- Поддержание индекса: Регулярная переработка индекса позволяет предотвратить его разрастание. Это можно делать с помощью команды
OPTIMIZE TABLE, которая дефрагментирует таблицу и индекс. - Рассмотрение альтернатив: Если полнотекстовый поиск не дает нужной производительности, можно рассмотреть использование внешних поисковых систем, таких как Elasticsearch или Sphinx.
Правильная настройка и использование полнотекстовых индексов позволяют добиться значительного увеличения производительности при поиске по текстовым данным в MySQL, особенно в крупных и активно используемых базах данных.
Использование функции INSTR для нахождения позиции подстроки
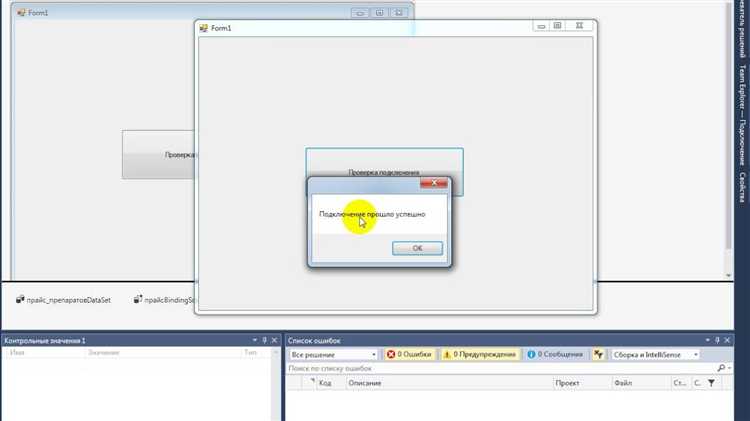
Функция INSTR в SQL используется для нахождения позиции первого вхождения подстроки в строку. Эта функция полезна, когда требуется определить, на какой позиции в строке начинается нужный фрагмент. Если подстрока не найдена, INSTR возвращает 0.
Синтаксис функции INSTR следующий:
INSTR(строка, подстрока [, начальная_позиция [, вхождение]])
где:
- строка – исходная строка для поиска;
- подстрока – фрагмент строки, который ищется;
- начальная_позиция (необязательный параметр) – с какой позиции начинать поиск (по умолчанию 1);
- вхождение (необязательный параметр) – номер вхождения подстроки, которое нужно найти (по умолчанию 1 – первое вхождение).
Пример использования:
SELECT INSTR('Привет мир', 'мир');
Результатом выполнения будет число 8, так как слово «мир» начинается с 8-й позиции в строке «Привет мир».
Если параметр начальной_позиции задан, поиск начинается с указанного индекса строки. Например, чтобы найти второе вхождение подстроки:
SELECT INSTR('abcabcabc', 'abc', 1, 2);
Этот запрос вернет 4, так как второе вхождение «abc» начинается с позиции 4.
Функция INSTR работает с любыми строками, включая те, которые содержат пробелы, специальные символы и другие знаки. Однако стоит помнить, что поиск чувствителен к регистру. Для нечувствительного к регистру поиска можно использовать функцию LOWER или UPPER для приведения обеих строк к одному регистру перед применением INSTR.
INSTR позволяет эффективно работать с текстовыми данными, когда необходимо точно определить расположение подстроки, что может быть полезно в задачах обработки строк и фильтрации данных в SQL-запросах.
Поиск с использованием операторов и функций для работы с JSON в SQL
Современные системы управления базами данных (СУБД) поддерживают работу с данными в формате JSON. SQL предоставляет различные методы для поиска и извлечения данных внутри JSON-структур, что позволяет гибко обрабатывать информацию. Рассмотрим ключевые операторы и функции для поиска данных в JSON в SQL.
Для работы с JSON в SQL используется несколько специфичных операторов и функций, таких как `->`, `->>`, `json_extract`, `json_value`, и другие. Эти инструменты позволяют выбирать и фильтровать данные, хранящиеся в JSON-формате.
