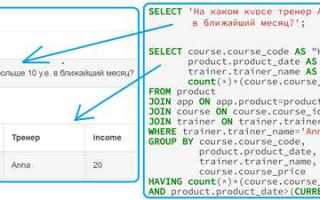
Чтение и модификация данных в реляционных базах невозможны без грамотно составленных SQL-запросов. Даже простая ошибка в синтаксисе может привести к некорректным результатам, потере данных или снижению производительности. Чтобы избежать этого, важно понимать структуру запроса и соблюдать строгую последовательность операторов: SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY.
Ключевое правило: сначала определить, какие именно данные нужны, затем – откуда их взять, и только после этого – какие фильтры или группировки применить. Например, в запросе на выборку всех активных клиентов из таблицы clients с балансом выше 1000, корректный порядок операторов критичен: SELECT name FROM clients WHERE balance > 1000 AND status = ‘active’. Нарушение логики приведёт к синтаксическим ошибкам или неверным результатам.
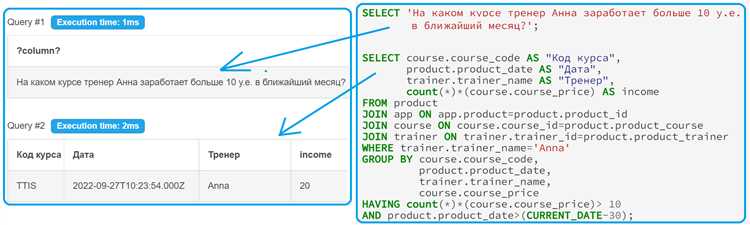
Не менее важно понимать тип возвращаемого результата. Запрос, возвращающий агрегированные данные, требует использования GROUP BY и часто – HAVING вместо WHERE для фильтрации агрегатов. Для подсчёта числа заказов по каждому клиенту пример запроса будет таким: SELECT client_id, COUNT(*) FROM orders GROUP BY client_id. Фильтрация клиентов с более чем 5 заказами: HAVING COUNT(*) > 5.
При написании сложных запросов рекомендуется начинать с подзапросов или использовать CTE (WITH) для повышения читаемости. Это не только упрощает отладку, но и делает код менее подверженным логическим ошибкам при масштабировании. Также следует избегать SELECT * – всегда указывайте нужные поля явно, чтобы снизить нагрузку на базу и повысить предсказуемость результата.
Как выбрать таблицы и поля для запроса
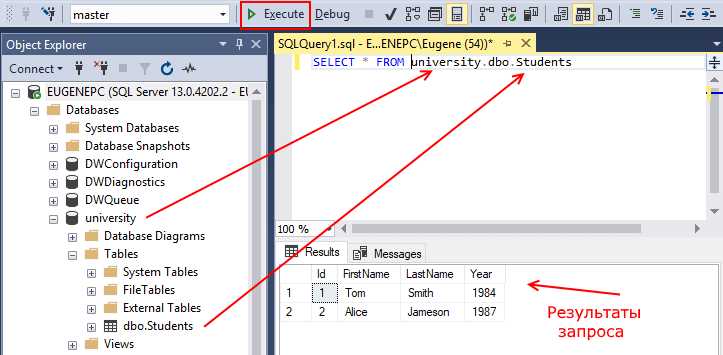
Перед формированием SQL-запроса определите цель: какую информацию нужно получить. Исходя из этого, выберите сущности, с которыми предстоит работать. Например, для получения списка заказов клиентов – таблицы orders и customers.
Проверьте структуру базы данных. Используйте команду DESCRIBE имя_таблицы или обратитесь к документации. Определите, какие таблицы содержат нужные поля, и как они связаны между собой. Обратите внимание на внешние ключи – они подскажут, как объединить данные.
Выбирайте только необходимые поля. Избегайте SELECT *, чтобы не загружать систему лишними данными и упростить чтение результатов. Указывайте конкретные столбцы, например: SELECT customer_name, order_date.
При работе с несколькими таблицами уточните, какие именно поля нужны для объединения. Обычно это ключевые поля, например customer_id в обеих таблицах. Убедитесь, что объединение логично и не создаёт дублирующих строк.