1. Операторы для работы с JSON
Оператор `->` используется для извлечения данных в виде JSON-объекта или массива. Он позволяет получить значение, представленное в формате JSON, которое можно использовать для дальнейшего поиска.
Пример использования:
SELECT json_column->'key' FROM table_name;
Оператор `->>` извлекает данные в виде текстового значения. Это полезно, если нужно получить значение, которое не требуется хранить в формате JSON.
Пример использования:
SELECT json_column->>'key' FROM table_name;
2. Функции для поиска внутри JSON
Функция `json_extract()` извлекает данные из JSON-структуры по заданному пути. Это полезно, если необходимо работать с вложенными структурами или искать элементы по специфическим ключам.
Пример использования:
SELECT json_extract(json_column, '$.key.subkey') FROM table_name;
Функция `json_value()` извлекает одно значение из JSON-строки, которое можно использовать для фильтрации данных в запросах. Она позволяет точно определять, какое значение должно быть извлечено из конкретной структуры.
Пример использования:
SELECT json_value(json_column, '$.key') FROM table_name;
3. Поиск по ключам и значениям
В SQL можно выполнять поиск по конкретным ключам JSON-объекта, используя операторы или функции. Например, если требуется найти записи, где значение по ключу равно заданному, можно использовать фильтрацию с функцией `json_value()` или операторами `->` и `->>`.
Пример поиска по ключу:
SELECT * FROM table_name WHERE json_column->>'key' = 'value';
4. Работа с массивами JSON
Для работы с массивами JSON можно использовать функцию `json_array_elements()`, которая позволяет извлекать элементы массива по одному, что полезно для выполнения фильтрации или анализа структуры данных.
Пример использования:
SELECT * FROM json_array_elements(json_column) AS element WHERE element->>'subkey' = 'value';
5. Индексация JSON-данных
Для повышения производительности запросов с использованием JSON-данных важно создать индексы на соответствующие поля. В некоторых СУБД, например, PostgreSQL, существует возможность создания индексов на JSONB-колонки, что ускоряет выполнение операций поиска.
Пример создания индекса на JSONB-колонке:
CREATE INDEX idx_json_column ON table_name USING gin (json_column);
Рекомендуется использовать индексы, если JSON-данные активно используются в запросах, особенно для сложных операций фильтрации.
Заключение
Поиск в JSON-данных SQL позволяет эффективно извлекать и фильтровать информацию внутри сложных структур. Знание операторов и функций, таких как `->`, `->>`, `json_extract()`, `json_value()`, а также использование индексов значительно повышает производительность работы с JSON в SQL.
Как избежать ошибок при поиске в строках с нестандартными символами

При поиске в строках, содержащих нестандартные символы, важно учитывать особенности кодировок и специфику работы SQL с символами. Ошибки могут возникать из-за неправильной обработки спецсимволов или различий в кодировках, что может привести к неверным результатам или даже сбоям. Вот несколько ключевых рекомендаций для правильной работы с такими строками.
1. Использование правильной кодировки. Одной из наиболее частых проблем является несоответствие кодировок между базой данных и приложением. Убедитесь, что кодировка данных в базе (например, UTF-8) совпадает с кодировкой, используемой в приложении. Это особенно важно при работе с символами, выходящими за пределы стандартного ASCII (например, символы кириллицы, эмодзи, или национальные символы). Для обеспечения корректного поиска нужно правильно настроить кодировку соединения с базой данных.
2. Экранирование спецсимволов. В SQL-выражениях некоторые символы (например, %, _, ‘, «) имеют специальное значение и могут привести к ошибкам при их использовании в запросах. Чтобы избежать этого, используйте экранирование с помощью символа обратной косой черты (\) или функции, специфичной для СУБД, например, QUOTENAME() в SQL Server. Это предотвратит интерпретацию символов как управляющих.