Как использовать операторы WHERE для фильтрации данных

Оператор WHERE применяется для выбора строк, удовлетворяющих заданному условию. Он используется после FROM и до GROUP BY, ORDER BY или LIMIT, если они присутствуют.
Для фильтрации по точному значению используется выражение вида WHERE колонка = значение. Пример: SELECT * FROM сотрудники WHERE отдел = ‘Продажи’ вернёт только сотрудников из отдела продаж.
Чтобы исключить значения, применяется != или <>. Пример: WHERE статус <> ‘Уволен’ выберет всех, кроме уволенных.
Сравнение чисел производится с помощью операторов >, <, >=, <=. Пример: WHERE возраст >= 30 – выборка сотрудников старше 30 лет включительно.
Для проверки вхождения значения в список используется IN. Пример: WHERE должность IN (‘Менеджер’, ‘Аналитик’).
Для поиска по шаблону применяется LIKE. Символ % обозначает любое количество символов. Пример: WHERE имя LIKE ‘А%’ выберет всех, чьи имена начинаются на «А».
Проверка на NULL производится через IS NULL или IS NOT NULL. Пример: WHERE дата_увольнения IS NULL – только сотрудники, ещё работающие в компании.
Сложные условия объединяются с помощью AND и OR. Приоритет операторов регулируется скобками. Пример: WHERE отдел = ‘ИТ’ AND (стаж > 5 OR уровень = ‘Старший’).
Для повышения читаемости используйте отступы и пишите ключевые слова заглавными буквами. Это не влияет на исполнение запроса, но упрощает поддержку кода.
Как применять сортировку с помощью ORDER BY
Ключевое слово ORDER BY применяется для упорядочивания результатов выборки по одному или нескольким столбцам. Сортировка выполняется после фильтрации (WHERE) и агрегации (GROUP BY), но до ограничения количества строк (LIMIT).
- Сортировка по возрастанию выполняется по умолчанию. Пример:
ORDER BY цена. - Для убывающей сортировки используется
DESC:ORDER BY дата_публикации DESC. - Можно сортировать сразу по нескольким столбцам:
ORDER BY категория, цена DESC. В этом случае сначала учитывается порядок категории, затем цена. - Если в выборке используется псевдоним столбца, его можно указывать в
ORDER BY:SELECT сумма_продаж AS итог ORDER BY итог DESC. - Допускается использование позиции столбца в списке SELECT:
ORDER BY 2сортирует по второму столбцу. Такой подход ухудшает читаемость и не рекомендуется. - Сортировка по выражению возможна:
ORDER BY цена * количество. Это полезно для динамических расчетов.
- Старайтесь избегать сортировки по текстовым полям без учета регистра, если важен алфавитный порядок. Используйте
LOWER()илиUPPER(). - Для корректной сортировки дат проверяйте формат хранения: строковое представление может дать некорректный результат.
- Не применяйте
ORDER BYбез необходимости – это замедляет выполнение запроса, особенно при больших объемах данных.
Как объединять таблицы с использованием JOIN
INNER JOIN возвращает строки, где найдено соответствие в обеих таблицах. Используйте его, когда важно получить только связанные данные. Пример: выбор заказов с указанием имени клиента. Убедитесь, что используете индексируемые поля для соединения, например client_id.
LEFT JOIN сохраняет все строки из левой таблицы, даже если в правой нет соответствий. Это удобно для анализа неполных данных, например, клиентов без заказов. В таких случаях не забывайте проверять NULL-значения в полях правой таблицы.
RIGHT JOIN работает аналогично, но приоритет отдается правой таблице. Применяется реже, чаще заменяется LEFT JOIN с перестановкой таблиц.
FULL JOIN объединяет результаты LEFT и RIGHT JOIN, возвращая все строки из обеих таблиц. Используйте, когда нужно сопоставить данные с двух сторон, не теряя несвязанные записи.
CROSS JOIN создаёт декартово произведение – каждая строка первой таблицы сочетается с каждой строкой второй. Применим для генерации комбинаций, но потенциально создаёт большое количество строк. Использовать только при точной необходимости.
Для повышения производительности избегайте использования JOIN с подзапросами без индексации. Оптимизируйте по ключам, используемым в условиях соединения. Явное указание префиксов таблиц (t1.column) избавляет от неоднозначности и повышает читаемость.
При множественных соединениях следите за порядком: сначала INNER JOIN, затем LEFT/RIGHT, в конце FULL или CROSS, если необходимо. Это помогает SQL-оптимизатору сформировать эффективный план выполнения.
Как использовать агрегатные функции: SUM, AVG, COUNT

Функция SUM() используется для подсчёта общей суммы значений в числовом столбце. Например, чтобы получить общую выручку по всем заказам:
SELECT SUM(amount) AS total_revenue FROM orders;AVG() возвращает среднее значение. Часто применяется для анализа средней стоимости, оценки или продолжительности. Чтобы узнать среднюю цену товара:
SELECT AVG(price) AS average_price FROM products;COUNT() определяет количество строк. COUNT(*) считает все строки, COUNT(column) – только те, где значение не NULL. Пример подсчёта всех клиентов:
SELECT COUNT(*) AS total_customers FROM clients;Чтобы агрегатные функции имели смысл, их часто используют с GROUP BY. Пример: подсчитать количество заказов по каждому клиенту:
SELECT client_id, COUNT(*) AS orders_count
FROM orders
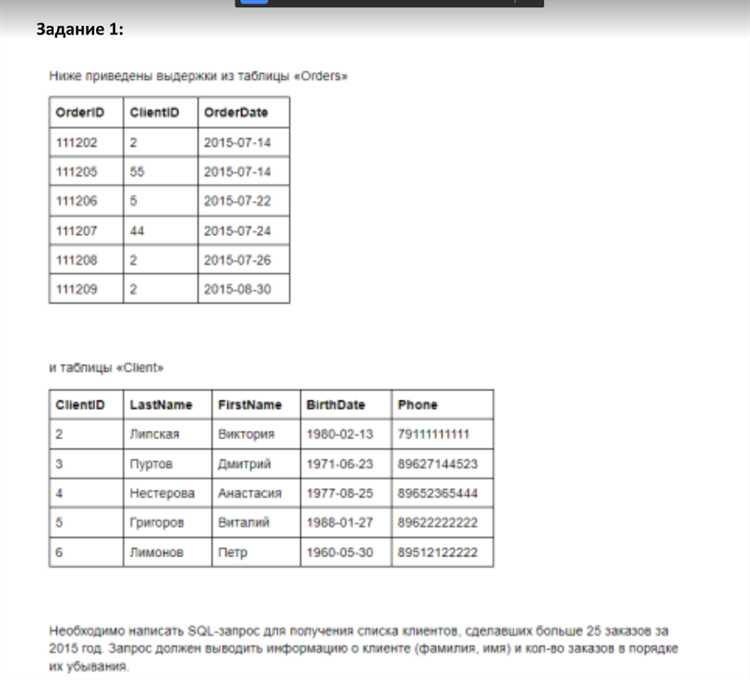
GROUP BY client_id;Если нужно отфильтровать результаты после агрегации, используется HAVING. Пример: вывести клиентов, сделавших больше 5 заказов:
SELECT client_id, COUNT(*) AS orders_count
FROM orders
GROUP BY client_id
HAVING COUNT(*) > 5;Агрегатные функции игнорируют NULL, кроме COUNT(*). Чтобы включить их в анализ, можно использовать COALESCE() или условия CASE. Пример расчёта средней цены с учётом отсутствующих значений:
SELECT AVG(COALESCE(price, 0)) AS adjusted_average FROM products;Как ограничить количество результатов с помощью LIMIT и OFFSET
Ограничение количества возвращаемых строк в SQL-запросах – важная техника для повышения производительности и удобства работы с большими объемами данных. Для этого используются операторы LIMIT и OFFSET, которые позволяют контролировать, сколько строк будет возвращено и с какой позиции начинать выборку.
LIMIT ограничивает количество строк, которые будут возвращены. Например, запрос:
SELECT * FROM users LIMIT 10;
вернет только первые 10 записей из таблицы users.