3. Использование регулярных выражений. В случае сложных строк с нестандартными символами регулярные выражения могут быть полезным инструментом для поиска. Однако важно помнить, что различные СУБД могут поддерживать разные диалекты регулярных выражений. Например, в MySQL поддержка регулярных выражений ограничена, и они могут не работать с некоторыми символами. В таких случаях лучше использовать функции REGEXP или RLIKE в MySQL или аналогичные функции в других СУБД.
4. Проверка на null-значения. Некоторые символы могут быть интерпретированы как NULL, что приведет к неправильным результатам при поиске. Прежде чем выполнять поиск, необходимо проверить, что строка не является NULL или пустой. Это можно сделать с помощью функций проверки значений, таких как IS NOT NULL или COALESCE().
5. Обработка многобайтовых символов. Если в строках встречаются многобайтовые символы (например, в UTF-8), убедитесь, что индексы и функции поиска учитывают эту специфику. Некорректная обработка многобайтовых символов может привести к ошибочному поиску, если длина строк определяется по количеству байт, а не символов. Важно использовать соответствующие функции для работы с многобайтовыми строками, такие как CHAR_LENGTH() вместо LENGTH() в MySQL.
6. Тестирование с реальными данными. Иногда даже при правильных настройках могут возникать неожиданные ошибки. Поэтому важно проводить тестирование запросов с реальными данными, которые включают нестандартные символы. Это поможет выявить возможные проблемы на этапе разработки, а не в процессе эксплуатации системы.
Анализ скорости поиска: когда использовать подходы с индексацией и без
При работе с большими объемами данных выбор подхода для поиска слова в строке SQL напрямую зависит от того, используется ли индексирование в базе данных или нет. Рассмотрим ключевые различия и ситуации, когда оптимальнее использовать один из этих методов.
Без индексации
Поиск без индексации в SQL может быть эффективен при небольших объемах данных или если запросы выполняются нечасто. Когда таблица содержит несколько тысяч строк, выполнение операций с полными сканированием данных может быть достаточно быстрым. Однако с увеличением объема данных это становится проблемой.
- Неиндексированный поиск выполняется с полным сканированием таблицы, что может сильно замедлить работу при большом числе строк.
- Сканирование данных увеличивает нагрузку на сервер и время ответа, особенно если запросы повторяются часто.
- Для поиска в столбцах с текстовыми данными без индексации SQL может проводить операции, такие как
LIKEилиREGEXP, что значительно замедляет процесс.
Тем не менее, в некоторых случаях можно обойтись без индексации. Например, если нужно выполнить одноразовый запрос к небольшой таблице, добавление индекса может быть нецелесообразным из-за временных затрат на его создание.
С индексацией
Индексация значительно ускоряет поиск в таблицах с большим количеством данных. Индексы позволяют базе данных быстро находить строки, соответствующие запросу, и минимизировать количество проверяемых записей.
- Индексы ускоряют поиск по столбцам, которые часто используются в операциях сравнения (например,
=,>,<). - При наличии индекса на текстовые поля запросы с
LIKEилиILIKEбудут быстрее, так как база данных использует индекс для ограничения диапазона строк, которые должны быть проверены. - Индексация особенно полезна при выполнении частых запросов, таких как фильтрация, сортировка и объединение таблиц.
Однако индексы имеют свои ограничения. Например, создание индекса может быть затратным по времени и ресурсам, а также увеличивает объем хранимых данных. В случае частых изменений данных (вставок, удалений, обновлений) индексы требуют постоянной актуализации, что может привести к снижению производительности.
Когда выбирать подход с индексацией
- Таблицы с большим количеством строк (сотни тысяч и больше).
- Частые операции выборки, особенно если поиск выполняется по одному или нескольким столбцам.
- Необходимость быстрого доступа к данным, особенно в условиях реального времени (например, в системах, где важна скорость отклика).