SELECT * FROM users LIMIT 10 OFFSET 20;
Этот запрос вернет 10 записей, начиная с 21-й строки. Если использовать OFFSET без LIMIT, запрос вернет все строки, начиная с указанной позиции, что может быть неэффективно на больших объемах данных.
Чтобы корректно использовать LIMIT и OFFSET для пагинации, необходимо вычислять OFFSET на основе номера страницы. Например, для отображения 10 записей на странице на странице 3 запрос будет выглядеть так:
SELECT * FROM users LIMIT 10 OFFSET 20;
Где 20 – это результат вычисления (номер страницы — 1) * количество записей на странице.
Не забывайте, что использование LIMIT и OFFSET может ухудшить производительность при работе с большими таблицами, так как база данных должна сначала пропустить нужное количество строк, а затем вернуть остальные. В таких случаях лучше использовать индексы и более сложные механизмы фильтрации.
Вопрос-ответ:
Как правильно выбрать ключевые слова для SQL запроса?
При написании SQL запроса важно правильно выбрать ключевые слова для работы с данными. Первое, что нужно учесть — это тип задачи, которую вы хотите решить. Например, если нужно получить данные из нескольких таблиц, следует использовать оператор JOIN. Если требуется отфильтровать данные по конкретным условиям, стоит использовать WHERE. Ключевые слова SELECT и FROM являются основой, а дополнительное использование операторов LIKE, IN или BETWEEN зависит от условий задачи. Важно помнить, что правильное использование ключевых слов помогает не только получать нужные данные, но и улучшать читаемость запроса.
Что такое нормализация базы данных и как она связана с написанием SQL запросов?
Нормализация базы данных — это процесс организации данных в базе с целью уменьшения избыточности и предотвращения аномалий при обновлении. Это важно для написания правильных и эффективных SQL запросов, так как правильно нормализованная база помогает создавать более простые и логичные запросы. Например, если база данных нормально спроектирована, вы сможете использовать более четкие связи между таблицами, что упростит написание JOIN запросов. Нормализация также способствует улучшению производительности запросов, так как данные распределены по отдельным таблицам, и это снижает нагрузку при выборке данных.
Какие ошибки могут возникать при написании SQL запросов и как их избежать?
При написании SQL запросов могут возникать различные ошибки, такие как синтаксические, логические или ошибки производительности. Наиболее распространенные ошибки — это неправильное использование ключевых слов, забытые операторы или неправильные условия для фильтрации данных. Например, ошибка в операторе WHERE может привести к неверному выбору данных. Чтобы избежать ошибок, важно проверять правильность синтаксиса и логику запроса, а также использовать операторы JOIN для корректной работы с несколькими таблицами. Также не забывайте про индексы, которые могут значительно повысить производительность запросов. Важно тестировать запросы на небольших объемах данных, чтобы убедиться в их правильности.
Как оптимизировать SQL запросы для работы с большими объемами данных?
Оптимизация SQL запросов для работы с большими объемами данных начинается с правильного выбора индексов. Индексы позволяют значительно ускорить поиск данных, поэтому они должны быть созданы на полях, по которым часто выполняются фильтрации или сортировки. Также стоит избегать использования оператора SELECT *, так как это может привести к избыточной выборке данных. Лучше выбирать только те столбцы, которые действительно нужны для решения задачи. Кроме того, стоит избегать использования подзапросов в SELECT и WHERE, так как это может снижать производительность. Разделение запросов на несколько этапов или использование оконных функций (например, ROW_NUMBER) также может помочь оптимизировать работу с большими данными.
Какие функции SQL могут помочь при работе с текстовыми данными?
Для работы с текстовыми данными в SQL существует ряд встроенных функций, которые могут значительно упростить обработку данных. Например, функции для работы с строками, такие как CONCAT (для объединения строк), LENGTH (для определения длины строки) и SUBSTRING (для извлечения части строки), очень полезны при анализе текстовых данных. Также стоит обратить внимание на функции, которые помогают выполнять поиск по шаблонам, например, LIKE или REGEXP. Они позволяют искать текстовые данные, соответствующие определенному шаблону. Важно также использовать функции для преобразования регистра, такие как UPPER и LOWER, если нужно унифицировать данные. С помощью этих функций можно эффективно работать с текстовыми данными и извлекать необходимую информацию.