Когда отказаться от индексации
- Небольшие таблицы, где количество строк не превышает несколько тысяч, а время отклика не критично.
- Необходимость выполнять одноразовые или редкие запросы, когда затраты на создание и поддержку индекса не оправданы.
- Таблицы с высоким уровнем обновлений данных, где индексация может приводить к значительным накладным расходам на поддержание индекса.
Таким образом, выбор между подходом с индексацией и без нее зависит от специфики работы с данными и требований к производительности. Важно помнить, что индексация приносит наибольшую выгоду в случае работы с большими объемами данных, но при этом стоит учитывать ее влияние на время выполнения операций вставки и обновления.
Вопрос-ответ:
Какие способы поиска слова в строке доступны в SQL и чем они отличаются?
В SQL существует несколько способов найти слово в строке. Самый простой — использование оператора `LIKE`, который позволяет задать шаблон поиска, например: `WHERE column_name LIKE ‘%слово%’`. Этот метод чувствителен к регистру в некоторых СУБД и не учитывает морфологию слова. Также есть функция `CHARINDEX` (в T-SQL), которая возвращает позицию слова в строке или 0, если слово не найдено. В PostgreSQL можно использовать `SIMILAR TO` или регулярные выражения (`~`, `~*`). Регулярные выражения позволяют искать более гибкие шаблоны, например слово целиком, без учета подстрок внутри других слов. Различие между методами в точности, скорости и поддержке конкретными СУБД.
Можно ли найти слово без учета регистра букв?
Да, это возможно, но реализация зависит от используемой СУБД. В SQL Server можно привести строку и искомое слово к одному регистру с помощью функции `LOWER()` или `UPPER()` и затем сравнивать: `WHERE LOWER(column_name) LIKE ‘%слово%’`. В PostgreSQL — использовать оператор `ILIKE`, который работает как `LIKE`, но игнорирует регистр: `WHERE column_name ILIKE ‘%слово%’`. В MySQL поведение зависит от настройки коллации — если она нечувствительна к регистру (`ci`), то `LIKE` не различает строчные и прописные буквы.
Как найти слово целиком, чтобы не находились части других слов?
Чтобы искать именно слово, а не его часть, стоит использовать регулярные выражения. Например, в PostgreSQL можно использовать конструкцию `column_name ~ ‘\mслово\M’`, где `\m` и `\M` обозначают границы слова. В других СУБД, где поддержка регулярок ограничена, можно попытаться построить выражение с пробелами или знаками препинания по краям, например: `LIKE ‘% слово %’`, но это менее надёжно и может пропускать случаи в начале и конце строки или при наличии знаков препинания. Регулярные выражения — более точный инструмент для такой задачи.
Какой метод самый быстрый для поиска слова в большом объёме данных?
По скорости лидирует `LIKE`, особенно при использовании фиксированного шаблона и индексов. Однако `LIKE ‘%слово%’` не использует индекс, что замедляет поиск. Чтобы ускорить операции, можно использовать полнотекстовый поиск. В SQL Server — это `CONTAINS`, в PostgreSQL — `to_tsvector` и `to_tsquery`. Эти методы создают специальные индексы и значительно повышают производительность при поиске по большим объемам текста. Они также позволяют искать слово с учетом форм слов и синонимов.
Что делать, если нужно искать сразу несколько слов?
Если нужно найти строки, содержащие одно или несколько слов, можно комбинировать условия. Например: `WHERE column_name LIKE ‘%слово1%’ OR column_name LIKE ‘%слово2%’`. Однако это может быть медленно. Лучше использовать полнотекстовый поиск, если доступен. В PostgreSQL можно использовать `to_tsquery(‘слово1 | слово2’)`, в SQL Server — `CONTAINS(column_name, ‘слово1 OR слово2’)`. Такие запросы быстрее и дают более точные результаты, особенно при работе с длинными текстами.